프로그램 최적화 가이드
 프로그램의 성능을 최적화하는 것은 고려해야하는 요소나 관점이 매우 다양하고, 변수도 늘 많다.
프로그램의 성능을 최적화하는 것은 고려해야하는 요소나 관점이 매우 다양하고, 변수도 늘 많다.
그래서 엔지니어의 역량을 판가름하는 주요 지표 중 하나가 되곤 한다.
여기에서는 최적화에 대한 주요 관점들, 기반지식들, 접근 방식들을 대략적으로나마 다뤄본다.
시간복잡도 기반으로 알고리즘 최적화하고 그런건 다루지 않는다. 이건 그냥 문제풀이 사이트 같은 곳에서 훈련하면 된다.
성능 지표와 Tradeoff
성능을 최적화하려면, 우선 뭘 최적화하려는 것인지부터 선택해야 한다.
대표적인 지표로는 다음과 같은 것들을 꼽을 수 있을 것이다.
- 실행속도 (혹은 Latency)
- 처리량 (Throughput)
- CPU 사용량
- 메모리 사용량
- 디스크 사용량
- I/O 사용량
- 실행파일 크기
항상 모든 것을 다 가져갈 수는 없기 때문에, 우리에게 필요한 성능이 무엇인지를 알고, 나머지를 적절히 포기할 줄도 알아야 한다.
그래서 최적화에서 가장 중요한 것은 적절한 Tradeoff를 잡는 것이다.
예를 들면, 일반적인 클라이언트 프로그램들의 경우에는 실행속도와 메모리 사용량이 중요하고, 나머지는 상대적으로 중요성이 낮다.
반면 서버사이드 프로그램의 경우에는 7번을 제외한 거의 모든 것을 다 고려해야 한다.
실행속도나 처리량이 가장 중요한 케이스라면, CPU와 메모리를 영끌해서 다 미리 로드하고, CPU 코어를 최대한으로 조져서 처리하는 것이 가능하다.
이건 일회성 Batch 프로세스나 데이터 파이프라인처럼 짧은 수명과 낮은 가용성이 허용되는 경우에 유효하다.
반면 안정성이나 가용성이 중요한 경우라면, 적정선을 잡는 것이 중요하다.
CPU/메모리 사용량을 우선으로 잡고, 실행속도와 처리량은 기본적인 정도만 유지하게 하는 것이 일반적인 관점이 된다. 대부분의 API 서버 시스템이 여기에 해당된다.
I/O 사용량은 보통 우선적으로 고려할 대상은 아니지만, 플랫폼이나 하드웨어 기반에 따라서 큰 성능 제약이 될 수 있는 부분이다.
AWS 같은 클라우드를 사용할 경우에는 디스크 I/O 단위에도 비용을 부과하고 스로틀링을 걸며, 네트워크 데이터 전송량이 커질수록 비용을 더 뜯는다. 비용적인 연관성이 커진다.
그리고 클라우드가 아니라도, 사용 패턴에 따라서는 Disk I/O로 인한 디스크 압박이 문제가 될 수 있다. 디스크 접근은 생각보다 비싸고 느린 자원이다.
실행 파일의 크기도 은근히 중요한 부분 중 하나다. 임베디드와 웹브라우저-스크립트가 실행파일 크기에 영향을 받는 대표적인 사례다.
- 임베디드 시스템의 경우에는 심한 하드웨어 제약 때문에 실행파일을 강제로 줄여야 한다.
- WEB-Frontend 시스템의 경우에는 실행파일(Javascript)이 작을수록 빠르게 로드되고, 그에 따른 사용자 체감 성능 차이가 꽤 많이 난다. 그래서 보통은 번들링을 통해서 Javascript 파일을 작게 압축해서 사용하곤 한다.
연산별 응답지연 시간
시스템을 효과적으로 작성하고 최적화하려면, 어떤 연산들이 대강 어느 정도로 걸리는지 알아두긴 해야한다.
예전에 구글에서 정리한게 있다. 좀 오래된 자료라서 지금 성능과는 괴리가 있을 수도 있는데, 그래도 대략적인 지표로는 참고할만하다.
