데이터베이스별 쓰기 처리량 벤치마크
궁금해서 벤치마크 한번 돌려봤다.
보통 흔히들 RDB가 비교적 쓰기가 느리고, NoSQL들이 쓰기 처리량이 높다고 한다. 하지만 대부분 그 상세가 어느 정도인지는 잘 모를 것이다.
그래서 얼마나 드라마틱하게 차이가 나는지 1000만개 정도만 때려넣어서 한번 확인을 해보려 한다.
1000만개를 다 넣는데 얼마나 걸리는지, 실패율은 얼마나 되는지, 디스크 사용량, 메모리 사용랑, CPU 사용량까지를 함께 볼 수 있을 것 같다.
벤치마크 대상은, 오픈소스 데이터베이스 중에서 1차 저장소로 사용되는 것들이다.
PostgreSQL, MySQL, MariaDB, MongoDB, InfluxDB, TimescaleDB, CassandraDB, ScyllaDB, CouchDB, YugabyteDB, CockroachDB.
최적화나 옵션 조정을 얼마냐 하느냐에 따라서 성능이 많이 달라지겠지만, 최대한 기본 구성에 맞춰서 돌렸다.
Batch Write가 권장사항인 시스템들도 다 하나씩 넣었다. 모아서 넣으면 빨라지는걸 누가 모르는가?
테스트에 사용한 프로세서는 라이젠9 7900. SSD. 리소스는 도커 기준으로 코어 4개, RAM 8gb로 제약했다.
벤치마크에 사용한 전체 코드 & 세팅은 깃헙에 있다.
https://github.com/myyrakle/benchmarks/tree/master/database_write_performance
데이터 세팅
무작위의 key-value 값을 1000만개 정도만 준비했다.
키는 uuid v4, 값은 무작위의 20-200 길이 사이의 랜덤 문자열.
 이렇게다.
이렇게다.
저걸 이제 한번 때려넣어보겠다.
 최대 동시 실행 제한은 10000개 정도로만 잡았다.
최대 동시 실행 제한은 10000개 정도로만 잡았다.
어차피 이거 더 늘린다고 해서 처리량이 느는 것 같진 않더라.
PostgreSQL
든든한 국밥인 PostgreSQL부터 해보겠다.
아무래도 RDB들은 커넥션 제한이 좀 있다보니까, 적절한 권장치 즈음인 1000으로 잡았다.
 때려넣기 시작하면
때려넣기 시작하면
 당연히 CPU와 메모리가 치는데, 2-3GB를 넘지는 않았다.
당연히 CPU와 메모리가 치는데, 2-3GB를 넘지는 않았다.
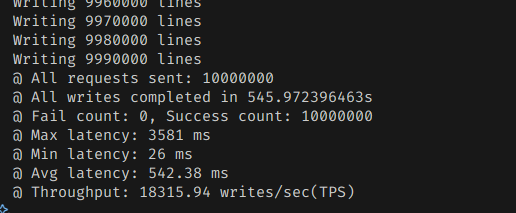 1000만개 넣는데 545초 정도가 걸렸다. 1초에 18000개 정도를 넣을 수 있었다는 것이다.
1000만개 넣는데 545초 정도가 걸렸다. 1초에 18000개 정도를 넣을 수 있었다는 것이다.
 디스크 사용량은 3.7기가 정도.
디스크 사용량은 3.7기가 정도.
MySQL
MySQL은 어떨까? 사실 예전부터 write 성능은 MySQL이 더 좋다는 이야기를 들어봤었는데, 얼마나 차이가 나는지 궁금했다.
 때려넣을 때의 메모리 사용량 피크는 비교적 적었고
때려넣을 때의 메모리 사용량 피크는 비교적 적었고
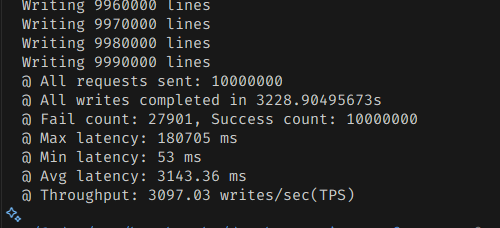 생각보다 느렸다.
생각보다 느렸다.
3200초 정도가 걸렸다. 처리량은 초당 3000건 정도.
미세조정을 하면 더 최적화할 여지가 있을지도 모르지만, 기본 설정에서는 이 정도인 것 같다.
 디스크 사용량은 postgres 대비해서 상당히 비대한 편이다. 2배는 크다. 어디서 차이가 나는거지?
디스크 사용량은 postgres 대비해서 상당히 비대한 편이다. 2배는 크다. 어디서 차이가 나는거지?
 평상시의 메모리 기본 점유량도 mysql이 좀 더 큰듯하다.
평상시의 메모리 기본 점유량도 mysql이 좀 더 큰듯하다.
MariaDB
좀 다를까 싶어서 MariaDB도 돌려봤다.
지금은 별도 관리긴 하지만 원본 포크라서 거의 비슷할 것으로 예상헀다.
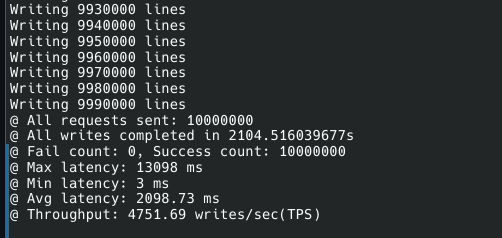
 확실히 개선이 되긴 한 것 같다.
확실히 개선이 되긴 한 것 같다.
처리속도도 더 빨라졌고, 디스크 사용량도 컴팩트해졌다.
MongoDB
이번에는 NoSQL 신드롬을 불러온 DB인 mongoDB다.
이건 RDB와 NoSQL 사이의 어정쩡한 지점을 잡고 있다.

