벡터 검색과 SIMD
그냥 간단한 성능 실험 기록이다.
벡터 검색에서 수행하는 주된 연산인 벡터 유사도 계산은 생각보다 무거운 연산이다. 벡터의 모든 요소를 순회하면서 돌기 때문에, 벡터의 차원(길이)가 커지면 커질수록 정비례해서 부하가 커지고 느려진다.
심지어 대형 모델을 쓰는 고품질 벡터 연산의 경우에는 1500, 3000 등이 넘는 차원을 다루는 일도 비일비재하다. 벡터 DB가 근사치 검색을 수행하면서 많은 리소스를 요구하는 것도 본질적으로는 이런 이유 때문이다.
SIMD
그리고 이런 최적화 주제에 단골처럼 나오는 것이 연산 단위의 병렬화-SIMD다.
SIMD는 이런 사례에 잘 들어맞는 최적화 기법이다. ML에서 사용하는 병렬 연산이 GPU의 무식한 코어 개수로 밀어붙이는 병렬 연산이라면, SIMD는 CPU 수준에서 적당히 말아서 제공하는 가벼운 병렬 연산이다.
SIMD는 GPU 만큼의 압도적인 화력은 없지만, 오히려 이런 적당한 사용사례에서는 GPU보다는 CPU 내의 병렬연산을 활용하는 것이 훨씬 빠를 수 있다. GPU 연산은 하나하나가 꽤 큰 오버헤드를 유발하기 때문이다. CPU<>GPU 전송을 포함해서 이런저런 부하 지점들이 존재한다.
그런 이유들에서 벡터 연산의 단위가 수백만 단위는 되어야 GPU의 병렬 연산 속도가 이런 오버헤드를 압도한다. 딱 그런 지점이 머신러닝 분야인 것이고...
Rust의 std SIMD 기능을 사용해서 전후 비교를 단순하게 해보겠다.
테스트에 사용한 벡터는 512차원, 10000개 정도에, dot product 연산을 돌렸다.
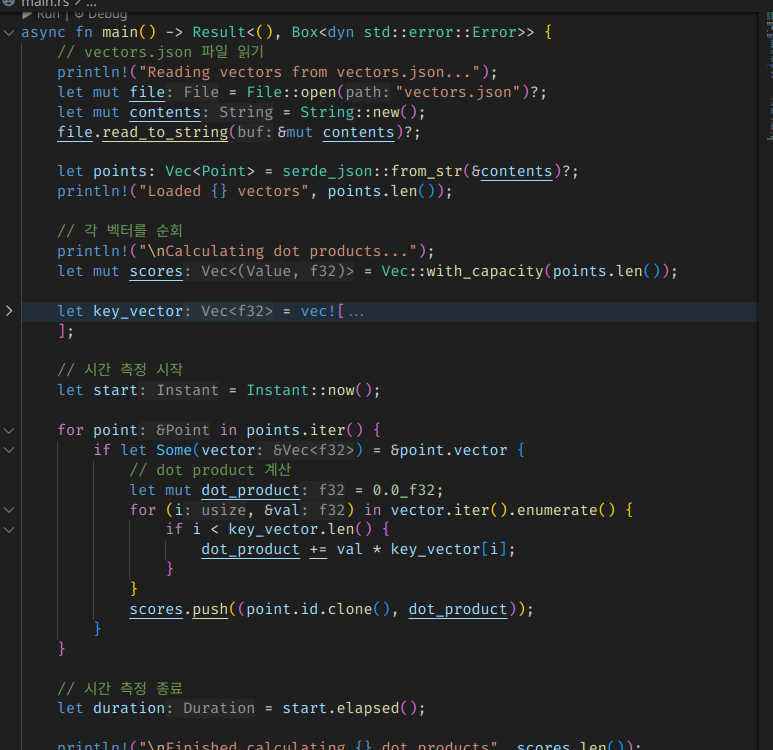
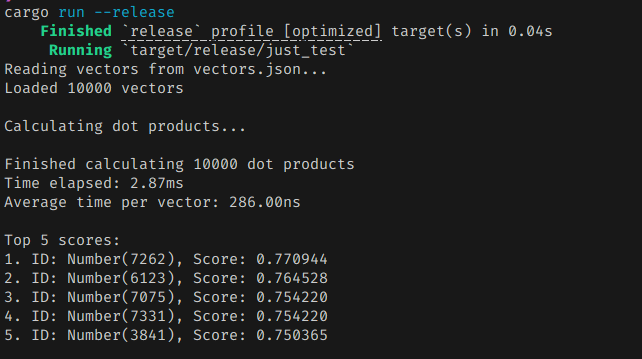 그냥 평범하게 구현했을 때는 하나의 벡터 스코어를 추출하는데 거의 300나노초 가량이 걸렸다.