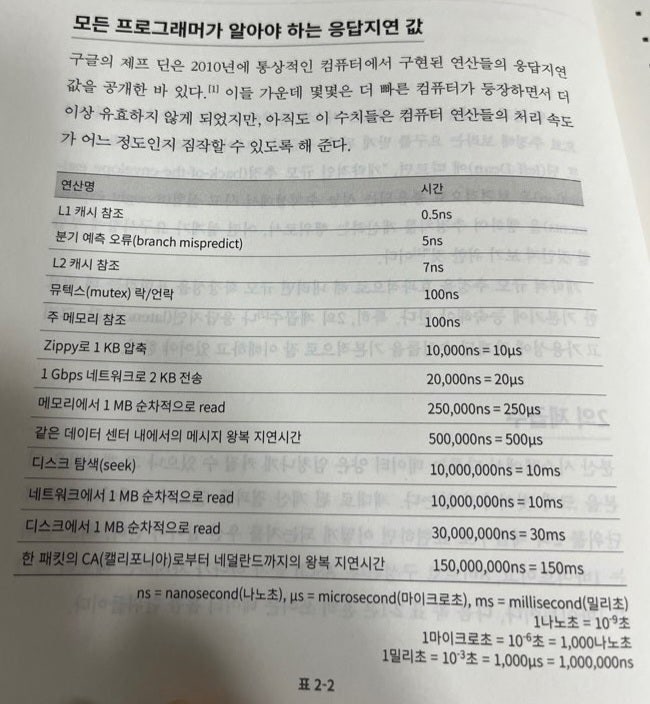 일단 중요한 것은, 일반적인 CPU 내 작업은 어지간해서 나노초 단위라는 것이다.
일단 중요한 것은, 일반적인 CPU 내 작업은 어지간해서 나노초 단위라는 것이다.
그래서 연산 한두개 빼는건 대부분 큰 의미가 없다.
보통 문제가 되는건 디스크 I/O나 네트워크 I/O다. 밀리초 단위가 기본이다.
이 말인즉슨, 가장 큰 성능 병목이 I/O에서 발생하고, 주요 최적화 지점도 I/O가 될 확률이 높다는 것이다.
관측 가능성(Observability)과 최적화 지점 판단
성능을 최적화려면, 어떤 부분에서 얼마나 걸리고 얼마나 리소스를 점유하는지 측정하는 것이 우선이 되어야한다.
그냥 느낌적으로 "이게 더 빠를 것 같으니까" 고친다는 것은 유효하지 않을 때가 많다.
항상 중요한 것은 실제 병목지점을 파악하고 고치는 것이다. 이상한 마이크로 최적화가 아니라.
예를 들어 DB Query 조회에 500ms가 걸리는데, 나노초 단위로 처리되는 후처리 코드를 최적화하는 것은 대부분의 경우 아무런 의미가 없는 짓이다. 영향 범위를 파악하고 진짜 문제를 찾아서 최적화를 해야 한다.
그런 맥락에서 서버사이드 애플리케이션의 경우에는 모니터링 스택을 사용해서 운영 상황에서의 관측성을 확보하는 것이 꽤 중요하다.
https://blog.naver.com/sssang97/223478540289
언어별 차이
가끔 보면 언어는 도구에 불과하다고 하면서 언어의 중요성을 평가절하하는 경우가 많은데, 실제로 성능 관점에서는 엄청나게 큰 영향을 준다.
순수하게 어떤 언어를 선택하는지에 따라서 처리량이나 리소스 사용량이 수십-수백배는 차이가 나는 경우가 드물지 않기 때문이다.
물론 이건 시스템이 맡은 역할이 어느 정도인지에 따라 달라진다.
만약 단순한 API 서버를 구현할 뿐이고, 서버에 heavy한 로직이 없으면서 대부분의 핵심 동작이 데이터베이스에 위임되어 있다면. 그건 사실 Python을 쓰든 PHP를 쓰든, Rust를 쓰든 눈에 띄는 큰 차이는 없을 수 있다.
언어에 따른 성능 편차가 크게 벌어지는 경우는 무거운 연산이 많이 포함되어있거나, 메모리 압력이 심하거나, 매우 높은 동시 처리 능력이 요구되는 경우 등이다.
