[ML] 경사하강법 (Gradient Descent method)
경사하강법은 ML, 모델 학습에 있어서 중요한 방법론 중 하나다.
학습에 사용된 코드들을 살펴보면, 항상 경사하강법을 적용해서 뭔가 세팅을 한 것을 볼 수 있을 것이다.
 이게 왜 필요할까?
이게 왜 필요할까?
ML에서는 입력값을 쑤셔넣으면서 학습을 하다보면, 반드시 손실이 발생한다.
A->B 값을 넣는다고 해서 그게 순진하게 들어가는 것이 아닌 것이다.
이 경사하강법이란 것은 학습을 하는데 있어서 손실되는 양을 줄이기 위해서 사용되는 최적화 기법이고,
손실되는 양을 최소화하기 위해서 그 최소값을 찾는 것이라고 할 수 있겠다.
경사하강법에는 몇가지 다른 구현법이 존재하지만 핵심 원리는 비슷하다.
기울기와 손실량 등을 계산해서, 최소값에 가깝게 도달할때까지 파라미터를 업데이트하는 것이다.
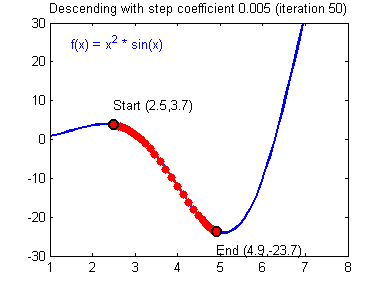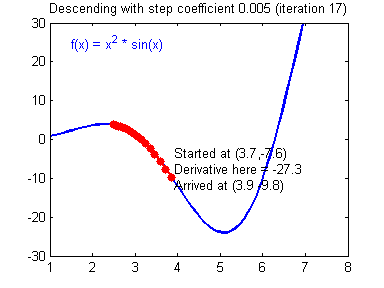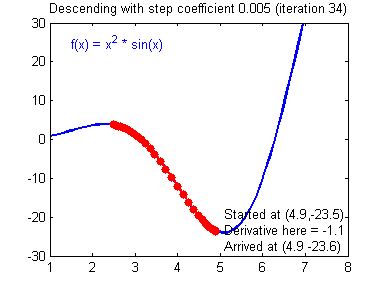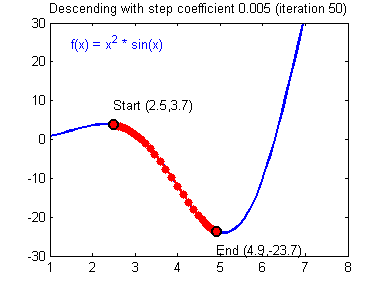 https://hackernoon.com/life-is-gradient-descent-880c60ac1be8
https://hackernoon.com/life-is-gradient-descent-880c60ac1be8
Batch 경사하강법 (Batch gradient descent, BGD)
경사하강법의 가장 기초적인 형태다. 비효율적인 부분이 커서 그대로 사용하진 않는다.
이 방법은 데이터를 하나 넣을때마다, 전체 데이터를 기준으로 기울기를 계산하고 파라미터들을 업데이트한다.
전체 데이터를 다 꺼내서 계산을 한다는 것부터가 대규모 데이터셋에서는 그다지 적절하지 않은 구조다.
실제로 메모리 사용량이 데이터 크기에 비례해서 커지고, 느리다는 단점이 있어서 그대로는 잘 쓰지 않는다.
확률적 경사 하강법(Stochastic gradient descent, SGD)
ML 분야에서 가장 흔하게 사용되는 경사하강법의 구현 방식 중 하나다.
그다지 대단한 구조를 갖는건 아닌데, 하나 넣을때마다 다 꺼내서 계산하는건 무리니까 랜덤으로 하나씩만 뽑아서 계산하자는 것이다.
데이터 목록을 셔플해서 하나를 고르고, 그걸로 기울기를 계산한 다음에 집어넣는다. 이 방법을 반복한다.
그래서 리소스 사용량이 적고 빠른 대신, 노이즈-즉 오차가 많다.
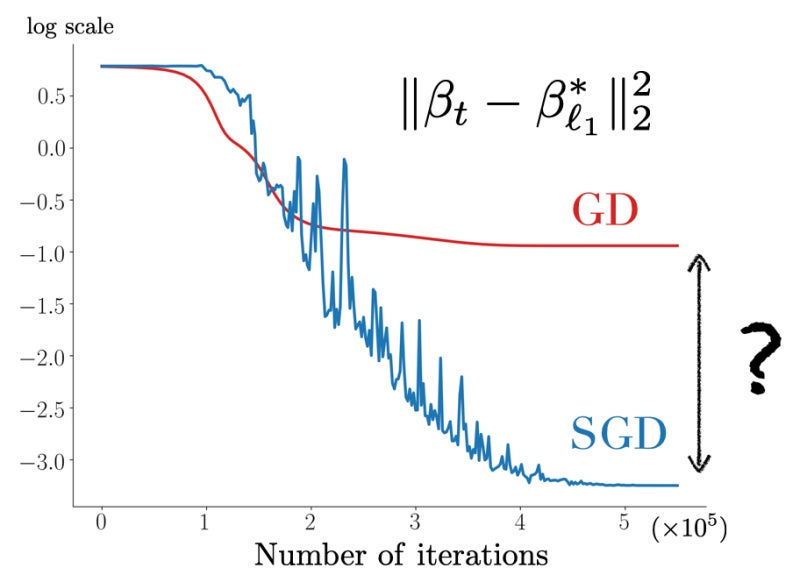 https://francisbach.com/implicit-bias-sgd/
https://francisbach.com/implicit-bias-sgd/
평균값이 매번 바뀌기 때문에 이런 식으로 울퉁불퉁하게 나오고, 실제로 오차도 많이 나올 수 있다.
Mini-Batch 경사하강법(Mini-batch gradient descent, MGD)
BGD와 SGD를 절충한 형태의 기법이다.
여기서는 데이터를 단일 배치가 아닌, 수십개나 수백개 단위를 하나의 미니 배치로 쪼갠다.
그리고 각 배치마다 기울기를 계산하고 파라미터를 업데이트하는 것이다.
그래서 SGD에 비하면 노이즈가 적고, 단일 Batch에 비하면 성능도 괜찮게 나온다는 장점이 있다.
이외에도 Adam, RMSprop, Momentum, AdaGrad 등 다양한 최적화 변형이 있다.
다만 여기서 전부 다루지는 않는다.
참조
https://hackernoon.com/life-is-gradient-descent-880c60ac1be8