[DDD] bounded context와 엔티티의 공유
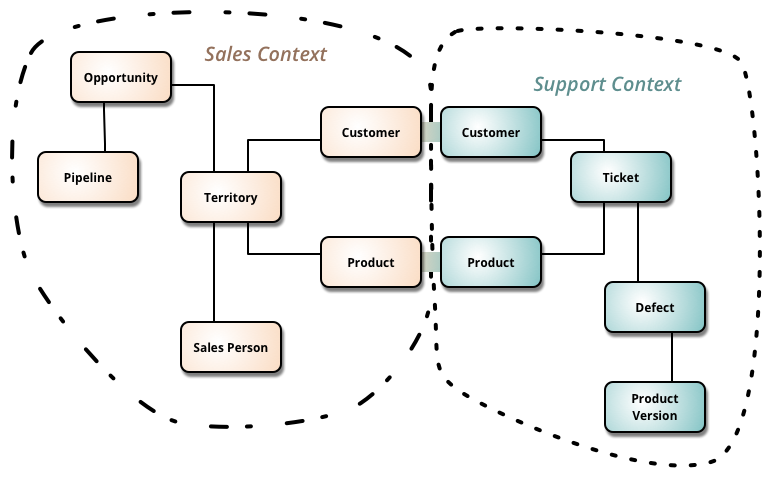 DDD는 기본적으로 도메인 단위의 격리를 통해 유지보수 안정성을 끌어올리기 위한 방법론이다.
DDD는 기본적으로 도메인 단위의 격리를 통해 유지보수 안정성을 끌어올리기 위한 방법론이다.
그래서 각각의 도메인 영역을 "bounded context"라는 격리된 영역으로 정의하고, 가능하면 bounded context 내에서만 비즈니스 로직이 작동하도록 하는 것이다.
예를 들어 다음 프로젝트는 "reservation"과 "user"라는 도메인 영역을 정의하고, 폴더 수준에서 소스코드가 격리되는 형식을 취한다.
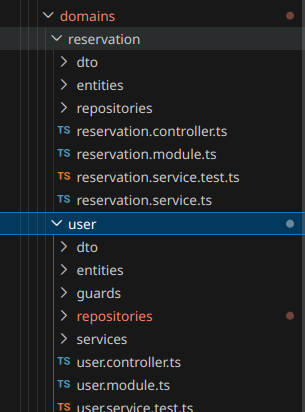
근데 실제 비즈니스 로직에서는 도메인을 분리한다는게 말처럼 쉽지만은 않다. 당장 User 같은 핵심 데이터만 해도, 실제 로직을 작성하다보면 오만 도메인에서 다 땡겨써야 한다.
이런 여러 도메인에 걸친 공유 데이터-테이블 단위가 생기면 어떻게 해야할까?
여기에는 3가지 정도의 접근 방법이 존재한다.
Shared Kernel
가장 단순한 방법은, 그냥 여러 도메인에서 돌려쓸 수 있는 공유 영역을 정의해서 쓰는 것이다.
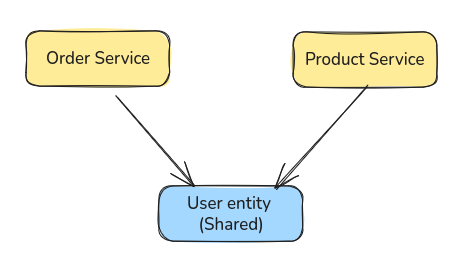 서 쓰는 것이다.
서 쓰는 것이다.
그냥 utils 같은 것이라고 보면 된다. 그 이상도 이하도 아니다.
특정 도메인에 종속되지 않는 - 매우 범용적인 로직 공유에 있어서는 매우 일반적인 방법이다.
Customer-Supplier 구조
또 하나의 방법은, 도메인끼리 단방향 통신을 할 수 있도록 구성하는 것이다.