**a. 컴파일 언어와 인터프리트 언어 **
언어의 성능-특히 실행속도-을 결정짓는 가장 큰 요소는, 언어의 실행 결과물이 순수한 실행파일로 나오는지, 아니면 해당 언어의 인터프리터(가상머신)에서 실행되는지다.
대개 가장 빠른 종류는 컴파일 언어이면서도 최적화 수준이 괜찮은 언어다.
C/C++, Rust, Go 등이 여기에 속한다. 다만 컴파일 언어라고 다 빠른건 아니다.
그리고 코드가 인터프리터로 실행되면 당연히 직접 CPU 인스트럭션을 때리는 것에 비해서 현저하게 느리다. Ruby, Python, Node.js 같은 언어들이 이런 느림보 분류군에 속한다.
여기에도 회색지대가 있다. 구현 수준이 높은 인터프리터 언어들은 태생적인 단점을 극복하기 위해 JIT 기반 최적화 시스템을 내장한다. 스크립트의 함수를 실제 바이너리로 컴파일해서 섞어쓰는 것이다.
해당되는 언어는 Java, C# 정도가 있다. 이외에도 JIT을 구현하는 언어들이 더 있긴 하지만, 컴파일 언어에 비빌 정도로 최적화를 잘 해주는 언어는 이 둘 정도 밖에 없다.
**b. GC와 non-GC 언어 **
GC는 약간 복잡한 성능 요인이다. GC가 있다고 해서 성능적으로 항상 나쁜 것은 아니지만, 마냥 긍정적인 영향이 있는 것도 아니다.
다만 중요한 것은 GC 달렸다는 것 자체로 속도 자체가 무조건 느려지는건 아니라는 것이다.
GC가 부착됨으로 인해서 발생할 수 있는 성능 손실은 다음과 같다.
-
GC Stop으로 인한 일시적인 성능 지연-멈춤 (구현에 따라 길면 초 단위)
-
GC가 더디게 처리됨으로 인해서 메모리 사용량이 실제 사용량보다 튀는 메모리 스파이크
-
GC로 인한 CPU 코어 사용량 증가
반면 성능 이점을 가져갈 수 있는 부분도 있다. 대표적인 부분은 메모리 할당에 대한 부하를 줄일 수 있다는 것이다.
대부분의 GC 언어는 런타임에 자체적인 메모리 풀을 두고서 메모리 재사용을 제법 잘 하기 때문에, 시스템 수준 메모리 할당이 줄어들 수 있다.
그래서 GC 언어는 메모리 할당 성능에 대한 저점이 비교적 높다. 물론 이것도 메모리 스파이크 위험과 tradeoff가 되는 부분이긴 하다.
**c. 그냥 느린 언어 **
다음 목록은 성능이 중요하다면 1차적으로 배제해야 하는 언어다.
- erlang/elixir는 메이저한 언어 중에서도 타의 추종을 불허할 정도로 느린 연산 성능을 자랑한다.
- 컴파일 언어인데도 순수하게 최적화 수준이 딸려서 느린 경우도 있다. Haskell이 대표적이다.
FFI (Foreign Function Interface)
종종 언어의 한계로 인해서 최적화의 벽에 막힐 때가 있다.
특히 Node.js와 Python 같은 언어들이 더욱 그러한데, 속도가 느린 것이 문제가 될 수도 있고, 메모리를 무식하게 먹는 것이 문제가 될 수도 있다.
이런건 언어의 근본적인 한계인지라. 부분적으로라도 해결하려면 결국은 C/C++, Rust 같은 언어로 컴파일해서 그 외부 모듈을 Node.js/Python 등에서 끌어다가 쓰는 식으로 진행을 하게 된다. 이렇게 언어를 교차해서 사용하는 것을 FFI라고 부른다.
컴파일이나 실행 문제가 복잡해질 수 있지만, MSA랍시고 서버 단위로 분리하고 연동하는 것에 비해서는 더 빠르고, 관리포인트가 적고, 결과적으로 저렴한 방법이다.