 쓰기가 몰릴 때의 메모리 피크는 약간 더 높은 편이고
쓰기가 몰릴 때의 메모리 피크는 약간 더 높은 편이고
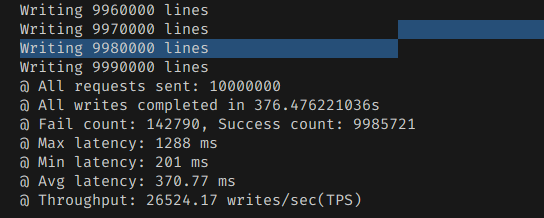 처리속도가 확실히 RDB에 비해 다소 빠르긴 했다.
처리속도가 확실히 RDB에 비해 다소 빠르긴 했다.
총 376초니까 초당 처리량이 26000건이 된 것이다. RDB에 비하면 최소 1.5배는 빠른 셈이긴 하다.
 디스크 사용량은 무난한 편이다. PostgreSQL과 비슷하다.
디스크 사용량은 무난한 편이다. PostgreSQL과 비슷하다.
CassandraDB
CassandraDB는 빅데이터급 데이터를 핸들링하기 위한 목적의 분산 DB다.
그래서 일반적으로 쓰기 성능도 매우 높다고 알려져있다.

 아무래도 JVM 베이스다보니 메모리 사용량은 높은 편이다. 많이 튄다.
아무래도 JVM 베이스다보니 메모리 사용량은 높은 편이다. 많이 튄다.
하지만 잃은게 많은 만큼 얻은 것도 확실히 있다.
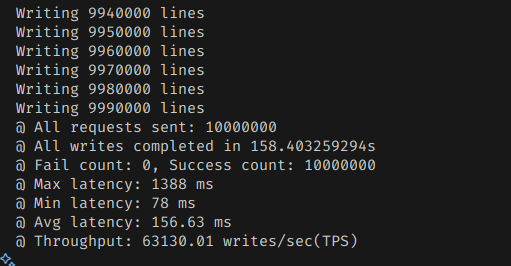 1000만개를 밀어넣는데 158초밖에 걸리지 않았다.
1000만개를 밀어넣는데 158초밖에 걸리지 않았다.
1초에 63000개를 처리할 수 있었던 것이다.
 디스크 사용량은 매우 컴팩트한 편이다.
디스크 사용량은 매우 컴팩트한 편이다.
ScyllaDB
ScyllaDB는 CassadraDB와 프로토콜 수준에서 호환되는 대체재다.
카산드라의 짜증나는 JVM 수준 관리 부담 때문에 많이 선호되는 녀석이다.

