[PostgreSQL] 인덱스 최적화: 복잡한 필터 조건
PostgreSQL을 포함한 RDB들은 전반적으로 유능하지만, 태생적인 한계로 잘 하지 못하는 부분도 있다.
그 중 대표적인 종류 중 하나가 매우 복잡한 형태의 필터를 최적화하기가 좀 어렵다는 것이다.
필터 표현식이 복잡하지만, 복합 필터 조건이 어느 정도 정해져있다면 문제가 되진 않는다.
그런 경우에는 커버링 인덱스를 통해 잘 최적화할 수 있다.
https://blog.naver.com/sssang97/223828946151
문제는 이런 경우다.
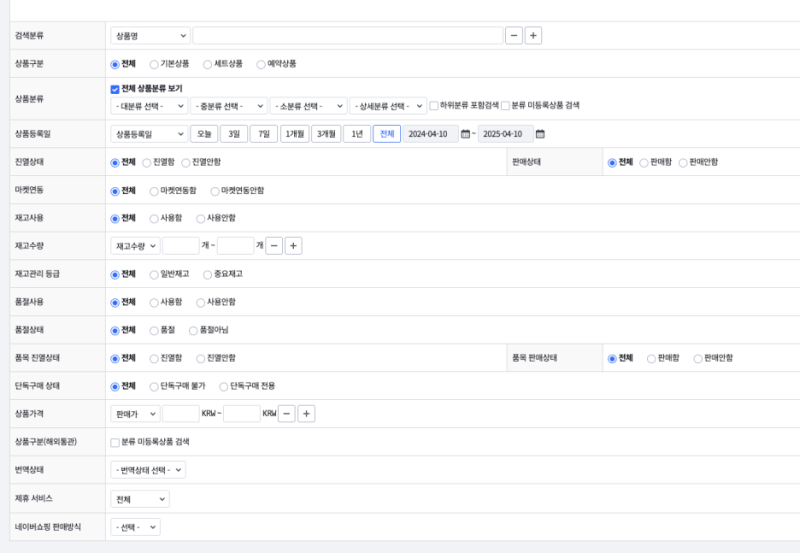
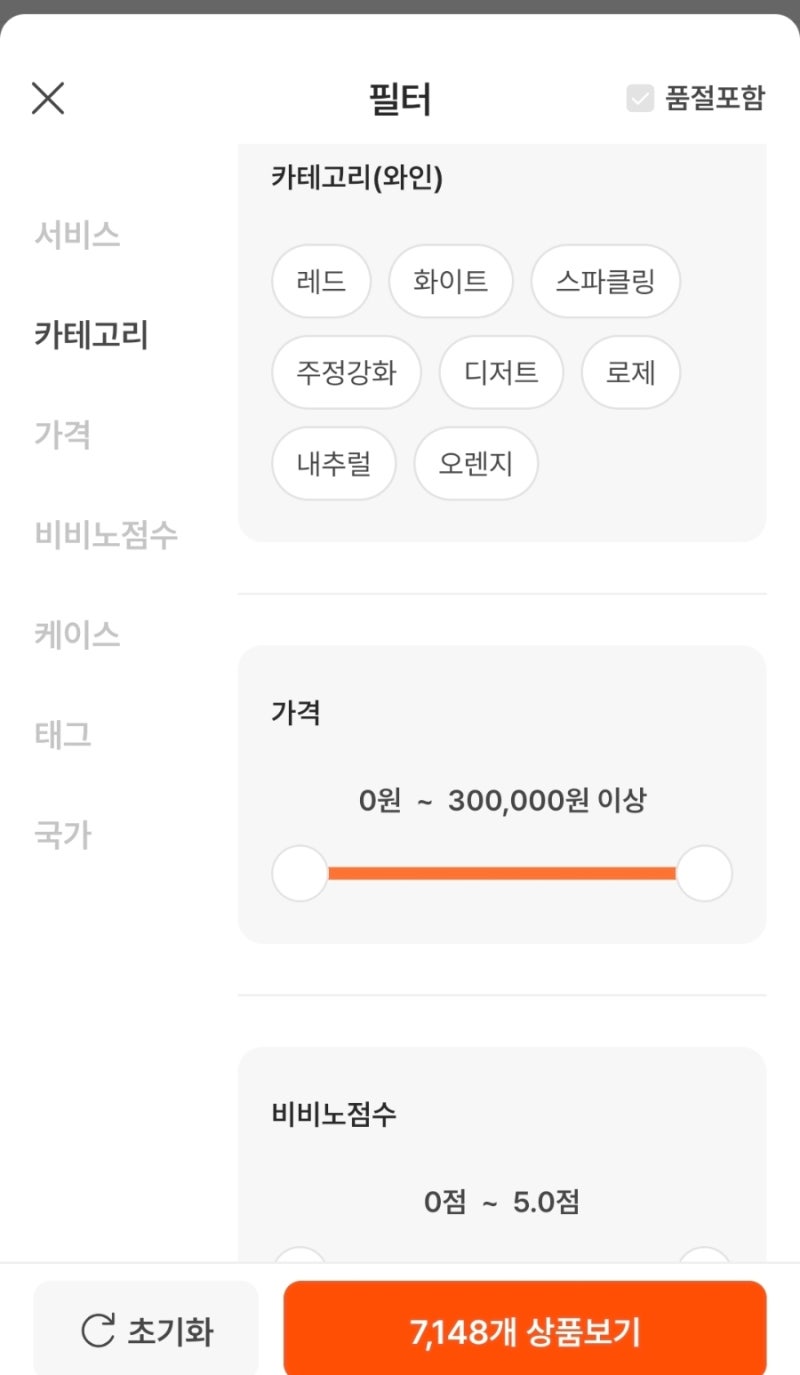 필터 조건 조합의 경우의 수가 매우 많은 경우. 그리고 각 필터의 카디널리티가 낮은 경우.
