[PostgreSQL] Internal: 데이터 저장 구조
PostgreSQL에서 데이터가 어떤 형태로 저장되는지를 한번 정리해본다.
PostgreSQL의 테이블 데이터 등은 일단, 바로 저장되는 것이 아니라 WAL이라는 로그시스템을 거쳐서 만들어진다. 이에 대한 충분한 이해가 없다면, 데이터베이스를 알고 있다고 말할 수 없다.
https://blog.naver.com/sssang97/224026498626
테이블 저장 경로 찾기
자, 그럼 테이블을 하나 만들고, 그게 어떤 식으로 저장되는지 찾아보자.
create table foo(key int8 primary key, value text); 일단 테이블을 대충 하나 만들었다.
일단 테이블을 대충 하나 만들었다.
이걸 찾으려면 테이블의 OID와 데이터베이스의 OID를 찾아야 한다. 내부적으로는 테이블이나 데이터베이스의 이름이 아니라, 이 고유한 내부 정수 ID를 통해서만 접근할 수 있다.

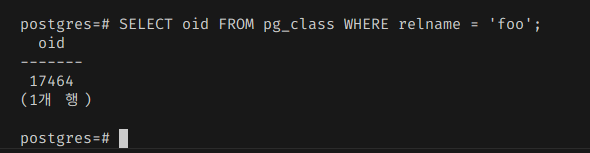 그러먼 이 2개의 조합으로 data 디렉터리를 뒤져서 찾을 수 있다.
그러먼 이 2개의 조합으로 data 디렉터리를 뒤져서 찾을 수 있다.
실제 경로는 /pgdata/base/DB-OID/TABLE-OID다.
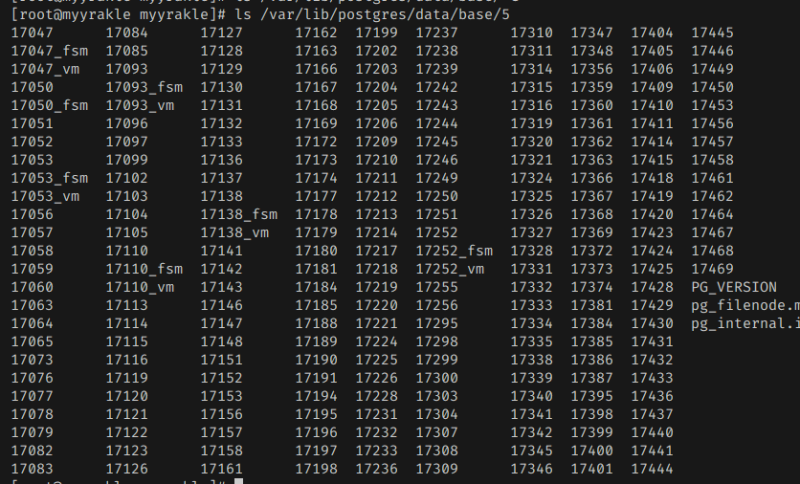 그래서 들어가보면 데이터베이스 디렉터리에도 뭐가 많고
그래서 들어가보면 데이터베이스 디렉터리에도 뭐가 많고
 테이블 OID까지 쓰면 정확하게 짚어낼 수 있다.
테이블 OID까지 쓰면 정확하게 짚어낼 수 있다.
이게 방금 만든 테이블의 데이터 저장소다. 아직 데이터를 넣지 않아서 크기는 0이긴 하다.
이 파일을 세그먼트 파일이라고 부른다.
그리고 테이블 자체에 대한 메타 정보(컬럼 목록 등)은 pg_attribute 등 내부 관리용 테이블에 저장된다. 일반 테이블과 구조적으로 동등하고, 이것만을 위한 데이터 구조가 별도로 있는 건 아니다.
세그먼트와 크기
테이블에 데이터를 한번 넣어보자. 1000개 정도만 간단하게 넣어봤다.
insert into foo(key, value)
select t.n, (random()*10)::TEXT
from
(
select generate_series(1, 1000) as n
) as t;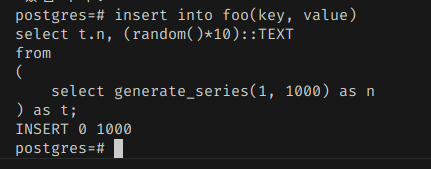
 그럼 이렇게 파일 크기가 늘어난다.