 일단 카산드라에 비해서는 비교적 메모리를 덜 먹긴 한다.
일단 카산드라에 비해서는 비교적 메모리를 덜 먹긴 한다.
하지만 이것도 다른 DB에 비해서는 많이 먹는 편이긴 하다.
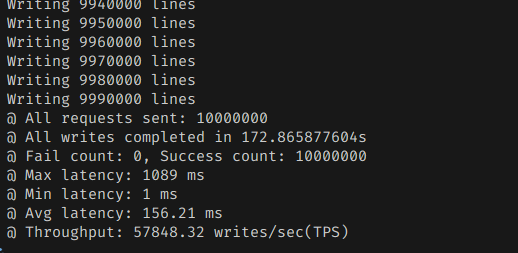 처리속도는 Cassandra보다는 조금 떨어지긴 했다. JVM의 메모리 재사용 능력과 JIT의 힘이 성능에 유의미한 지점이 크긴 한다보다.
처리속도는 Cassandra보다는 조금 떨어지긴 했다. JVM의 메모리 재사용 능력과 JIT의 힘이 성능에 유의미한 지점이 크긴 한다보다.
그래도 레이턴시 자체는 더 완만하고 안정적이다. GC의 부재에서 오는 것 같다.
 디스크는 좀 많이 큰 편이다.
디스크는 좀 많이 큰 편이다.
찾아보니까 최신 CassandraDB는 3.0 저장 포맷을 쓰는데, ScyllaDB는 2.*대 구식 포맷을 써서 좀 효율성이 떨어지는 지점이 있다고 한다.
InfluxDB (v2)
시계열 DB의 원조 중 하나다.
시간 기준의 데이터를 빠르게 쌓고, 빠르게 분석할 수 있는 기능을 제공한다.
캐치프레이즈로 내세우던게 높은 쓰기 처리량이라서 높은 수치를 좀 기대했었다.
 리소스는 적당히 먹고
리소스는 적당히 먹고
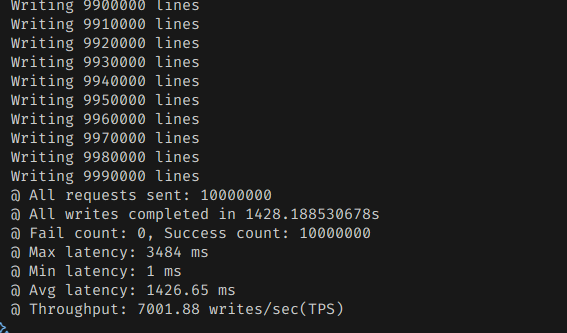 속도는 생각보다 상당히 느렸다.
속도는 생각보다 상당히 느렸다.
1400초가 걸렸고, 1초에 7000개 정도밖에 처리하지 못한 것이다.
PostgreSQL과 비교해서도 현저히 느린 처리량이다.
이것도 뭐 배치 처리하고 최적화할거 하면 좀 빨라질 수는 있겠지만, 기본 성능은 이 정도인 것 같다.
 그래도 디스크 사용량은 아주 컴팩트한 편이었다.
그래도 디스크 사용량은 아주 컴팩트한 편이었다.
TimescaleDB
TimescaleDB는 PostgreSQL 기반 위에 쌓아올린 시계열 플러그인이다.
당연히 PostgreSQL과 성능이 비슷할 것이라고 기대하고 돌려봤다.


