[PostgreSQL] 텍스트 검색과 인덱스
텍스트에 대한 유연한 검색은 매우 피곤하고 골치아픈 문제다.
단순 일치(exact match)인 경우에는 별다른 문제가 없지만, 포함 검색 등이 들어가고, 사용자 편의에 맞춰서 기능을 덧대다보면 성능상 문제가 반드시 생기게 된다.
여기에서는 PostgreSQL가 어디까지 할 수 있는지, 어떻게 할 수 있는지를 대강 정리해본다.
테스트 데이터 세팅
1000만개 정도만 데이터를 간단하게 세팅해보겠다.
CREATE TABLE benchmark_table
(
id serial8 PRIMARY KEY,
text varchar(1000) NOT NULL
);
INSERT INTO benchmark_table(text)
SELECT LPAD(t.n::TEXT, 7, '0')
FROM
(
SELECT generate_series(1, 9999999) as n
) as t;
SELECT * FROM benchmark_table(text); 만들고
만들고
 적당히 이런 식으로 들어가게 해놨다.
적당히 이런 식으로 들어가게 해놨다.
기본 인덱스
먼저 기본 인덱스가 동작하는 방식부터 봐보자.
create index benchmark_index_v1 on benchmark_table(text);이렇게 만드는 기본 옵션 인덱스는, BTree 구조에 따라서 일치 비교(=), 대소 비교(<, >) 등에 대해서만 잘 동작한다.
그래서 그냥 동등 검색을 하거나
EXPLAIN ANALYZE SELECT *
FROM benchmark_table
WHERE text = '9978742';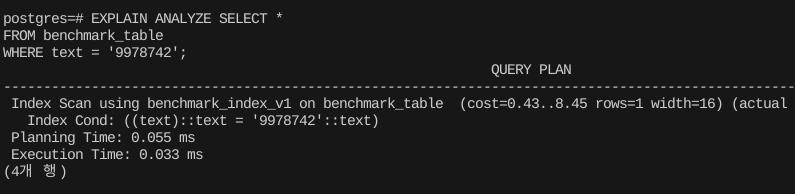
범위 검색을 하면
EXPLAIN ANALYZE SELECT *
FROM benchmark_table
WHERE text BETWEEN '9978742' AND '9988742';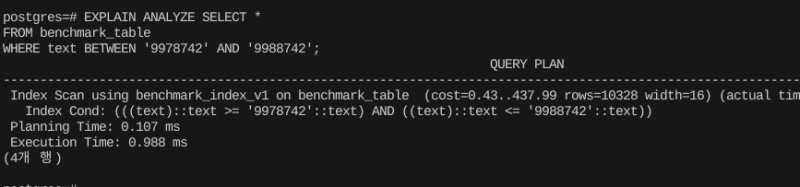 인덱스를 매우 잘 탄다.
인덱스를 매우 잘 탄다.
하지만 LIKE 같은 '특별한' 연산을 하거나, 대상 컬럼에 추가 연산을 더한다면 인덱스를 타지 못한다.
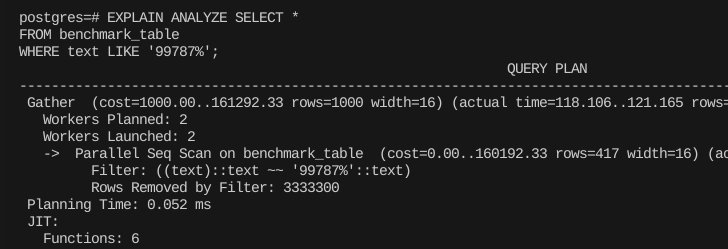 이건 당연한 설계상의 문제다.
이건 당연한 설계상의 문제다.
여기서부터는 경우에 맞춰서 선택을 해줘야 한다.
패턴 검색 (StartsWith)
만약 패턴 와일드카드(%)가 맨 앞에 붙지만 않는다면, 문제는 그다지 어렵지 않다.