그럼 이렇게 파일 크기가 늘어난다.
이 세그먼트 파일들은 데이터의 상태와 상관없이 저렇게 단일 세그먼트 파일에 계속 append하는 식으로 성장한다. Primary Key나 그런 것들은 고려되지 않는다.
그리고, 물론 단일 세그먼트 크기에도 제한은 있다.
기본값은 1GB인데, 다음 플래그로 확인할 수 있다.
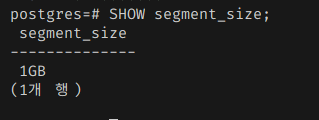 이 옵션은 영향이 너무 커서 initdb로 데이터베이스를 초기화할 때만 설정할 수 있는 정적 플래그다.
이 옵션은 영향이 너무 커서 initdb로 데이터베이스를 초기화할 때만 설정할 수 있는 정적 플래그다.
아무튼 이 크기 제한을 넘어서면, postgres는 세그먼트 파일에 또 숫자를 붙여서 분할한다. foo.1, foo.2 같은 식이다.
그러면 실제로도 잘 분할되는지 데이터를 넣어보자. 3000만개 정도만 넣어봤다.
insert into foo(key, value)
select t.n, (random()*10)::TEXT
from
(
select generate_series(1, 30000000) as n
) as t
ON CONFLICT DO NOTHING; 그러면 실제로 이렇게 잘 늘어나는 것을 확인할 수 있을 것이다.
그러면 실제로 이렇게 잘 늘어나는 것을 확인할 수 있을 것이다.
세그먼트와 계층구조
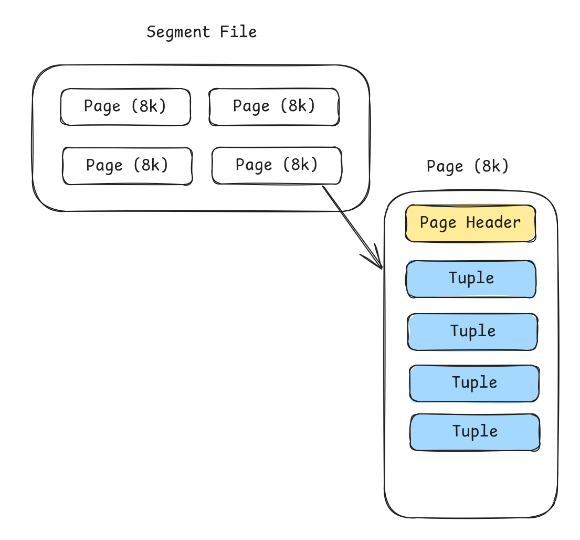
각 세그먼트 파일은 또 페이지라고 부르는 논리적인 단위로 분리된다.
 별도의 파일이 또 있는건 아니고, 약 8k 정도씩을 고정 크기 블록으로 분리해서 사용하는 것이다.
별도의 파일이 또 있는건 아니고, 약 8k 정도씩을 고정 크기 블록으로 분리해서 사용하는 것이다.
이를 통해서 I/O 단위를 예측 가능하게 관리한다. 8k 정도가 경험적으로 효율적인 스캔 단위라고 입증된 것도 있다.
그리고 각 페이지에는 실질적인 데이터들이 들어있다. 각 데이터 행을 Tuple이라고 부른다.
세그먼트 파일과 VACUUM
세그먼트 파일은 기본적으로는 축소되지 않는 데이터 저장 구조다.
게다가 PostgreSQL은 MVCC 방법론을 써서 old version 데이터와 삭제된 데이터를 별도의 버전으로 보고 즉시 삭제하지 않는다.
그럼에도 불구하고, 삭제된 데이터를 결국 정리하긴 해야 한다. 그걸 해주는게 VACUUM이란 프로세스다.
AUTO VACUUM은 삭제할 튜플이 있다면, 그걸 삭제하는게 아니라 "재사용 가능"한 상태로 마킹한다.
이렇게 마킹된 튜플은 추후 write가 들어올 때 overwrite될 수 있다.