필터 조건 조합의 경우의 수가 매우 많은 경우. 그리고 각 필터의 카디널리티가 낮은 경우.
그러면서 데이터 규모가 N백만개나 N천만개를 넘어서는 경우. 이런 경우에는 이상적인 최적화가 매우 어렵다.
커버링 인덱스를 모든 조합마다 거는 것이 사실상 불가능하기 때문이다.
커버링 인덱스는 컬럼의 순서와 실제 데이터 분포도가 매우 중요한데, 저런 다이나믹한 필터 조합을 대응하려면 모든 분포를 고려해서 모든 가능한 스캔 조합을 다 인덱스로 구성해야 한다.
다 파악해서 만드는 것 자체도 거의 불가능에 가깝고, 만든다고 치더라도 인덱스는 공짜가 아니다. 그만큼 사용량을 갉아먹는 것이다.
그래도 데이터 분포에 따라서, 단일 컬럼 인덱스를 개별적으로 걸어도 인덱스를 좀 활용하긴 한다.
DB가 인덱스 활용을 어떻게 하는지 실험을 기반으로 훓어보도록 하겠다.
데이터 세팅
먼저 테이블 하나 만들고, 1000만개 정도만 데이터를 깔았다.
CREATE TABLE benchmark (
id BIGSERIAL PRIMARY KEY,
a BIGINT NOT NULL,
b BIGINT NOT NULL,
c BIGINT NOT NULL,
d BIGINT NOT NULL,
e BIGINT NOT NULL,
f BIGINT NOT NULL
);
INSERT INTO benchmark (a, b, c, d, e, f)
SELECT
(random() * 1000000)::INTEGER as a,
(random() * 1000000)::INTEGER as b,
(random() * 10000)::INTEGER as c,
(random() * 10000)::INTEGER as d,
(random() * 100)::INTEGER as e,
(random() * 100)::INTEGER as f
FROM
generate_series(1, 10000000) AS t;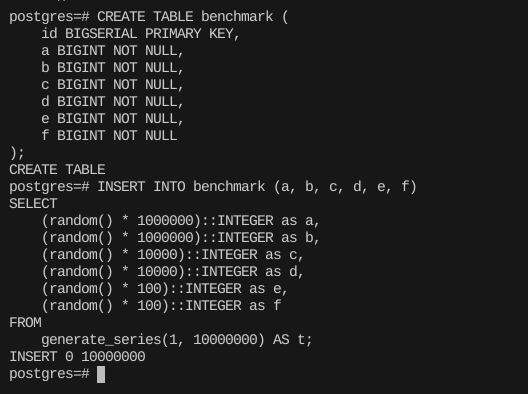 일부러 값의 분포로를 3가지로 분리했다.
일부러 값의 분포로를 3가지로 분리했다.
정수만 넣어놨다보니 테이블 크기가 기본적으로 작아서, 성능이나 인덱스를 타는 정도는 실제 환경과 많이 다를 수 있다. 보통은 문자열도 잔뜩 들어가고 비대해지기 때문에 이것보다는 훨씬 무거울 것이다.
create index idx_a on benchmark(a);
create index idx_b on benchmark(b);
create index idx_c on benchmark(c);
create index idx_d on benchmark(d);
create index idx_e on benchmark(e);
create index idx_f on benchmark(f);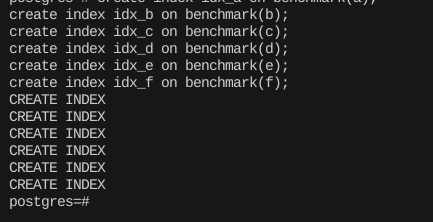 그리고 각 개별 컬럼마다 인덱스를 만들어줬다.
