[Qdrant] 벡터 컬렉션 튜닝
벡터 DB는 어떤 구현체든 간에 기본적으로 리소스를 꽤 많이 먹는 시스템이다. 꽤 비대한 벡터 데이터셋에 대해서 전체 인덱스를 구성하고 관리하기 때문이다.
여기서 특히 문제가 되는 부분은 메모리다. 디스크야 좀 커져도 비용적으로나 실제 운영상으로나 늘리는 것이 제법 쉽지만, 메모리는 무제한으로 늘리기 어렵기 때문이다.
그래도 벡터의 차원이 100-200 정도로 작으면 비교적 문제가 적지만, 500, 1000, 2000을 넘어가게 된다면 그 크기가 선형적으로 매우 크게 증가해서 감당하기 어려워질 수 있다.
벡터를 다룰때 리소스를 대강 얼마나 먹는지, 컬렉션 옵션을 어떻게 바꿨을 때 사용량을 얼마나 줄일 수 있는지를 실제 벤치마크를 기반으로 간단히 정리해보겠다.
기준점 설정
baseline을 잡아두고 각 선택지별로 비교를 진행해보겠다.
테스트에 사용한 구성은 512 차원의 Cosine 벡터, HNSW 인덱스를 전부 메모리에 올리는 구성이다.
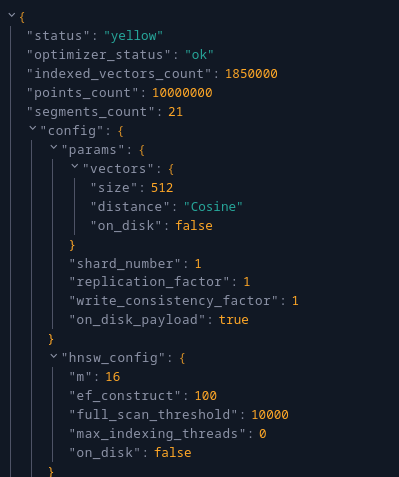 보통 이게 기본값이다.
보통 이게 기본값이다.
정확도와 성능을 전부 최대한으로 잡는 옵션이다.
행은 1000만개 정도만 넣어놨다.
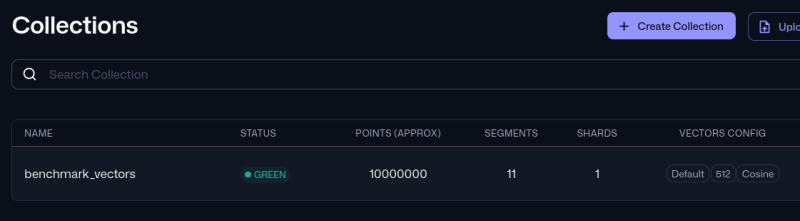
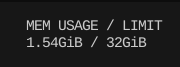 내 경우에는 메모리를 1.5gb 정도 먹었다.
내 경우에는 메모리를 1.5gb 정도 먹었다.
그리고 간단한 Query 벤치마크, 동시에 최대 100개의 쿼리를 날릴 수 있게 했다.
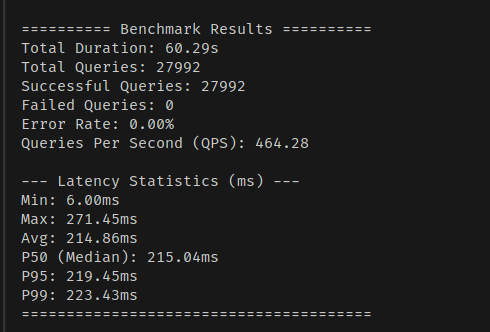 초당 처리량은 400개 정도였다.
초당 처리량은 400개 정도였다.
레이턴시는 밀리초 단위를 유지했다.
On Disk 모드
Qdant의 벡터 컬렉션은 기본적으로 벡터 값과 벡터의 인덱스를 전부 메모리에 올려서 사용한다. 당연히 그게 가장 빠르기 때문이다.
하지만 메모리가 넉넉하지 않고 성능을 약간 포기해도 된다면, 인덱스를 디스크에 올려서 쓰게 하는 것도 가능하다. 이건 on_disk 옵션을 통해 설정할 수 있다.
이건 벡터 저장소와 HNSW, 페이로드 인덱스들에 대해서 개별적으로 적용이 가능하다.
벡터 저장의 경우에는 이렇게 설정할 수 있다.
PUT /collections/{collection_name}
{
"vectors": {
"size": 512,
"distance": "Cosine",
"on_disk": true
}
}여기서 알아둘 점은, on_disk라고 해서 항상 디스크를 통해서만 순진하게 Read/Write를 하는건 아니라는 것이다. 파일에 저장하는 것은 맞지만, memory map을 두고서 처리하기 때문에 OS 디스크 캐시를 잘 활용하고, 생각보다 빠르다.
이건 기존 벡터 컬렉션에 대해서도 즉시 수정이 가능한 옵션에 속한다.