요즘은 Rust에 Node.js/Python에 한해, 상호운용성을 위한 에코시스템이 제법 잘 되어있는 편이다.
https://blog.naver.com/sssang97/223072977222
https://blog.naver.com/sssang97/223103102724
서버와 데이터베이스
대부분의 서버 시스템들은, 그 성능이 데이터베이스 수준에서 상당수 결정된다.
그래서 데이터베이스를 잘 선택하고, 잘 설계해서 구현하는 것이 매우 중요하다고 할 수 있겠다.
특히 중요한 것은 인덱스의 동작 방식에 대한 이해, 카디널리티와 데이터 분포, 스캔에 대한 성능 이해다.
예를 들어, Row Based Database - OLTP 데이터베이스들의 경우에는 대형 데이터셋에서 매우 적은 일부만 스캔하는 것에 대해서 훌륭한 성능을 보인다.
하지만 매우 높은 비율을 필터링하거나, 필터링 조건이 복잡한 경우에는 순진하게 동작하지는 않는다.
https://blog.naver.com/sssang97/223981993212
https://blog.naver.com/sssang97/223828946151
대척점에 있는 Column base Database들의 경우에는 데이터를 컬럼 단위로 분리해서 저장하고 인덱싱하기 때문에, 카디널리티가 낮거나 복잡한 컬럼 필터링에 대해서 훨씬 나은 성능을 보여준다.
서비스용 DB로서는 대표적으로 Elasticsearch가 여기에 속한다.
좀 더 극단으로 가면 Clickhouse 같은 OLAP DB가 있는데, 이건 전체 데이터 통계를 위한 것이라서, 항상 대부분의 데이터 블록을 스캔하는 식으로 접근해버린다.
https://blog.naver.com/sssang97/223652951126
당연하지만 여기에도 tradeoff는 있다.
Column base Database들이 필터링 성능이 좋긴 하지만 대체로
트랜잭션이나 데이터 반영, 유일성 등에 대한 보장 수준이 떨어지는 편이다. 그래서 메인 DB로는 Row Based Database를 우선 선택하는 편이 권장된다.
캐시
사용량이 늘고 요구사항에 맞춰서 최적화를 하다보면, 결국 어느 지점에서는 캐시 레이어들을 활용해야 하는 순간들이 온다.
핵심 원리는 "자주 사용되는 데이터"에 대해서 미리 저장해놓고 최소한의 리소스로 제공한다는 것이다.
이를 통해 속도와 처리량 등을 최적화할 수 있다.
자세한 내용은 별도 포스트를 참조하길 바란다.
https://blog.naver.com/sssang97/224067483517
동시성 최적화
동시성은 성능 최적화에 있어서 가장 중요한 부분 중 하나다.
단일 머신의 성능에는 한계가 있기 때문에, 종국에는 멀티코어를 활용해서 처리량과 최대성능을 끌어내야 한다.
여기에는 2가지 분기점이 있다.
I/O 집약적인 경우라면 실제 코어를 많이 쓰지 않더라도, 시분할 기반의 가짜 스레드로도 괜찮은 처리 성능을 가져갈 수 있다. 이건 대개 처리량에 대한 최적화로 이어진다.
반면 실제로 CPU 집약적인 부분이 많은 사례라면 진짜 스레드를 활용해야 한다. 이건 실행속도에 대한 최적화로 이어진다.
이 2가지에 대한 적절한 절충안으로서 존재하는 것이 경량 스레드라는 것이다.
https://blog.naver.com/sssang97/223918683800
자세한 것은 별도 포스트를 참조한다.
그리고 동시성에 있어 중요한 것 중 하나가 데이터에 대한 동기화다.
동기화 수단으로 무엇을 쓸 것인지에 따라서 실제 성능 상한이 올라간다.
일반적인 경우에는 Mutex 같은 futex 구현체를 권할만하다. 성능과 리소스의 균형을 최적으로 잡는다.
하지만 강력한 Lock이 필요하지 않거나, 코어가 많아서 CPU 좀 갈궈도 된다면 CAS 같은 atomic operation을 기반으로 동기화를 처리하는 것이 훨씬 효율적이거나 성능 상한을 올릴 수 있다.
https://blog.naver.com/sssang97/223126307890
하드웨어 한계와 병렬처리
일반적인 사이즈의 연산을 할 때는 단일 머신에서 멀티코어를 갈구는 것으로도 충분하다.
