파이프라인, 파이프라이닝
 파이프라이닝(Pipelining)은 현대 CPU 구조 및 최적화에 있어서 가장 중요한 부분 중 하나다.
파이프라이닝(Pipelining)은 현대 CPU 구조 및 최적화에 있어서 가장 중요한 부분 중 하나다.
쉽게 말하면, 이어지는 CPU 연산들을 최대한 쉴틈없이 구겨넣어서 빠르게 돌리는 것이다.
실제로 개발자 수준에서 이것을 제어할 필요는 없다. 대부분 컴파일러가 알아서 하고, 사람보다 컴파일러가 더 잘 하는 분야이기 때문이다. 사람이 이거까지 고려하면서 코드를 매번 작성하는 것은 거의 불가능하다.
여기서는 기본적인 얼개와 최적화와 관련된 한계점들에 대해서만 간단히 다루고, 하드웨어적인 부분은 대강 넘어가겠다.
Before Pipeline
파이프라인 기술이 도입되기 전의 CPU들은 아주 순진하게 명령을 처리했다.
덧셈 명령과 뺄셈 명령이 들어오면 덧셈을 다 끝낸 뒤에 뺄셈을 처리하는 식이었다.
1960년대까지만 해도 대부분의 CPU들은 그냥 그렇게 처리했었다.
최초로 파이프라인 개념을 도입한 프로세서는 1964년의 IBM 7030 Stretch다. 초기 연구부터 구현까지를 거의 IBM에서 주도해서 창안했다. 실질적으로 의미있게 사용된 것은 70년대부터이며 그마저도 소수의 슈퍼컴퓨터에만 적용되었다.
실제로 파이프라인 개념이 널리 보급되고 적용된 것은 80년대 이후부터다.
파이프라인의 원리
파이프라인이란, 일종의 CPU 수준 병렬 처리다.
CPU에서 명령어를 처리하는 것은 그냥 딸깍 되는 것처럼 느낄 수도 있지만, 실제로는 복잡한 내부 처리 과정이 존재한다.
명령어를 가져오고(Fetch), 명령어를 해석하고(Decode), 명령어를 실행해서(Execute), 쓰기(Write)까지 해야 하기 때문이다.
파이프라인은 이 명령어 처리 시간을 스텝별로 분리해서 구겨넣고, 단일 clock에서 여러개의 명령을 동시적으로 처리하는 것을 말한다.
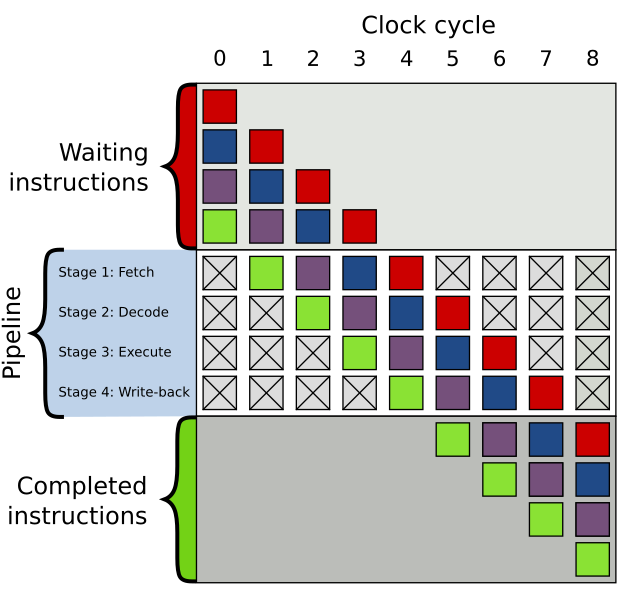 이러면 0번째 명령어 실행을 하는 도중에도 1번, 2번, 3번 명령어를 거의 동시에 우겨넣어서 실행을 할 수 있으니, 거의 4배에 달하는 처리량 최적화를 수행할 수 있는 셈이 된다.
이러면 0번째 명령어 실행을 하는 도중에도 1번, 2번, 3번 명령어를 거의 동시에 우겨넣어서 실행을 할 수 있으니, 거의 4배에 달하는 처리량 최적화를 수행할 수 있는 셈이 된다.
물론 저 그림은 이론의 설명을 위해 지나치게 단순화된 그림이고, 실제로는 이보다 스텝이 많다. 현대 CPU는 대부분 10~20개 사이의 세부 스텝을 가지며, 동시에 10개 넘게 실행을 할 수 있다.
현대 CPU들에서는 이런 파이프라인을 위한 최적화 구조를 슈퍼스칼라(superscalar)라고도 부른다.
인텔에서의 최초 도입 사례는 80960CA, 펜티엄이고, AMD에서의 최초 도입 사례는 29050이다.
요즘 x86 최신 프로세서들은 사이클당 동시 실행 개수가 10개를 넘는다. AMD Zen 5를 기준으로 한다면 사이클당 동시 실행 개수는 14이다.
사족: bubble 처리
가끔 컴파일된 어셈블리를 까보면, nop 같은 쓸데없는 명령이 도배되어있는 것을 볼 수 있다.
