Vector 유사도 비교 알고리즘
관련 포스트
https://blog.naver.com/sssang97/223790220320
벡터 임베딩/검색에 쓰이는 벡터 형식과, 그 제약조건 등에 대해 정리해본 글이다.
굳이 수식을 늘어놓지는 않고, 코드 위주로 적어본다.
1. 유클리드 거리 (Euclidean Distance)
가장 단순하고 제약조건도 딱히 없는, 단순한 알고리즘이다.
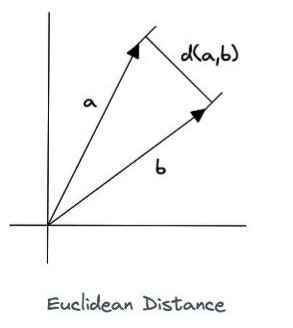 비교할 벡터값들을 요소끼리 뺀 다음에 제곱하고, 그걸 다시 더해서 다시 루트 씌우는 것이다.****
비교할 벡터값들을 요소끼리 뺀 다음에 제곱하고, 그걸 다시 더해서 다시 루트 씌우는 것이다.****
그리고 이 결과값이 거리(distance) 값이 되고, 이 값이 작을 수록 유사도가 높은, 가까운 벡터가 되는 것이다.
0이라면 완전히 동일한 것이고, 클수록 먼 값이다.
유클리드 거리에 대한 벡터 연산 구현은 매우 간단한 편이다.
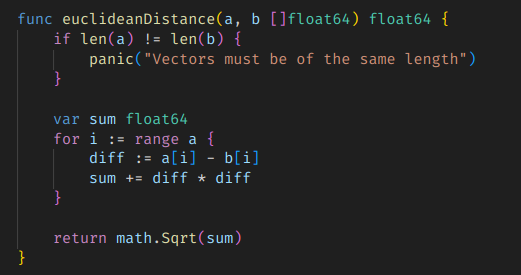
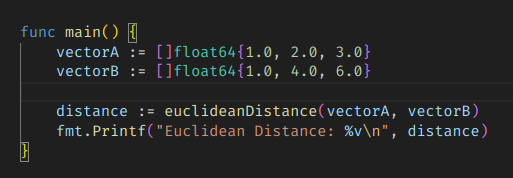
 그냥 이런 느낌이다.
그냥 이런 느낌이다.
2. Dot Product 유사도
유클리드 거리가 단순히 거리만을 측정하는 비교라면, Dot Product는 거리와 방향을 동시에 고려하는 비교 방법이다.
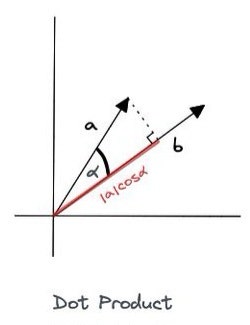
계산 방법은 간단하다. 그냥 각 요소를 곱한걸 총합하면 되는 것이다.
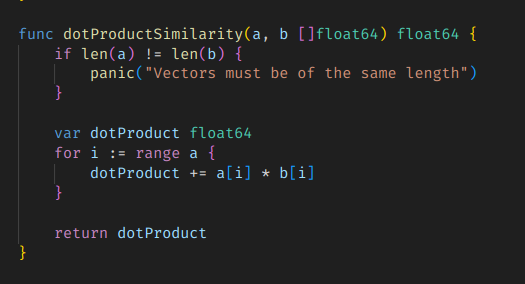

 그냥 무작정 더하는 거라서 값의 범위에 제약이 없고, 값에 특별한 의미도 없다. 값이 클수록 유사하다고 보지만, 완전히 같을 경우에 가지는 특정한 값이 없다.
그냥 무작정 더하는 거라서 값의 범위에 제약이 없고, 값에 특별한 의미도 없다. 값이 클수록 유사하다고 보지만, 완전히 같을 경우에 가지는 특정한 값이 없다.
완전히 같을 경우 코사인이 1, 유클리드가 0이라는 값을 가지게 되는 것과 다르게, 그냥 값의 크기에 따라서 엄청나게 들쭉날쭉한다.
그래서 제대로 가공되지 않은 벡터들에 대해 Dot Product를 돌리는 것은 품질이 좋지 않을 수도 있다.
3. 코사인 유사도 (Cosine Similiarity)
코사인 유사도는 거리를 고려하지 않고 "방향"만을 비교하는 유사도 비교 방법이다.
아무리 좌표상 멀리 있더라도 방향이 비슷하면 가까운 것이다.
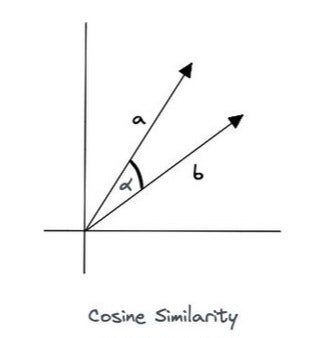
구현 방법은 그다지 어렵지 않다.
개념적으로는 Dot Product 연산에 normalize 과정을 추가해서 거리 값을 버리는 것으로 만들어지기 때문이다.
다음과 같이, normalize를 위한 개발 총합 값을 모은 다음에 루트 씌우고, 그걸 기준값으로 나누면 된다.
