[PostgreSQL] INSERT 처리량 최적화해보기
PostgreSQL은 RDB들 중에서는 쓰기 처리량이 상당히 높은 축에 속하지만, 쓰기 처리에 최적화된 일부 NoSQL들에 비하면 조금 낮다.
그럼에도 불구하고, 옵션 튜닝을 하고 뭔가를 좀 포기한다면, 성능을 더 끌어올리는 것도 어려운 일은 아니다.
DB 옵션을 여기저기 건드려보면서 INSERT 성능을 땡겨보는 실험을 기록한 글이다.
테스트 환경은 amd64 cpu 2, ram 8gb, SSD 환경이다.
UPDATE/DELETE/SELECT/LOCK이 동시에 혼재되는 리얼한 환경이 아니라, 순수한 INSERT 성능에 대해서만 다뤘다. 그래서 실제와는 크게 다를 수도 있다.
테스트 환경 구성
1000만개의 단순 key:value 데이터셋을 두고, 무식하게 때려넣는 코드를 작성했다.
https://github.com/myyrakle/benchmarks/tree/master/database_write_performance
1000만개 생성하고
 이렇게 만들어진 걸 밀어넣었다.
이렇게 만들어진 걸 밀어넣었다.
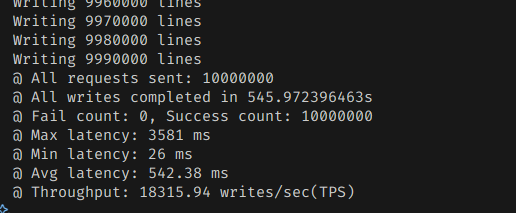 그럼 초당 20000개 언저리 정도를 때려넣는 것을 볼 수 있다.
그럼 초당 20000개 언저리 정도를 때려넣는 것을 볼 수 있다.
CassandraDB처럼 엄청나게 처리량이 좋은건 아니지만, 사실 RDB 중에서는 특출나게 뛰어난 편이다.
문제: WAL과 fsync
사실 모든 데이터베이스를 통틀어서, 쓰기 성능에 병목이 되는 부분은 디스크에 쓰기 완료를 보장하는 것이다.
이걸 linux에서는 fsync라고 하는데, PostgreSQL은 높은 데이터 내구성을 보장하기 위해서 다소 비효율적으로 flush를 하는 부분이 있다.
이건 옵션을 넣으면 내구성을 좀 포기하는 대신에 쓰기 처리량을 높이는 것이 가능하다.
commit_delay 옵션
PostgreSQL은 기본적으로, 트랜잭션이 커밋될때마다 디스크에 WAL 파일을 flush한다.
하지만 commit_delay 옵션을 건드리면, 실제로 커밋 내역들이 디스크에 기록되는 시점을 지연시킬 수 있다.
그러면 지연된 커밋들을 한번에 모아다가, 딜레이가 끝나면 디스크에 flush하는 식으로 동작한다.
이 옵션의 기본값은 0이다. 모든 커밋은 즉시 flush된다.
주요 플래그는 commit_delay와 commit_siblings다. commit_delay은 마이크로초 단위의 지연 플래그고, commit_siblings은 동시 트랜잭션 임계값이다.
 예를 들어 이런 식으로 지정하면, 동시 트랜잭션이 5개 이상인 경우에만 1000마이크로초만큼 쓰기를 모았다가 commit flush를 하는 식으로 동작한다.
예를 들어 이런 식으로 지정하면, 동시 트랜잭션이 5개 이상인 경우에만 1000마이크로초만큼 쓰기를 모았다가 commit flush를 하는 식으로 동작한다.
commit_siblings는 충분한 동시 트랜잭션이 있을때만 배치 처리를 하게 해주는 조건부 플래그인 셈이다.
저렇게 해놓고 돌려보면
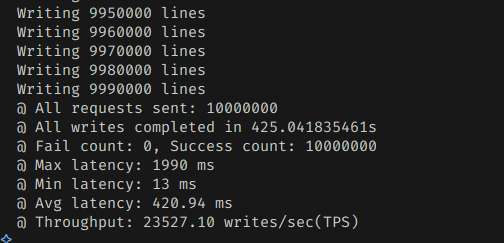 실제로 미미한 처리량 증가가 보인다.