절감 효과는 거의 유의미하게 즉시 나타난다.
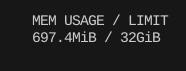 20gb나 먹던 것에 비하면 굉장히 아담하게 줄어든 것을 볼 수 있다.
20gb나 먹던 것에 비하면 굉장히 아담하게 줄어든 것을 볼 수 있다.
그럼 읽기 성능은 얼마나 떨어질까? 동일한 테스트 코드로 벤치마크를 다시 때려봤다.
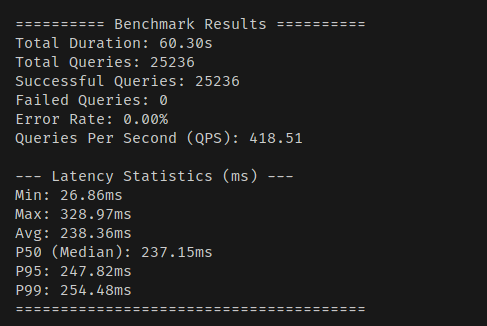 확실히 성능이 저하되는 부분이 있긴 하다. 하지만 그다지 크지는 않다.
확실히 성능이 저하되는 부분이 있긴 하다. 하지만 그다지 크지는 않다.
초당 처리량이 약간 떨어졌고, Max 레이턴시가 약간 증가했다.
하지만 전체적으로는 치명적인 수준의 성능 저하는 보이지 않는다.
최대한의 레이턴시를 목표를 하는게 아니라면, 비용 합리적인 선택이 될 수 있을 것 같다.
메모리 사용량이 절감되는 것에 비해 성능 저하가 미미하다.
HNSW 인덱스도 디스크에 저장하게 하는 것이 가능하다.
마찬가지로 on_disk 옵션을 주면 된다.
PATCH /collections/benchmark_vectors
{
"hnsw_config": {
"on_disk": true
}
} 이건 벡터 말고, 벡터의 그래프 자체를 디스크에 저장하게 한다.
이건 벡터 말고, 벡터의 그래프 자체를 디스크에 저장하게 한다.
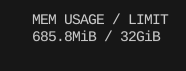 메모리 사용량이 눈에 띄게 줄어들지 않는다. 의미가 거의 없는 수준이다.
메모리 사용량이 눈에 띄게 줄어들지 않는다. 의미가 거의 없는 수준이다.
그래프 구조 자체는 벡터 데이터셋에 비하면 크기가 의미있는 정도가 아니기 때문인 것 같다.
Read 성능 악화는 눈에 띄는 수준까지 발생한다.
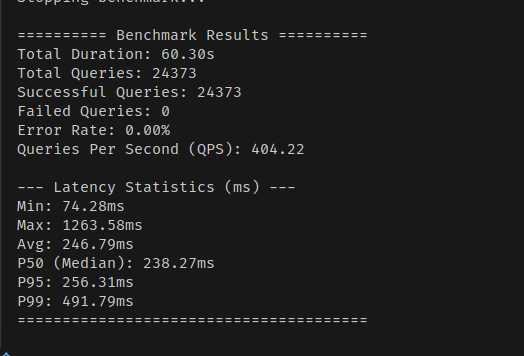 처리량 자체는 크게 떨어지지 않으나, 레이턴시가 심각하게 튄다.
처리량 자체는 크게 떨어지지 않으나, 레이턴시가 심각하게 튄다.
이 옵션은 추천할만한게 아닌 것 같다.
Flaot32 => Float16
여기서부터는 정밀도를 희생하고 성능을 가져가는 방법들이다.
Qdrant 벡터의 기본 저장 타입은 Float32이다. 각 벡터 요소를 4바이트 부동소수점을 저장한다는 것이다.
하지만 약간의 손실을 허용할 수 있다면, 2바이트 부동소수점을 사용해서 저장하는 것도 쓸만한 방법이다.
이 방법은 정밀도가 손실되긴 하지만, 양자화에 비하면 그 정도가 심하지 않아서 시도해볼만하다.
이걸 적용할여면, 컬렉션을 생성할때 데이터타입을 float16로 지정해주면 된다.
PUT /collections/{collection_name}
{
"vectors": {
"size": 512,
"distance": "Cosine",
"datatype": "float16" // <-- For dense vectors
}
}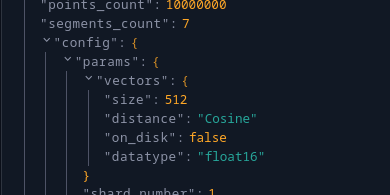 벡터 저장 타입이 바뀌기 때문에 당연히 기존 컬렉션을 변경할 수는 없고, 새로 만들어야 한다.
벡터 저장 타입이 바뀌기 때문에 당연히 기존 컬렉션을 변경할 수는 없고, 새로 만들어야 한다.