하지만 결국, 단일 장비, 단일 머신에서 발휘할 수 있는 연산력에는 분명한 한계가 존재한다. 어느 시점에서는 단일머신을 넘어선 복잡한 교차 처리가 필요해지는 순간이 온다.
예를 들어, 가장 먼저 맞닥뜨릴 수 있는 한계는 디스크 성능의 한계다. 디스크는 생각보다 느리고 처리량도 저조한 부위다. 그래서 디스크 I/O가 병목이 된다면 하나의 컴퓨터에 2개 이상의 디스크를 연결해서 사용하는 것도 흔한 사용패턴이 되곤 한다.
데이터베이스들의 경우에도 멀티 볼륨을 통해 사용량을 최적화하는 것을 공식적인 최적화 방안으로 권장한다.
그리고 디스크뿐만 아니라 단일머신에서의 전반적인 한계에 부닥치면, 결국은 여러개의 서버를 연결해서 사용하는 방식을 취하게 된다. 이것이 분산시스템이다.
단일머신에 집적할 수 있는 코어 수에는 한계가 있을뿐더러, 항상 코어의 개수에 비례해서 성능이 향상되는 것도 아니다. 코어가 Memory에 동시에 접근하는 것 자체부터가 성능 병목이 된다. Disk의 접근 성능도 한계가 있고, Disk에 저장할 수 있는 데이터의 크기도 한계가 있다. 멀티 Disk를 구성하더라도 하나의 머신에 디스크를 무한으로 꼽을 수는 없다.
분산시스템과 분산형 DB들이 사용되는 이유에는 가용성도 있지만, 이런 한계를 벗어나기 위한 것도 있다.
메모리 할당
메모리 할당이란 것은 생각보다 굉장히 무거운 작업이다.
GC 언어를 쓴다면 메모리 풀링과 재사용을 해주니 덜하긴 하지만, 그렇다고 해서 가벼운 작업이 되지는 않는다.
그래서 값을 할당할 때는 확실히 필요한 만큼을 미리 할당해서 할당이 빈번하지 않게 만들고, 적당히 재사용할 수 있게 해주는 것이 중요하다.
이 이야기는 컬렉션 응용 수준에서도 이어진다.
배열이나 Hashmap 등을 쓸 때 capacity 지정도 없이 빈 객체로 만들고 때려넣는 경우가 많은데, 이런 것도 안티 패턴인 할당 남용이다. 이런 객체의 무분별한 growth 유도는 재할당으로 인한 성능 저하를 일으킨다.
특히 Hashmap의 경우에는 해싱 동작 때문에 growth가 심해질 경우 CPU 부하도 굉장히 크게 늘어난다.
네트워크 I/O
서버 시스템을 운영하게 된다면, 네트워크 전송도 중요한 최적화 포인트 중 하나가 된다.
2가지 관점에서 최적화를 바라볼 수 있을 것 같다.
-
레이턴시
-
데이터 전송량
네트워크 전송은 소프트웨어 시스템의 계층 중에서 가장 느리고 안정성도 떨어지는 부분이다.
지역에 따라서는 200-400ms의 지연이 발생하는 것도 흔하기 때문에, 네트워크 I/O는 빈도가 적고 짧을수록 좋다.
1차적으로는 CDN 캐시나 로컬 컴퓨터 캐시를 최대한 활용하고, 여러개의 ping-pong API 처리를 하나의 API로 묶을 수 있다면 그렇게 하는 편이 레이턴시 최적화 측면에서도 좋다.
데이터 전송은 속도도 속도지만, 보통은 비용적인 부분도 있다. 데이터 전송량에 따라서 실제로 부과되는 비용이 상승하기 때문이다.
HTTP라면 gzip 같은 압축포맷을 사용해서 데이터 전송을 압축해서 최적화할 수 있고, gRPC를 쓴다면 protobuf를 활용해서 데이터 전송량을 컴팩트하게 줄일 수 있다.