그래서 테이블 데이터들은 재사용을 통해 크기를 보존할 수는 있어도, 자연적으로 축소되진 않는다.
FULL VACUUM의 경우에는 확실하게 데이터 축소를 할 수 있다.
근데 이것도 기존의 세그먼트 파일을 압축하는건 아니고, 새로운 .tmp 세그먼트 파일을 만들어서 병합하고 대체하는 방식을 취한다.
FSM과 VM
근데 단순 데이터 파일 말고도 뭔가 이상한게 보인다.
FSM은 뭐고 VM은 또 뭐란 말인가?
FSM은 Free Space Map이라고 해서, 기존 세그먼트 파일에 대해서 빈 공간을 찾을 수 있게 해주는 보조 파일이다.
매번 쓰기가 발생할때마다 append하는 것은 낭비가 너무 심하니, 적당히 빈 공간이 있거나 재사용 가능한 공간이 있다면 그걸 찾아서 쓸 수 있게 해준다. 그래서 vacuum과도 연관이 깊다.
VM은 Visibility Map의 축약인데, 수정/삭제가 발생하지 않아 완전히 "안정된" 값을 판별할 수 있게 해준다.
더 정확히 말해서 "모든 트랜잭션에서 공통으로 볼 수 있는" tuple들을 추적하는 용도로 관리되는 매핑 테이블이다.
이건 2가지 용도에 활용되는데, VACUUM과 INDEX SCAN 과정에도 최적화를 할 수 있게 보조해준다.
대충 다음과 같은 원리다.
-
VACUUM에서 VM을 사용하면: VACUUM이 실행될때, "모든 트랜잭션에서 보이는 tuple"은 완전히 유효한 값이므로 삭제 대상에서 빠르게 배제할 수 있다.
-
인덱스를 스캔할 때도, 원래는 MVCC 체크를 해서 유효한 값을 한번 더 검사하는데, VM을 사용해서 완전히 유효하다는 것이 검증되면 MVCC 체크를 건너뛰고 빠르게 스캔을 처리할 수 있다.
세그먼트 파일의 스캔
저 세그먼트 파일은 WAL처럼 그냥 우직하게 쌓는 순차적 저장 파일이다.
삽입 순서에 따라서만 쌓기 때문이 이 자체로는 의미있는 스캔이 불가능하다.
그래서 인덱스를 통해서 의미있는 값 기준의 접근을 할 수 있도록 해야 한다. 인덱스에는 테이블 페이지를 가리키는 주소값들이 들어있다.
인덱스 파일 위치
인덱스도 테이블과 같은 영역에서 찾을 수 있다.
저기 indexrelid가 인덱스에 대한 OID다.
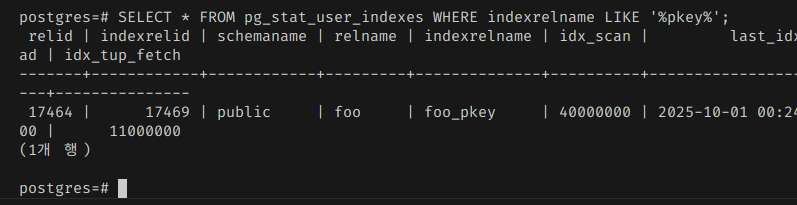
마찬가지로 데이터베이스 데이터 디렉토리 바로 아래에 있다.
 저게 바로 BTree 기반으로 만들어진 인덱스 파일이다. 643MB 정도를 차지하고 있다.
저게 바로 BTree 기반으로 만들어진 인덱스 파일이다. 643MB 정도를 차지하고 있다.
이 파일은 테이블 세그먼트와는 다르게, B-Tree 논리에 기반해서 내부적으로 파일이 분할되어있다.
하나의 인덱스 파일은 여러개의 페이지로 구성되고, 페이지에서 다른 페이지를 트리 형태로 계속해서 쫒아가는 식으로 구성된다. 그리고 당연히 리프 노드에는 실제 테이블 행을 가리키는 페이지 주소가 있을 것이다.
그리고 이 인덱스 파일도 마찬가지로, 크기가 너무 커지면 여러개의 파일로 분할된다.
그 기본 설정은 1GB고, 1GB가 넘으면 pkey.1, pkey.2 같은 식으로 늘어나는 것이다.