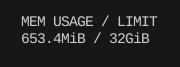 메모리 사용량은 매우 극적인 수준으로 떨어졌고
메모리 사용량은 매우 극적인 수준으로 떨어졌고
속도와 처리량도 매우 빨라졌다.
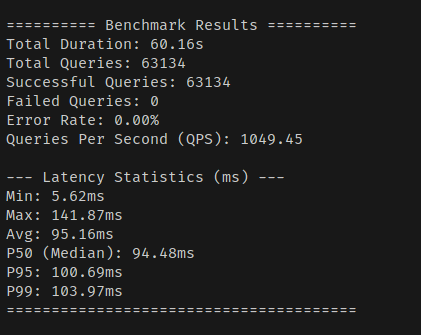 처리량이 2배 이상 늘었고, 레이턴시도 2배 정도 줄어들었다. 매우 직관적인 향상이다.
처리량이 2배 이상 늘었고, 레이턴시도 2배 정도 줄어들었다. 매우 직관적인 향상이다.
부동소수점의 자릿수가 짧거나, 약간의 정밀도 손실을 감수할만하다면 시도해볼만한 방법이다.
Float16 + On Disk
내가 볼때 On Disk 옵션까지 동시에 주면 약간의 손실만 허용하면서 최적의 비용/성능 균형을 잡을 수 있다.
다음은 Float16 + Vector On Disk을 주고 돌렸을 때의 메모리 사용량/벤치마크다.
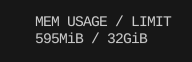
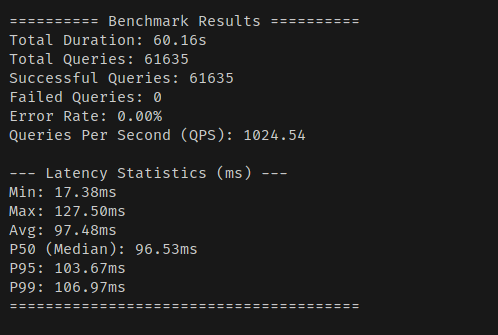 매우 안정적이다.
매우 안정적이다.
Float32 => UInt8, 그리고 양자화
이건 리스크가 매우 크고 급진적인 최적화 방법이다.
정밀도 손실이 매우 커서 많은 사례에서 유효하지 않을 수 있고, 충분한 이해와 실험이 밑바탕이 되어야 한다.
부동소수점 대신 0-255 범위의 1바이트 정수 값을 쓰고, 부동소수점을 정수로 변환하는 양자화 과정을 거쳐서 값을 집어넣는 것이다.
여기에는 2가지 방법이 있다.
-
벡터의 저장 타입을 Uint8로 못박아놓고, Client가 양자화를 직접 처리해서 넣는 방법
-
벡터의 저장은 Float로 저정하고, 양자화 옵션을 사용해서 Qdrant 내부에서 처리하는 방법
비용 효율성은 1번이 가장 훌륭하나, 양자화로 인한 정밀도 손실을 보전할 방법이 전혀 없다는게 단점이다.
2번을 선택한다면 양자화된 벡터를 사용하면서도 원본 벡터까지 사용해서 tradeoff를 조정하는 미세한 테크닉을 사용할 수 있다.
자세한 내용들은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/223848217468
이건 2번 선택지, 자동화된 양자화에 대한 참조다.
https://blog.naver.com/sssang97/223850564577
스칼라 양자화를 0.99 비율로 넣어봤다.
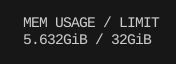 생각보다는 효율성이 그리 좋지는 않았다.
생각보다는 효율성이 그리 좋지는 않았다.
적당히 옵션을 주면, 벡터도 메모리에 띄우고, 양자화된 벡터도 메모리에 띄우기 때문이다.
그래서 메모리 사용량을 줄이러면 벡터는 on_disk로 두고, 양자화된 벡터만 메모리에 띄우게 하거나 해야 한다.
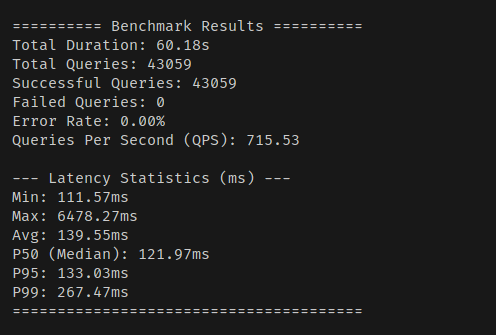 읽기 처리량은 생각보다 좋지 못했다. Float32보다는 빠르지만, Float16보다는 느렸다.
읽기 처리량은 생각보다 좋지 못했다. Float32보다는 빠르지만, Float16보다는 느렸다.
그리고 Max Latency는 생각보다 심각하게 튀었다.
이건 또 왜이리 애매하게 나오는 건지 모르겠다. 양자화 변환 시간이 레이턴시에 크게 포함된 건가?
참조
https://qdrant.tech/documentation/concepts/vectors/#datatypes
https://qdrant.tech/documentation/concepts/storage/#vector-storage