디스크 I/O
메모리는 CPU보다 느리지만, 디스크는 그보다 훨씬 압도적으로 느린 자원이다.
그래서 큰 데이터를 파일 기반으로 핸들링한다면 디스크 액세스를 최소화하는 것이 주요 최적화 관점이 된다.
a. 압축
가장 일반적인 최적화 방법은 압축이다.
디스크에 읽고 쓸 파일의 크기가 크다면, 압축을 하는 것이 효율적일 경우가 많다.
압축/해제로 인해서 CPU+메모리 사용량이 늘겠지만, 일단 디스크에서 읽고 쓰는 크기가 작아지니 결과적으로 빠르고 저렴해진다.
대표적인 사용 사례는 parquet로 빅데이터를 압축-분할해서 저장하는 것이다. parquet 자체가 이런 용도의 저장 형식이다.
대부분의 오픈소스 데이터베이스들도 데이터 세그먼트를 최대한 작게 압축해서 저장하거나, 저장하는 옵션을 제공한다.
예를 들어, clickhouse의 경우에는 약 1만개의 행을 하나의 블럭(granule) 단위로 압축 저장한다. 이를 통해 디스크 접근 효율을 극대화하는 것이다.
b. 중간 메모리 계층 활용하기
우리가 사용하는 파일 쓰기/읽기 함수들은 사실 디스크에 즉시 접근하는 것은 아니다. OS에서 파일캐시를 두고서 가급적 메모리를 통해서 동작하게 최적하해주기 때문이다.
하지만 그보다도 더 빠른 방법이 있다. memory map과 같은 중간과정 없는 파일 로딩 방법을 사용하는 것이다.
https://blog.naver.com/sssang97/223479875946
Zero-Copy
이건 위에서 사용한 디스크 I/O 최적화와도 연관점이 있다.
최적화를 하는 주요 접근법 중 하나는, 불필요한 복사를 줄이는 것이다.
가벼운 스칼라 데이터라면 몇번을 복사하든 별 의미가 없지만, 크기가 좀 클 수 있는 문자열 같은 타입들의 경우에는 복사 한번 하고 말고로 적지 않은 컴퓨팅 리소스를 소모할 수 있다.
그래서 가능하다면 복사보다는 move나 forwading의 형태로 값을 전달해서 사용하는 것이 좋다.
그리고 이건 커널 레벨 syscall에서도 공통적으로 적용되는 부분이다.
자세한 내용은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/223629674161
배열과 캐시, 자료구조
자료구조-알고리즘-을 잘 사용하는 것도 중요하다.
대형 데이터셋에 대해서 빈번한 고속-부분 접근이 필요하다면 O(log N)의 Tree 구조나 O(1)의 해시테이블 구조를 잘 응용하는 것이 매우 중요해진다.
하지만 많은 사람들이 간과하는 것 중 하나가, 배열은 생각보다 엄청나게 빠르다는 것이다.
https://blog.naver.com/sssang97/223422783855
그래서 데이터 세트가 수백이나 수천 미만으로 그렇게 크지 않거나, 크더라도 데이터 전체 접근 처리가 빈번하다면 배열을 쓰는 것이 압도적으로 빠를 수 있다. 이런건 사용 패턴을 잘 보고 판단해야 한다.
병렬 연산: SIMD
요즘 각광받는 최적화 접근 방식 중 하나가 SIMD를 통해 병렬연산을 하는 것이다.
이건 CPU 레벨에서, GPU가 해주는 것처럼 여러개의 배열 연산을 단일 인스트럭션으로 처리해준다.
이를 통해 여러개의 연산이 동시에 일어날 수 있는 상황에서는 최대 수십배의 실행속도 향상을 가져올 수 있다.
https://blog.naver.com/sssang97/223322281259
단점은 많은 컴파일 언어들에서 안정화되지 않은 기능이라는 것이다.
Instruction Level
데이터베이스나 네트워크 수준을 떠나서, 실제 컴파일러와 CPU의 동작 원리를 어느정도 알아야 제대로 최적화가 가능한 부분들도 존재한다.
https://blog.naver.com/sssang97/223940931299
https://blog.naver.com/sssang97/223942222903
https://blog.naver.com/sssang97/223937776756