이것도 사실 다 원활한 파이프라인을 위해 들어가는 특수 처리라고 할 수 있다.
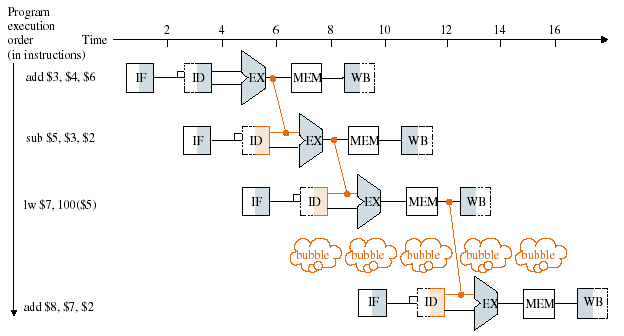
1번 연산, 2번 연산을 순서대로 실행해야 하는데, 2번 연산이 1번 연산의 결과를 사용해야 한다면 어떻게 해야할까?
가장 간단하고 명쾌한 해결책은, 1번이 끝나기를 기다리게 하는 것이다. 그러려면 의미없는 연산을 적당히 필요한만큼 넣어서, 1번이 끝난 뒤에 2번이 실행되게 하면 된다.
 https://stackoverflow.com/questions/42743411/understanding-bubble-vs-stall-vs-repeated-decode-fetch
https://stackoverflow.com/questions/42743411/understanding-bubble-vs-stall-vs-repeated-decode-fetch
이러한 접근법을 bubble이라고 한다.
x86 instruction에는 nop라는 아무것도 하지 않는 연산이 있는데, 이건 정말 아무것도 하지 않고 1 사이클을 소모한다. 딱 한텀 기다리는 것이다.
이것도 컴파일러가 알아서 해주는 부분이기 때문에, 리버싱할때를 제외하고는 신경쓸 일이 없다.
문제: Out of Order
파이프라이닝을 적용할 때 전제조건 중 하나는, 연산 순서를 제멋대로 조작할 수 있다는 것이다.
생각해보자. 3번째 연산이 2번째 연산의 결과를 바탕으로 연산을 해야 한다면 애초에 미리 명령어를 밀어넣어서 병렬화를 하는 것이 불가능하다.
그래서 이럴 때 일반적인 컴파일러들은 3번째 연산의 실행을 나중으로 미루고, 의존관계가 없는 뒤의 4번째, 5번째 연산을 먼저 실행되게끔 하기도 한다. 한개라도 더 빨리빨리 넣어야 파이프라인 최적화 본연의 목적을 달성할 수 있는 것이기 때문이다.
물론 컴파일러는 연산의 순서를 뒤섞더라도, 최종 결과를 망가뜨리지 않는 선에서만 한다.
그렇다고 문제가 없는 것은 아니다. 컴파일러가 순서를 뒤섞어도 된다고 판단하는 기준은 "싱글 스레드"에서의 결과 보장이다. 멀티스레드 환경에서는 망가질 수 있다.
이 파이프라이닝을 위한 순서 뒤섞기 최적화는 실제로 멀티스레드 개발에서 매우 자주 일어나는 버그의 원인 중 하나다.
https://blog.naver.com/sssang97/223356930725
문제: branch
덧셈이나 뺄셈 같은 선형적인 연산들의 경우에는, 컴파일러가 순서를 파악하고 조절해서 파이프라인에 계속 밀어넣는 것이 매우 쉽다. 이런 경우들에는 파이프라인 최적화가 굉장히 잘 된다.
문제는 If/Else 같은 제어 연산이 들어갈 경우다.
이런 분기 연산은 값에 따라서 다음 명령이 달라지다보니, 뭘 그 다음 명령으로 올려야할지 확실하게 알 수가 없다.
그래서 현대 CPU는 대부분 "추측"을 통해서 분기 다음 명령어를 로드해서 처리하고 시도한다. 이를 분기 예측(branch prediction)이라고 부른다.
문제는 이 추측이 맞는다면 깔끔하게 잘 돌아가겠지만, 추측이 실패한다면 성능이 망가질 수 있다는 것이다.
예를 들어 A 분기를 탈줄 알고 A의 명령어를 다 파이프라인에 올렸다가, 실제로 B 분기를 타버리면, 기존에 로드한 명령어를 다 버리고 다시 로드해야 하는 것이다.
그러니까 최신 프로세서 기준으로는 예측에 실패할 때마다 최소 10개 정도의 명령어 실행을 손해본다.
그래서 If/Else 같은 제어구문이 복잡하게 들어있는 프로그램은 그렇지 않은 프로그램에 비해 실행성능이 떨어질 수 있고, 현재 기술 수준으로는 완벽하게 해결할 수 없는 한계점이 명확하게 존재한다.
https://m.blog.naver.com/sssang97/223942222903
참조
https://en.wikipedia.org/wiki/Instruction_pipelining
https://velog.io/@kio0207/%EC%BB%B4%ED%93%A8%ED%84%B0%EA%B5%AC%EC%A1%B0-%ED%8C%8C%EC%9D%B4%ED%94%84%EB%9D%BC%EC%9D%B4%EB%8B%9D