 메모리는 순정보다는 조금 많이 먹는다.
메모리는 순정보다는 조금 많이 먹는다.
시간값 기준으로 뭐 이것저것 세팅하는게 있어서 그런거같다.
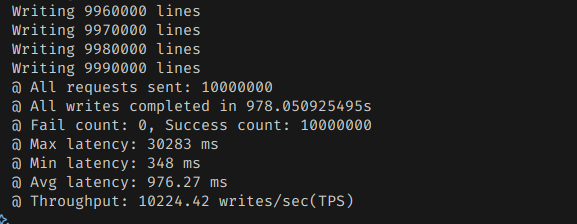
 디스크 사용 효율은 좀 많이 구리다.
디스크 사용 효율은 좀 많이 구리다.
Prometheus (장외패)
빨리 들어가는가 했더니, 프로메테우스 특유의 구조 때문에 메모리를 미친듯이 폭식하다가 OOM으로 터져버렸다.
prometheus 모든 필드를 통계용으로 세팅하기 때문에 필드별 카디널리티가 높을수록 메모리를 남용한다.
지금 데이터셋에서는 key/value가 거의 유일한 분포를 가지니까, 터지는게 당연하다.
프로메테우스에는 단순 메타데이터로 값을 구겨넣을 공간도 없어서 뭐 어떻게 할 도리가 없더라.
CouchDB
CouchDB는 쓰기 위주의 확장에 최적화된 분산 데이터베이스다.
존재감이 매우 없는 편인데, 또 은근히 쓰는 사람들이 꽤 된다.
schemaless형 documentDB라서 mongoDB와 입지가 많이 겹친다.
한번 때려봤다.


 리소스 사용량 자체는 적은 편인가 싶었는데... 뒤로 갈수록 미친듯이 폭식을 하더라. 그러다가 OOM으로 터졌다 살아났다를 반복했다.
리소스 사용량 자체는 적은 편인가 싶었는데... 뒤로 갈수록 미친듯이 폭식을 하더라. 그러다가 OOM으로 터졌다 살아났다를 반복했다.
느려터진 주제에 리소스는 리소스대로 먹는 그런 녀석이다.
게다가 더 문제는
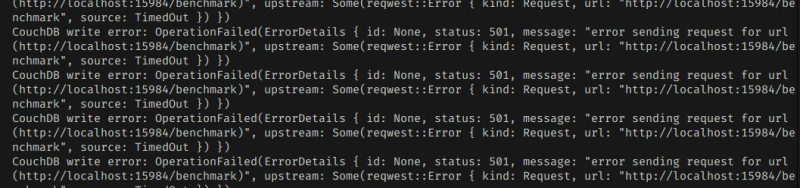 동시 쓰기 처리량이 매우 저열하고, 실패율이 매우 높았다는 것이다.
동시 쓰기 처리량이 매우 저열하고, 실패율이 매우 높았다는 것이다.
다른 DB들처럼 동시 요청 10000개씩 잡으면 통째로 뻗고 버티질 못해서 500개로 돌렸다.
 1000개만 잡아도 못버티더라.
1000개만 잡아도 못버티더라.
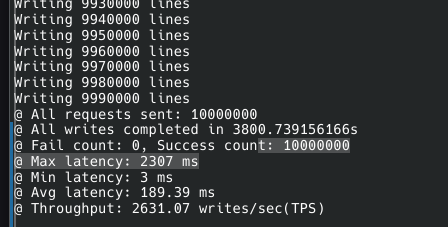 가장 느렸고
가장 느렸고
 디스크도 말도 안되게 잡아먹었다.
디스크도 말도 안되게 잡아먹었다.
이건 DB 아닌거같다.
YugabyteDB
yugabyteDB는 cockroach와 겨루는 분산 DB의 주역 중 하나다.
대륙간에 분포되는 초대형 클러스터를 염두하고 만들어졌다.
 근데 그렇것치곤, 단일노드에서의 부하 처리능력이 그렇게 좋은 편은 아니었다.
근데 그렇것치곤, 단일노드에서의 부하 처리능력이 그렇게 좋은 편은 아니었다.
메모리는 메모리대로 엄청 먹고, 스로틀링 엄청 가하고, OOM으로 터지기까지 했다. 극한상황에서의 내구성은 구린 것 같다.
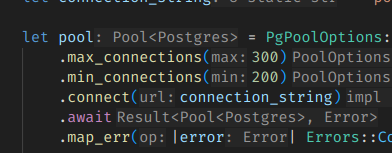 그래서 어쩔 수 없이 커넥션은 권장치인 200-300개 선으로 잡았다.
그래서 어쩔 수 없이 커넥션은 권장치인 200-300개 선으로 잡았다.