실제로 미미한 처리량 증가가 보인다.
그러면 클수록 빨라질까?
최대값인 100ms로도 늘려봤다.

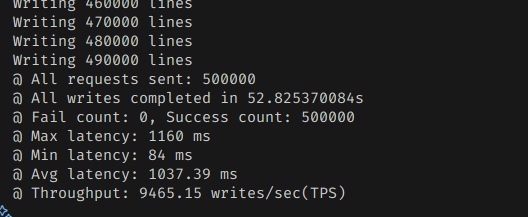 그렇지는 않은 것 같다. 너무 한번에 많이 모아서 디스크에 쓰니까 오히려 성능이 떨어졌다.
그렇지는 않은 것 같다. 너무 한번에 많이 모아서 디스크에 쓰니까 오히려 성능이 떨어졌다.
이것도 쓰더라도 적당히를 잡는게 중요하다. 최대값이 100밀리초로 걸려있는 이유가 있다.
WAL 비동기 커밋: synchronous_commit
synchronous_commit 값을 off로 걸면, WAL에 쓰기를 할때 쓰기 완료를 기다리지 않고, 비동기로 동작하게 할 수 있다.
 그러면 당연히 내구성이 떨어지지만, 각 커밋 단위가 디스크 flush를 기다리지 않고 재개할 수 있기 때문에 처리량은 늘릴 수 있다.
그러면 당연히 내구성이 떨어지지만, 각 커밋 단위가 디스크 flush를 기다리지 않고 재개할 수 있기 때문에 처리량은 늘릴 수 있다.
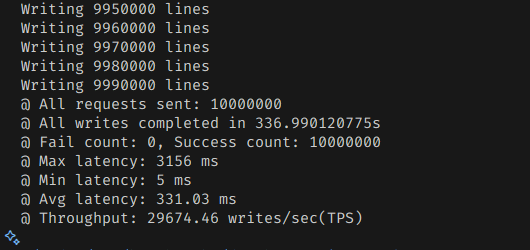 그러면 확연하게 처리량이 늘어난 것을 볼 수 있다.
그러면 확연하게 처리량이 늘어난 것을 볼 수 있다.
WAL 디스크 쓰기 보장 끄기: fsync
그럼 그냥... 디스크 쓰기 보장을 꺼버리는 건 어떨까?
fsync=off 옵션을 넣으면 실제로 fsync를 날리지 않도록 해버릴 수 있다.
물론 이렇게 한다고 해서 디스크를 안쓰는 것은 아니다. 확실하게 쓰지 않으니 메모리에만 쓰기를 수행한 채로 시스템이 중단되면 증발할 위험이 증가할 뿐이다.
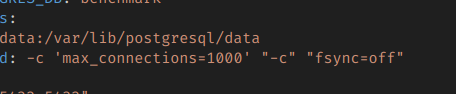 플래그 적용은 간단하다.
플래그 적용은 간단하다.
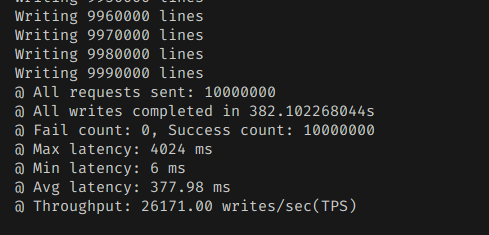 근데 의외로 성능 격차가 크게 나진 않았다.
근데 의외로 성능 격차가 크게 나진 않았다.
흠... 내가 생각했을때는 다른 방법보다 빨라야 했는데, 그러지 않은게 좀 의아했다.
WAL 크기 늘려보기
PostgreSQL의 WAL 파일별 크기는 16mb로 고정이다.
이건 대부분의 상황에서 최적값이긴 하지만, 때로는 조금 더 크게 잡는게 효율적일 수도 있다.
실제로 CassandraDB는 WAL 사이즈를 32mb로 잡는다.
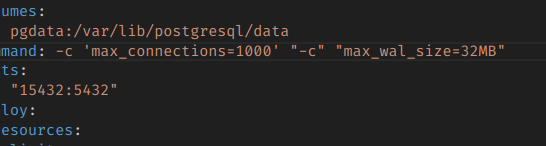
플래그는 max_wal_size다.