그리고 각 개별 컬럼마다 인덱스를 만들어줬다.
실험
자, 그럼 어떻게 동작하는지 보자.
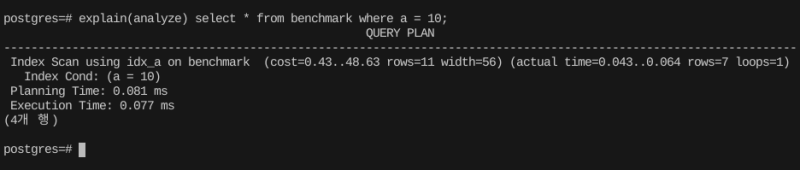
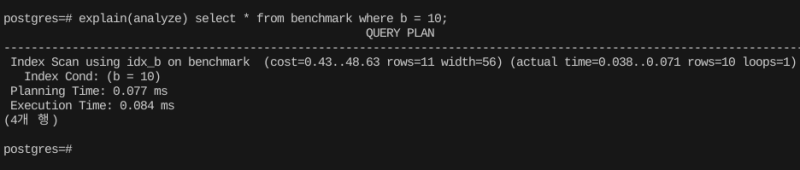 당연히 개별 컬럼에 대한 단순 조건식은 인덱스를 바로 잘 탄다.
당연히 개별 컬럼에 대한 단순 조건식은 인덱스를 바로 잘 탄다.
그럼 2개 컬럼 조건을 동시에 걸면 어떻게 할까?
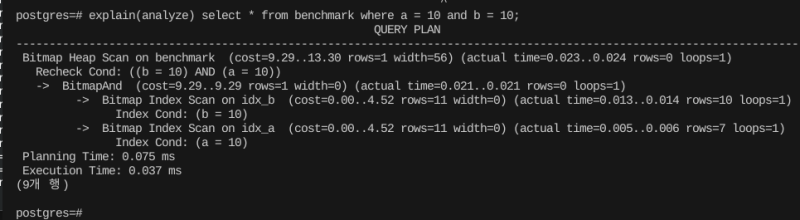 그래도 인덱스를 타긴 탄다.
그래도 인덱스를 타긴 탄다.
각 조건마다 인덱스를 태워서 가져온 뒤에, 그걸 잘 병합해서 처리를 하는 것이다.
코스트가 약간 늘어나긴 하지만, 그래도 여전히 인덱스를 잘 활용한다.
아직은 이상적인 인덱스 사용 형태라고 할 수 있다.
그럼 이번에는 값의 중복성이 높은 필드에 대해 넓은 범위의 복합 필터를 걸어보겠다.
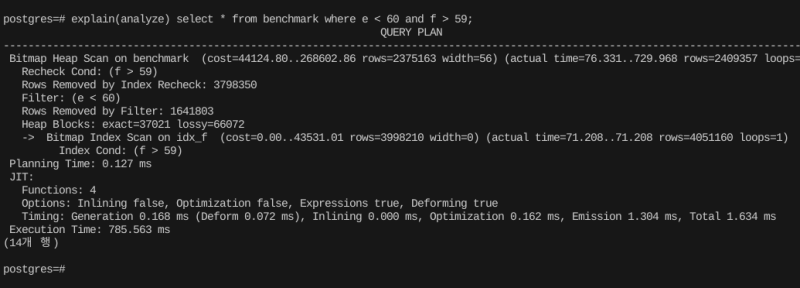 안타깝게도, 인덱스를 아주 잘 타진 않았다.
안타깝게도, 인덱스를 아주 잘 타진 않았다.
f > 59 조건으로 가져오게 되는 데이터의 크기가 너무 크다고 판단해서, e < 30 인덱스로 전부 가져온 다음에 후처리로 필터링을 하는 식으로 동작했다.
일반적인 조회에서 700ms면 매우 느린 것이다.
내 하드웨어 스펙이 괜찮고 사용량도 당장 없어서 저렇게 나온거지, 실제 사용사례였다면 Disk I/O나 CPU 병목으로 처리량에 문제가 생길 확률이 높다.
게다가 실제 사용사례에서는 필터가 이것보다도 더 복잡하게 걸리게 될 확률이 높다.
여기에다 정렬이나 페이지네이션, Join 등까지 들어가면 아사리판이 나는 것이다.
그래서
사실 이 문제에 대한 명쾌한 해결책은 없다.
파티션을 잡고 기능을 제약해서 파티션 단위 풀스캔을 때리게 하든지, 그냥 조건을 단순화한다든지...
요즘 사용하는 일반적인 해결 방안은, Elasticsearch 같은 Column Base DB를 사용하는 것이다.
이런 DB들은 다른 것들을 희생한 대신 복잡한 필터 조건 등에 최적화된 성능을 보여준다.