 그러고 나니 버티더라. 그래도 메모리를 많이 먹는 편이긴 하다.
그러고 나니 버티더라. 그래도 메모리를 많이 먹는 편이긴 하다.
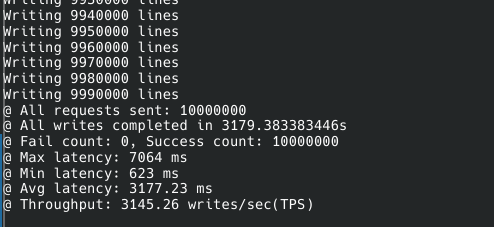 사실 그렇게 빠르진 않고
사실 그렇게 빠르진 않고
 디스크 사용량은 작은 편이었다.
디스크 사용량은 작은 편이었다.
CockroachDB
YugabyteDB의 경쟁자다. 보통 처리량 자체는 yuga보다 떨어진다는 평을 받곤 한다.

 리소스 사용량은 부하가 칠때도 비교적 안정적인 편이다.
리소스 사용량은 부하가 칠때도 비교적 안정적인 편이다.
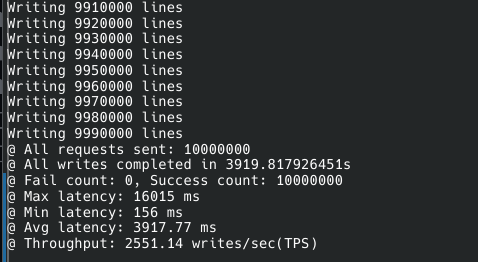 성능은.. 생각보다 느렸다.
성능은.. 생각보다 느렸다.
 디스크 사용량은 아주 큰건 아닌데 yuga보다는 컸다.
디스크 사용량은 아주 큰건 아닌데 yuga보다는 컸다.
YDB (장외패)
이것도 Cockroach와 Yugabyte와 비슷한 입지의 경쟁자인데, 인지도는 낮은 편이다.
clickhouse를 만든 yandex에서 만든 분산 SQL DB다.


 속도는 느린데 리소스 사용량은 무식하게 먹는 편이었다.
속도는 느린데 리소스 사용량은 무식하게 먹는 편이었다.
게다가 메모리 관리가 안된다. 메모리 먹다가 OOM으로 터지고, 복구도 안되더라. DB 실격이다.
Clickhouse
clickhouse도 비교를 해봤다.
async-insert를 사용하지 않을 때는 처리량이 확실히 낮았다.

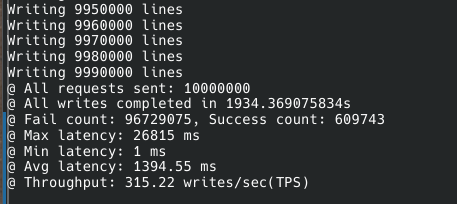 초당 300개 정도가 한계였고
초당 300개 정도가 한계였고
async insert를 사용할 때는 꽤 높은 처리량을 보여줬다.

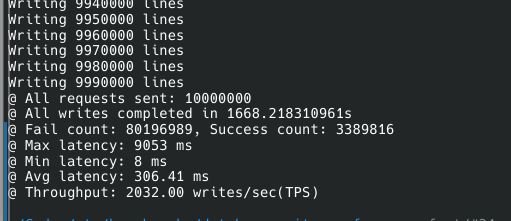 최대 초당 2000개 정도다.
최대 초당 2000개 정도다.
이거면 write 성능이 메인이 아닌 것치곤 꽤 잘 들어가는 것 같다.
 디스크 사용량은 이 정도다.
디스크 사용량은 이 정도다.
TiDB
수평 확장, 분산 SQL을 지원하는 DB다.
PostgreSQL가 지배하고 있는 오픈소스 환경에서, 특이하게도 MySQL 호환 프로토콜로 만들어진 DB다.
Cockroach 등에 비하면 동시 처리량은 높지만 일관성 수준은 비교적 낮은 편이다.