32mb로 늘리려면 다음과 같이 설정할 수 있다.
그래서 한번 늘려봤는데
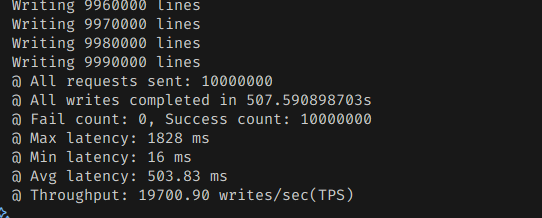 별로 효과적이진 않았다.
별로 효과적이진 않았다.
아예 WAL 쓰기 않기: UNLOGGED
데이터베이스로서의 장점을 내다 버리는 짓이긴 하지만, 아예 WAL을 만들지 않도록 할 수도 있다.
https://blog.naver.com/sssang97/223785210646
DB 파라미터를 조정할 필요는 없고, 테이블 만들때만 키워드를 넣으면 된다.
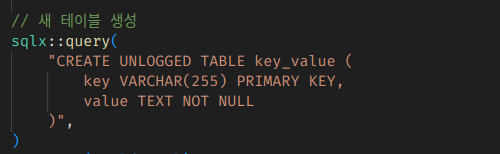
그리고 넣어보면
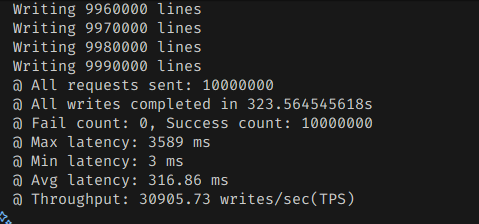 확연하게 쓰기 처리량이 늘어난 것을 볼 수 있다.
확연하게 쓰기 처리량이 늘어난 것을 볼 수 있다.
기본 옵션에 비해서 1.5배 정도는 늘었다.
공유 버퍼 늘리기: shared_buffers
shared_buffers라는 내부 메모리 버퍼가 있다.
이건 WAL과는 관련이 없다.
이 값을 넉넉하게 주면, 테이블의 세그먼트/인덱스 데이터 등을 디스크를 통해 읽고 쓰는 대신, 메모리 버퍼에 놓고 읽고 쓸 수 있게 된다.
보통 이 값은, 전체 메모리의 25% 정도로 설정된다. 8gb면 2gb 정도를 잡고 시작하는 것이다.

 하지만 저 수치는 좀 보수적으로 잡힌 면도 있기 때문에, 메모리가 넉넉하고 처리 요구사항이 높다면, 좀 올리는 것도 좋은 방법일 수 있다.
하지만 저 수치는 좀 보수적으로 잡힌 면도 있기 때문에, 메모리가 넉넉하고 처리 요구사항이 높다면, 좀 올리는 것도 좋은 방법일 수 있다.

 그리고 때려보면 이전보다는 메모리 사용량이 크게 튀는 것을 볼 수 있다.
그리고 때려보면 이전보다는 메모리 사용량이 크게 튀는 것을 볼 수 있다.
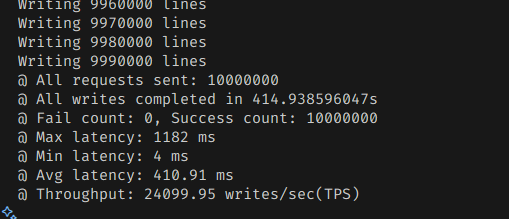 처리량은 그럭저럭 상승했다.
처리량은 그럭저럭 상승했다.
WAL 옵션이 아니고, 메인 디스크에 쓰는 것만 미루는 것이라서, 괄목할만한 향상이 아닌게 당연할 수도 있다.
대충 실험 결과를 정리해보자면, 대체로 적당한 옵션 튜닝을 했을 때는 25000TPS 언저리가 한계고, 내구성을 포기한다면 30000TPS 정도가 한계선이라고 봐야할 것 같다.
참조
https://blog.naver.com/sssang97/223991921550
https://blog.naver.com/sssang97/224039042217