이런 용도에 맞는 Index 커스텀 연산자로 text_pattern_ops라는 것이 제공되기 때문이다.
create index benchmark_index_v2 on benchmark_table(text text_pattern_ops);
이 인덱스를 적용하고 쿼리를 날려보면
EXPLAIN ANALYZE SELECT *
FROM benchmark_table
WHERE text LIKE '99787%';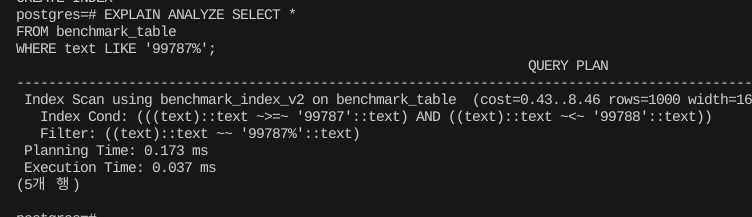 이제는 인덱스를 탈 것이다.
이제는 인덱스를 탈 것이다.
하지만 와일드카드가 맨 뒤에 붙는 경우가 아니라면 인덱스를 잘 타지 않는다. 이 방식은 Startswith 케이스에만 잘 동작한다.
EXPLAIN ANALYZE SELECT *
FROM benchmark_table
WHERE text LIKE '%99787';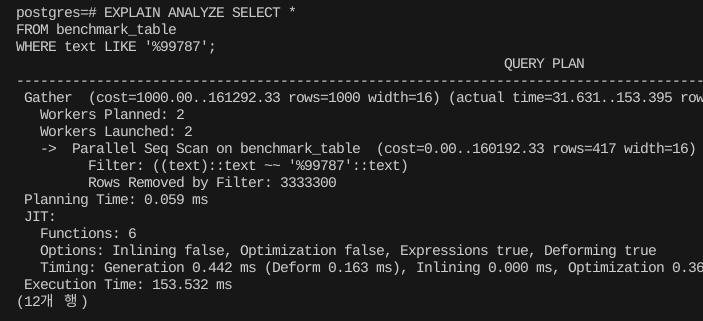
패턴 검색 (Contains)
여기서부터는 설정도 조금 귀찮고, 컴퓨팅 리소스도 약간 더 먹을 수는 있다.
pg_trgm라는 확장을 사용해야 하고, GIN이라는 특수화된 인덱스 타입을 사용해야 한다.
먼저 확장을 설치한다. 기본 확장이라서 그냥 명령만 실행하면 설치된다.
CREATE EXTENSION pg_trgm;
그리고 인덱스를 이런 식으로 만들면 된다.
create index benchmark_index_v3 on benchmark_table using gin(text gin_trgm_ops);그러면 이제 완전 포함 쿼리 (%text%)를 날려도 인덱스를 탄다.
EXPLAIN ANALYZE SELECT *
FROM benchmark_table
WHERE text LIKE '%99999%';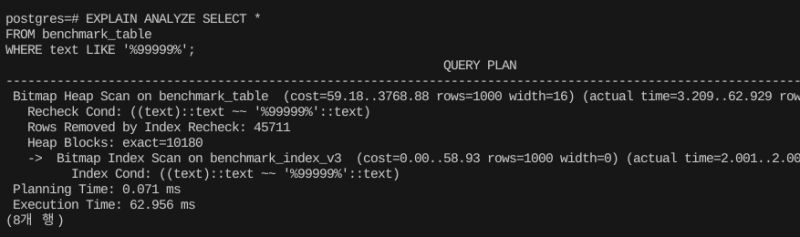
근데 이것도 문제가 있다.
이 인덱스는 내부적으로 모든 텍스트를 3글자씩 쪼개고 부분적으로 인덱스를 걸어서 조합하는 방식으로 동작한다. 그래서 검색 텍스트가 3자 미만인 경우에는 제대로 동작하지 않는다.