그냥 평범하게 구현했을 때는 하나의 벡터 스코어를 추출하는데 거의 300나노초 가량이 걸렸다.
그럼 SIMD를 써보면 어떨까?
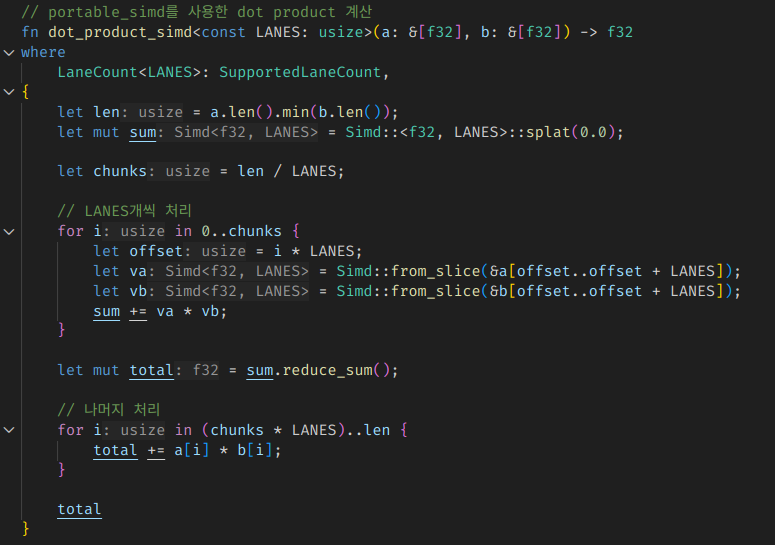
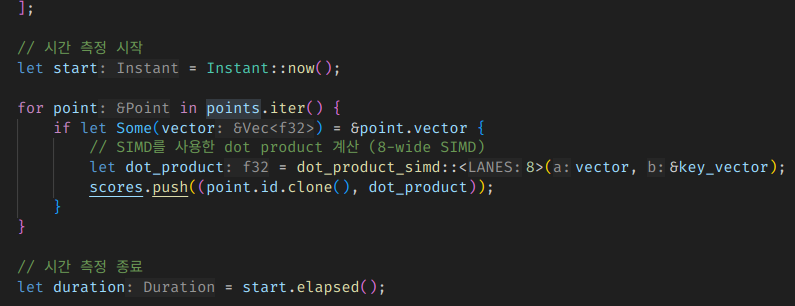 좀 코드가 번잡해지긴 하지만
좀 코드가 번잡해지긴 하지만
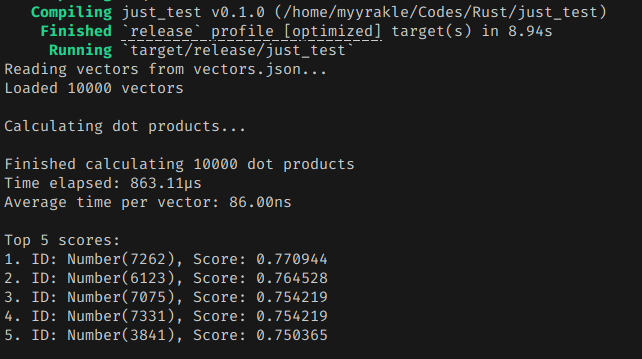 막상 돌려보면 확실한 성능 향상이 있다.
막상 돌려보면 확실한 성능 향상이 있다.
86나노초 정도로 확실하게 빨라졌다. 기존 대비해서 30% 정도로 단축된 셈이다.
내 경우에는 256bit AVX2를 지원하는 CPU라서 최대 8개의 연산을 병렬로 돌렸는데, 이 최대 성능은 CPU마다 다를 수 있다.
최근에는 512bit AVX2도 본격적으로 지원하려는 모양새라서, 향후에는 더 극적으로 빨라질 수도 있을듯하다.