분산 SQL DB치고는 놀랍게도
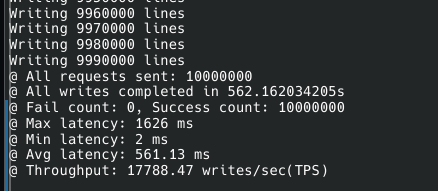 단일 쓰기 처리량이 매우 높은 편이었다. PostgreSQL에 근접했다.
단일 쓰기 처리량이 매우 높은 편이었다. PostgreSQL에 근접했다.
 디스크 사용량은 3gb가 조금 넘었다.
디스크 사용량은 3gb가 조금 넘었다.
TiKV
TiDB의 스토리지 엔진으로 사용되는 Kev-Value DB다.

 리소스 사용량, 특히 CPU 사용량이 매우 적은 편이다.
리소스 사용량, 특히 CPU 사용량이 매우 적은 편이다.
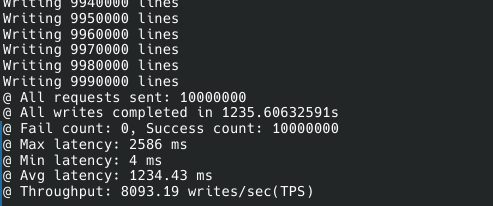 쓰기 처리량은 tiDB보다 못했다.
쓰기 처리량은 tiDB보다 못했다.
다만 이건 커넥션-동시성 핸들링을 별도로 하지 않아서 그런 것으로 추정된다.
 그리고 디스크 사용량이 비대한 편이었다.
그리고 디스크 사용량이 비대한 편이었다.
etcd
etcd는 가벼운 용도의 key-value DB다. 쿠버 등 컨테이너 스택에서 제법 자주 쓴다.


 때릴 때의 리소스 부하는 작은 편이었고
때릴 때의 리소스 부하는 작은 편이었고
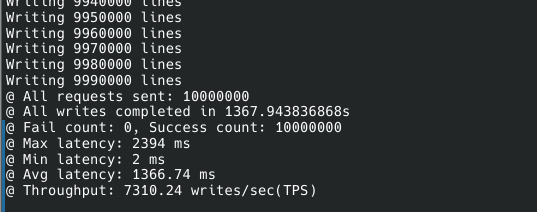 단순한 구조와 기능에 비해 처리량이 그렇게 높지는 않다.
단순한 구조와 기능에 비해 처리량이 그렇게 높지는 않다.
게다가 레이턴시 보장도 좀 딸렸다.
 디스크 사용량은 적당한 편이다.
디스크 사용량은 적당한 편이다.
nats Jetstream
nats는 기본적으로 큐 시스템이지만, 내부의 KV 엔진 또한 독립적으로 제공된다.