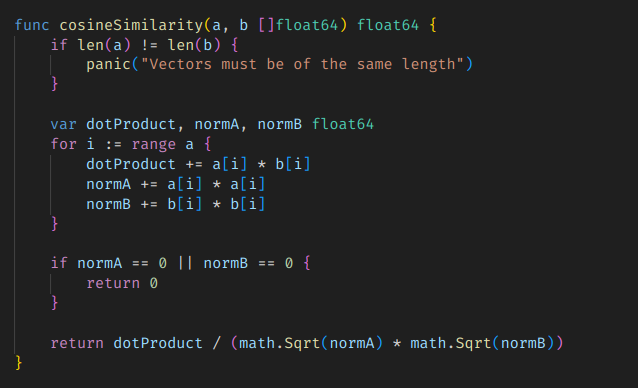
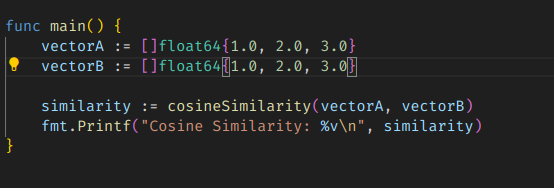
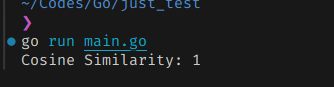 완전히 같다고 판단되면 1이 나오고, 멀어질수록 0에 가까워진다.
완전히 같다고 판단되면 1이 나오고, 멀어질수록 0에 가까워진다.
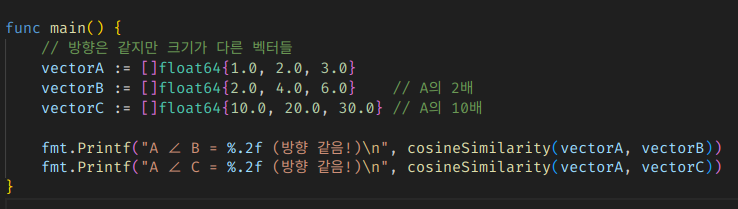
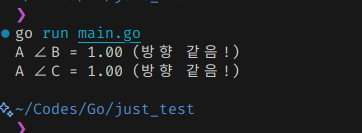 그래서 실제로 값이 다르더라도, 방향만 같다면 같다고 한다.
그래서 실제로 값이 다르더라도, 방향만 같다면 같다고 한다.
코사인 유사도: Unit Vector 기반 최적화
naive한 코사인 비교 방식의 문제는, 느리다는 것이다.
normalize 값을 뽑기 위해서 집계 연산도 세번씩이나 하고, root 연산도 두번씩이나 돌려야 한다.
이게 한두번이라면 괜찮지만, 대단위 데이터 처리에 있어서는 심각한 병목이 된다.
그래서 효율적인 Cosine 유사도 처리 구현에서는 저런 방법을 쓰지 않는다.
생각해보면, 코사인 연산은 Dot Product에 normalize 수치를 나눈 것에 불과하다.
그러면... 아예 벡터에 미리 normalize 나눗셈 처리를 하면 되는 게 아닌가? 당연히 된다.
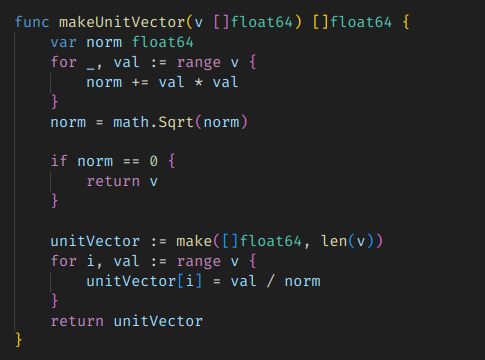 그냥 이렇게 집계해서 나눠두면 된다.
그냥 이렇게 집계해서 나눠두면 된다.
방금 위에서 구현했던 코사인 비교 로직에서 normalize 처리만 분리된 것이다.
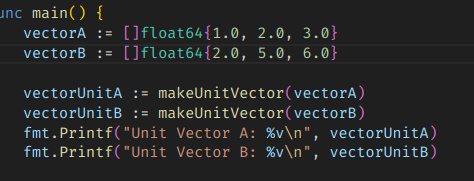
 그러면 이렇게 기묘하게 작아진 값의 배열이 만들어진다.
그러면 이렇게 기묘하게 작아진 값의 배열이 만들어진다.
이렇게 만들어진 unit vector는 수학적인 제약사항을 가진다. 모든 요소를 제곱해서 더하면 1이 된다는 것이다.
그리고 저렇게 만들어진 unit vector를 가져다가 dot product 연산을 돌리면 된다.

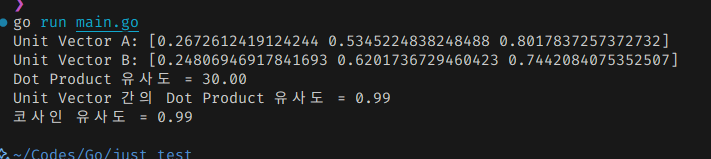 그러면 이처럼 순진한 코사인 유사도와 같은 값이 나오는 것을 볼 수 있다.
그러면 이처럼 순진한 코사인 유사도와 같은 값이 나오는 것을 볼 수 있다.
결과는 같지만 Dot Product의 연산 리소스가 훨씬 적기 때문에 대부분의 상황에서 이게 더 효과적이다.
그래서 대부분의 VectorDB 구현체들은 unit vector 기반으로 Cosine 인덱스 시스템을 구현한다.
INSERT를 받을때 내부적으로 unit vector 변환해서 저장하고, 비교를 할때도 unit vector로 변환해서 DOT PRODUCT를 처리하는 식이다.
참조
https://stackoverflow.com/questions/10002918/what-is-the-need-for-normalizing-a-vector