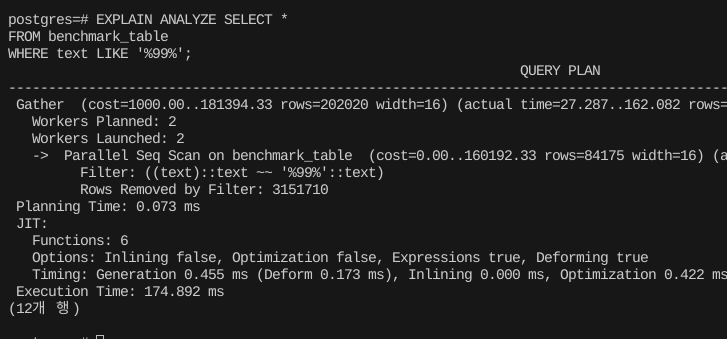 2글자로 줄어드니 인덱스 자체를 타지 않는 것을 볼 수 있다.
2글자로 줄어드니 인덱스 자체를 타지 않는 것을 볼 수 있다.
이런 경우에는 사실, 매칭되는 것이 너무 많아서 풀스캔을 하는게 현명한 경우가 많을 수 있다. 구조적 한계와 별개로도 말이다.
대소문자 무시 검색
또 흔한 사용사례 중 하나가, 대소문자를 구분하지 않고 검색을 하도록 하는 것이다.
먼저 데이터를 추가로 세팅해보자
WITH BASE58_LIST AS (
SELECT
ARRAY[
'1', '2', '3', '4', '5', '6', '7', '8', '9',
'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i',
'j', 'k', 'm', 'n', 'o', 'p', 'q', 'r', 's',
't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B',
'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L',
'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V',
'W', 'X', 'Y', 'Z'
] AS list
)
INSERT INTO benchmark_table(text)
SELECT
-- 6자리 코드 생성
(SELECT list FROM BASE58_LIST)[(RANDOM()*57)::INTEGER + 1]
||
(SELECT list FROM BASE58_LIST)[(RANDOM()*57)::INTEGER + 1]
||
(SELECT list FROM BASE58_LIST)[(RANDOM()*57)::INTEGER + 1]
||
(SELECT list FROM BASE58_LIST)[(RANDOM()*57)::INTEGER + 1]
||
(SELECT list FROM BASE58_LIST)[(RANDOM()*57)::INTEGER + 1]
||
(SELECT list FROM BASE58_LIST)[(RANDOM()*57)::INTEGER + 1]
AS code
FROM
(SELECT GENERATE_SERIES(1, 1000000)) T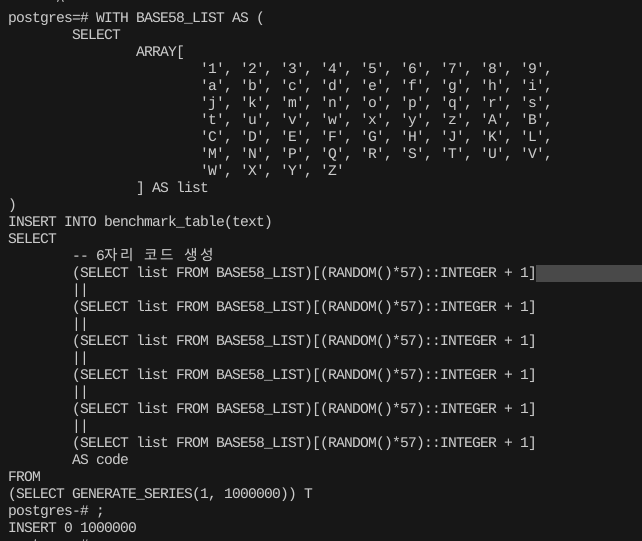
그리고 대소문자를 무시하도록 쿼리를짜면, 아마 이런 식으로 작성할 수 있을 것이다.
