[AWS] S3 미사용 파일 정리하기
S3를 비롯한 파일 스토리지들은 한번 관리가 어긋나기 시작하면 돌이킬 수 없을 정도로 꼬이기 쉽다. 뭔가 데이터는 잔뜩 들어있는데, 실질적으로 쓰이지 않는 쓰레기 데이터가 잔뜩 적재될 수 있는 것이다.
이건 기실 Key-Value 구조를 가진 비정형 NoSQL DB들의 공통점이기도 하다. S3도 포장이야 어쨌든 Key(path), Value(file) DB의 일종이기 때문에 이러한 지점을 공유한다.
내 경우에는 S3 공간이 50TB 쯤은 되었는데, 그 중에서 실질적으로 쓰이지 않는 파일들도 꽤 많았다. 하지만 최종적으로는 대략 15TB 정도의 미사용 파일을 정리할 수 있었다.
목표를 달성한 방식에 대해서 대략 기록해본다.
방법론: Mark and Sweep
관리되지 않은 혼돈스런 상황에서 미사용 파일을 찾아서 지우는 방법은 사실 하나뿐이다.
사용하고 있는 파일을 전부 mark하고, mark되지 않은 파일을 제거하는 것이다. 흔히 말하는 GC의 논리와 같다.
물론 세부적인 마이그레이션 방법은 조금 갈릴 수 있다.
unmark 파일들을 전부 버킷 내에서 그냥 바로 삭제해버릴 수도 있고, 새로운 버킷을 만들어서 mark된(사용중인) 파일을 전부 옮겨버릴 수도 있다. 내 경우에는 변화가 적은 전자를 택했다.
STEP 1: 파일 정보 수집하기
사용/미사용 파일을 추려내려면, 일단 파일에 대한 전체 목록이 필요하다.
근데 S3는 이를 위한 직접적인 기능을 제공하지는 않으므로, 직접 긁어다가 분석을 해야 한다.
내 경우에는 빠른 분석이 가능한 Clickhouse DB에다가 S3 객체 정보를 다 때려넣고 보는 방식을 선택했다.
-- laboratory.s3_bucket definition
CREATE TABLE laboratory.s3_bucket
(
`bucket_name` String,
`key` String,
`storage_class` String,
`last_updated_at` DateTime,
`file_bytes` Int64,
`is_deletable` Bool,
`is_deleted` Bool,
`is_using` Bool DEFAULT false,
`feature` String
)
ENGINE = ReplacingMergeTree
ORDER BY (bucket_name, key)
SETTINGS index_granularity = 8192,
min_age_to_force_merge_seconds = 60;테이블 세팅은 적당히 이렇게 하고
AWS_ACCESS_KEY=...
AWS_SECRET_KEY=...
CLICKHOUSE_USERNAME=default
CLICKHOUSE_PASSWORD=...
CLICKHOUSE_DBNAME=default
CLICKHOUSE_HOST=...
CLICKHOUSE_PORT=8123require("dotenv").config();
const { S3Client, ListObjectsV2Command } = require("@aws-sdk/client-s3");
const { createClient } = require("@clickhouse/client");
const fs = require("fs");
const path = require("path");
// S3 클라이언트 설정
const s3Client = new S3Client({
region: "리전명",
credentials: {
accessKeyId: process.env.AWS_ACCESS_KEY,
secretAccessKey: process.env.AWS_SECRET_KEY,
},
});
// ClickHouse 클라이언트 설정
const clickhouse = createClient({
host: `http://${process.env.CLICKHOUSE_HOST}:${process.env.CLICKHOUSE_PORT}`,
username: process.env.CLICKHOUSE_USERNAME,
password: process.env.CLICKHOUSE_PASSWORD,
database: process.env.CLICKHOUSE_DBNAME,
});
const CURSOR_LOG_FILE = path.join(__dirname, "cursor.log");
const PROGRESS_LOG_FILE = path.join(__dirname, "progress.log");
// 저장된 커서 읽기
function loadLastCursor() {
try {
if (fs.existsSync(CURSOR_LOG_FILE)) {
const cursor = fs.readFileSync(CURSOR_LOG_FILE, "utf8").trim();
console.log(`이전 커서를 찾았습니다: ${cursor}`);
return cursor || null;
}
} catch (error) {
console.error("커서 로드 실패:", error);
}
return null;
}
// 커서 저장
function saveCursor(cursor) {
try {
fs.writeFileSync(CURSOR_LOG_FILE, cursor || "", "utf8");
} catch (error) {
console.error("커서 저장 실패:", error);
}
}
// 진행 상황 로그