더 구체적으로 말하면, A 도메인 서비스가 B 도메인의 서비스 함수를 호출하는 식으로 만들 수 있다.
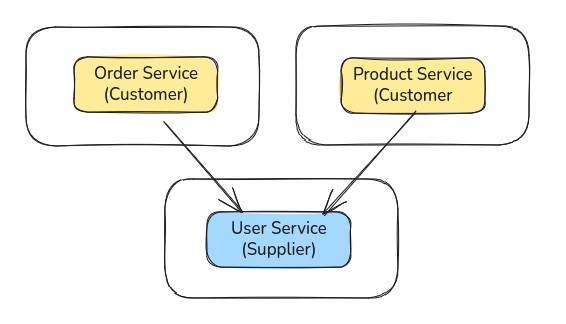
매우 직관적인 방법이긴 하나, 단점도 있다.
일관된 규칙 없이 남용하게 된다면 언어나 프레임워크에 따라서 순환 종속성 문제를 유발할 수 있고, 도메인 영역을 침범함으로 인해서 의도치 않은 부작용을 야기할 수도 있다.
그래서 대략적인 주의사항은 다음과 같다.
-
다른 도메인의 Service를 호출해서 사용하되, 다른 도메인의 Repository를 호출해서는 안된다.
-
단방향 구조를 유지해서 순환참조 문제가 발생하지 않도록 해야 한다. 그래서 Supplier가 될 수 있는 Core 도메인과, Customer가 될 수 있는 Supporting 도메인들을 좀 명확히 정의해서 역류가 일어나지 않도록 초기 설계를 잘 잡아야 한다.
Separate Way
마지막 접근법은, 그냥 도메인끼리 각자의 길을 걷도록 선을 긋는 것이다.
그 어떤 코드 수준의 상호 호출도 있으면 안된다.
도메인별로 팀이 분리되어있고, 서로 침범하는 것을 엄격하게 막아야할 정도로 업무가 구분되어있다면 이 방법을 선택하게 된다.
그리고 실제 서버 수준에서도 별도로 실행될 가능성이 높다. 그래서 대개는 MSA로 이어지곤 한다.
이 상황에서 도메인 간 공유 지점이 존재할 경우에는 공유가 필요할 경우에는 상호 API 호출이나 이벤트 버스 등을 통해 로직을 공유해야 하는 것이 일반적인 접근법이 된다.
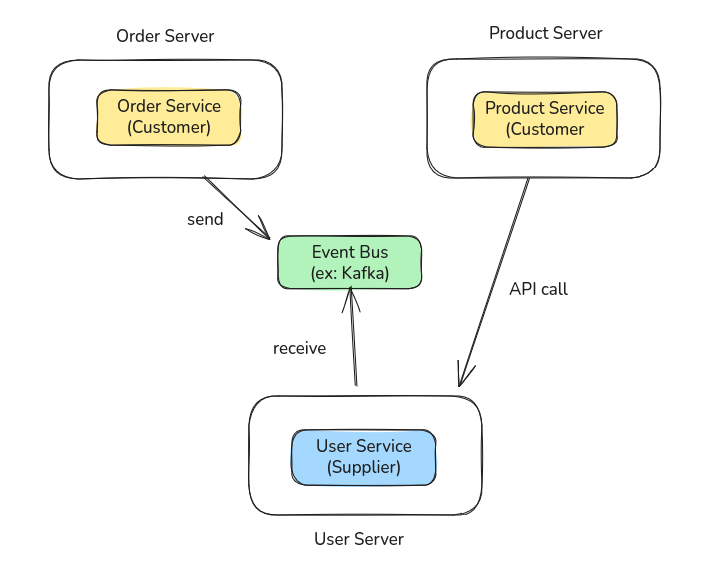
참조
https://www.martinfowler.com/bliki/BoundedContext.html
https://stackoverflow.com/questions/75571559/how-to-set-relationship-between-entites-in-clean-architecture