 리소스는 적당히 쓰는 편인데
리소스는 적당히 쓰는 편인데
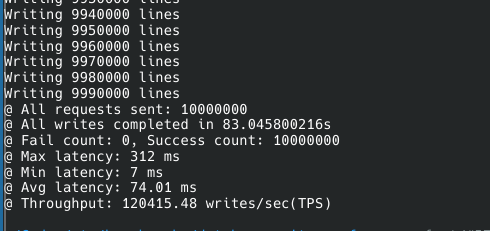 중요한건 압도적인 처리량이다. 함께 때려본 그 어떤 DB보다 빠르다.
중요한건 압도적인 처리량이다. 함께 때려본 그 어떤 DB보다 빠르다.
 디스크 사용량은 컴팩트한 편이다.
디스크 사용량은 컴팩트한 편이다.
Elasticsearch
Elasticsearch는 메인 DB보다는 검색엔진이나 로그 저장소로 자주 사용되는 특수한 용도의 DB다.
 리소스 사용량은 제법 많은 편이다. 애초에 JVM으로 절반 점유하고 시작하니까 많아보일 수 밖에 없다.
리소스 사용량은 제법 많은 편이다. 애초에 JVM으로 절반 점유하고 시작하니까 많아보일 수 밖에 없다.
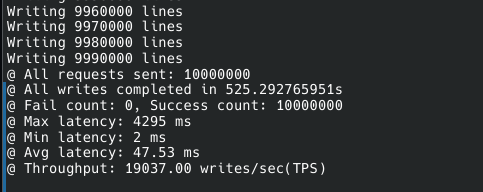 쓰기 처리량은 생각보다 매우 높았다.
쓰기 처리량은 생각보다 매우 높았다.
동시 쓰기 단위를 1000개 정도로 잡으니까 적절히 버텼고, 10000개는 잘 못버티더라.
 디스크 사용량은 작지 않은 편이다.
디스크 사용량은 작지 않은 편이다.
Opensearch
Elasticsearch의 포크라서 비슷할 줄 알았는데, 좀 다르더라.
 일단 elasticsearch와 비교하면 메모리 사용량이 확연하게 적은 편이다.
일단 elasticsearch와 비교하면 메모리 사용량이 확연하게 적은 편이다.
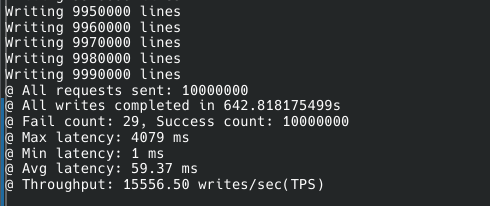 다만 처리량은 비슷하거나 더 적다.
다만 처리량은 비슷하거나 더 적다.
 디스크 사용량은 비슷하다,
디스크 사용량은 비슷하다,
정리
결과 정리한 테이블
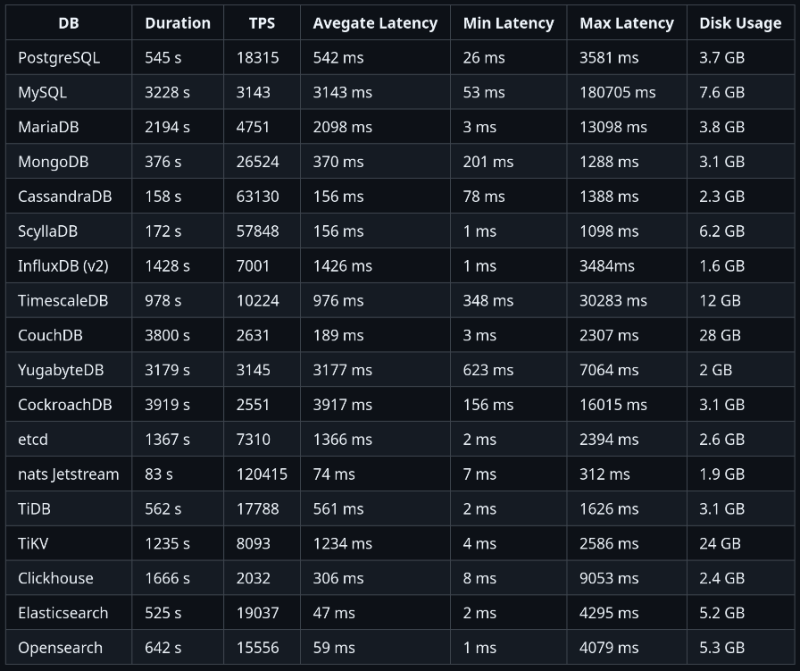 RDB는 생각보다 느리지 않다. 무작정 NoSQL가 빠르다는 것은 미신에 가깝다.
RDB는 생각보다 느리지 않다. 무작정 NoSQL가 빠르다는 것은 미신에 가깝다.
특히 Postgres가 처리량이 뛰어났다. mysql 친구들은 발전이 더뎌보인다.
쓰기 측면에서 가장 강력한 시스템은 Cassandra였다. 대규모 조직들에서 애용하는 이유가 있다.
elasticsearch/opensearch는 꽤 뛰어난 쓰기 처리량을 보여준다.
분산시스템을 지향하면서 분산트랜잭션까지 강력하게 지원하는 DB. yuga나 cockroach는 생각보다 저열한 단일노드 처리량을 보여줬다. 단일노드 처리량이 후달리는데, 멀티노드 처리량이 뛰어날 수가 있겠나?
진짜 노드 수십개 띄우고 그러는거 아니면 이득을 보는 지점이 쉽게 오지 않을 것 같다.