SELECT *
FROM benchmark_table
WHERE LOWER(text) = LOWER('bv3m94')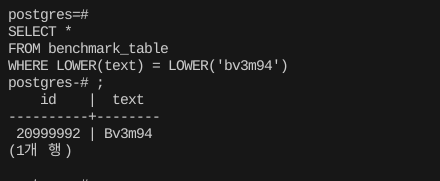 동작은 잘 한다만, 이런 식으로 대상 컬럼에 연산을 가하는 표현은 원칙적으로 인덱스를 타지 않는다.
동작은 잘 한다만, 이런 식으로 대상 컬럼에 연산을 가하는 표현은 원칙적으로 인덱스를 타지 않는다.
그래서 찍어보면
EXPLAIN ANALYZE
SELECT *
FROM benchmark_table
WHERE LOWER(text) = LOWER('bv3m94')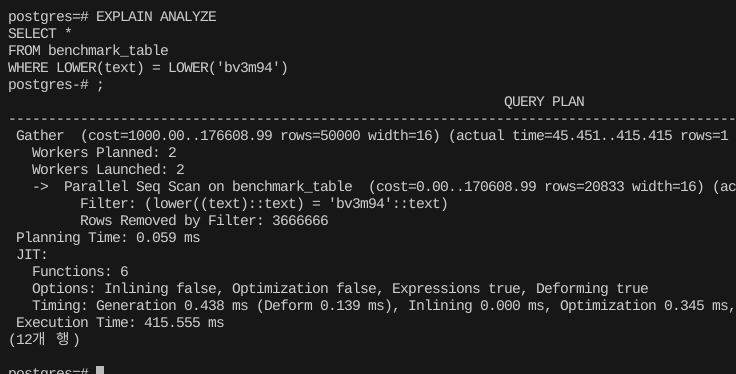 풀스캔을 도는 것을 볼 수 있다.
풀스캔을 도는 것을 볼 수 있다.
여기엔 다행히 간단한 해결법이 있다.
PostgreSQL은 인덱스를 만들때, 대상 컬럼에 추가 연산을 더하는 것이 가능하다.
이런 식으로 컬럼에 LOWERCASE를 걸어버리면, 인덱스를 만들때 다 소문자로 압축해서 구성해버린다.
create index benchmark_index_v4 on benchmark_table(LOWER(text));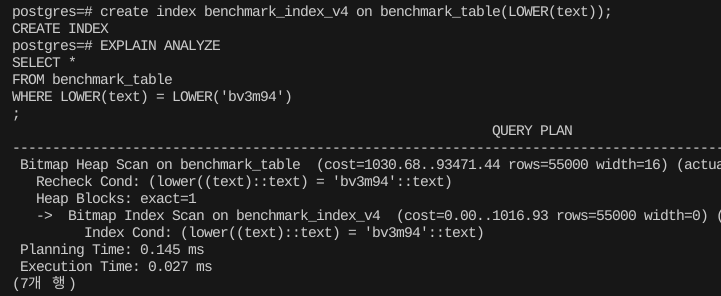 그러면 이제는 인덱스를 잘 탈 것이다.
그러면 이제는 인덱스를 잘 탈 것이다.
고급: 어휘 단위 검색 (Full Text Search)
위에서 다룬 "포함 검색"들은, 글자 하나하나 단위로 검색을 수행하는 것이었다.
하지만 실제 UX에서는 글자 단위가 아닌, 단어나 어휘 단위로 검색이 되기를 원하는 경우가 많다.
이런 걸 할때 많이 사용되는 시스템은 Elasticsearch고, 실제로도 Elasticsearch가 이 방면에서 기능적으로 가장 뛰어난 것이 맞긴 하다. 이런 고급 검색이 필요하면서 + 복잡한 필터링, 동의어, 다국어 처리, 스코어 정렬 등까지 필요하다면 PostgreSQL로는 한계가 분명하게 있다. 그럴때는 그냥 Elasticsearch를 쓰는 것을 추천한다.
하지만 PostgreSQL로도 tsvector와 tsquery 등을 사용하면 어느 정도는 따라할 수 있다.
이에 대한 것은 추후 별도 포스트로 정리해보겠다.