function logProgress(message) {
const timestamp = new Date().toISOString();
const logMessage = `[${timestamp}] ${message}\n`;
console.log(message);
try {
fs.appendFileSync(PROGRESS_LOG_FILE, logMessage, "utf8");
} catch (error) {
console.error("로그 저장 실패:", error);
}
}
async function processS3Objects(bucketName, startCursor = null) {
let continuationToken = startCursor;
let totalProcessed = 0;
logProgress(`S3 버킷 ${bucketName}의 파일 목록을 조회하고 저장하는 중...`);
if (startCursor) {
logProgress(`커서부터 재개: ${startCursor}`);
}
do {
const command = new ListObjectsV2Command({
Bucket: bucketName,
ContinuationToken: continuationToken,
});
const response = await s3Client.send(command);
if (response.Contents && response.Contents.length > 0) {
// 조회한 데이터를 바로 ClickHouse에 저장
const values = response.Contents.map((obj) => ({
bucket_name: bucketName,
key: obj.Key,
storage_class: obj.StorageClass || "STANDARD",
last_updated_at: obj.LastModified
? Math.floor(new Date(obj.LastModified).getTime() / 1000)
: 0,
file_bytes: obj.Size || 0,
is_deletable: false,
is_deleted: false,
}));
await clickhouse.insert({
table: "laboratory.s3_bucket",
values: values,
format: "JSONEachRow",
});
totalProcessed += response.Contents.length;
logProgress(
`${totalProcessed}개 처리 완료 (이번 배치: ${response.Contents.length}개)`
);
}
continuationToken = response.NextContinuationToken;
// 다음 커서가 있으면 저장 (중단 시 재개 가능)
if (continuationToken) {
saveCursor(continuationToken);
logProgress(`현재 커서: ${continuationToken}`);
}
} while (continuationToken);
// 완료되면 커서 파일 삭제
if (fs.existsSync(CURSOR_LOG_FILE)) {
fs.unlinkSync(CURSOR_LOG_FILE);
logProgress("커서 파일 삭제 완료");
}
logProgress(`총 ${totalProcessed}개의 파일을 처리했습니다.`);
return totalProcessed;
}
async function main() {
try {
const bucketName = "버킷명";
// 이전에 중단된 커서가 있는지 확인
const lastCursor = loadLastCursor();
// S3 버킷의 파일을 조회하면서 바로 저장
const totalProcessed = await processS3Objects(bucketName, lastCursor);
if (totalProcessed === 0) {
logProgress("버킷에 파일이 없습니다.");
return;
}
logProgress("작업이 성공적으로 완료되었습니다.");
} catch (error) {
logProgress(`오류 발생: ${error.message}`);
console.error("오류 상세:", error);
process.exit(1);
} finally {
// ClickHouse 연결 종료
await clickhouse.close();
}
}
main();자바스크립트로 읽어다가 밀어넣는 프로그램을 짜서 돌렸다.
 그러면 한번에 가져올 수 있는 객체 제한이 1000개라서 좀 걸리긴 하는데, 아무튼 가져올 수는 있다.
그러면 한번에 가져올 수 있는 객체 제한이 1000개라서 좀 걸리긴 하는데, 아무튼 가져올 수는 있다.
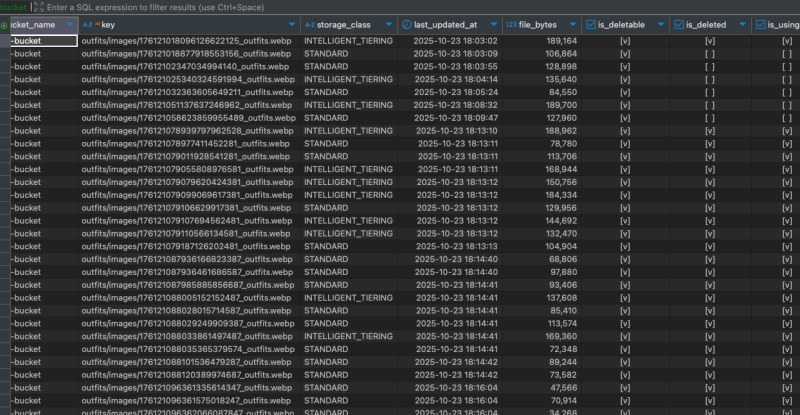
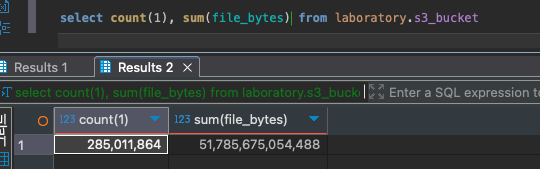 많기도 하다.
많기도 하다.
이렇게 수집이 되었다면 최소한의 시작점은 잡은 셈이다.
STEP 2: 사용중인 파일 Mark하기
이제 첫번째 스텝이다.
실제로 사용중인 파일들을 전부 MARK 표시를 해줘야 한다.
데이터에서 URL로 참조를 하고 있는 것도 있을테고, 아니면 어딘가에 하드코딩된 URL/Key가 있을 수도 있다.
그걸 죄다 찾아서 mark를 해줘야 한다.
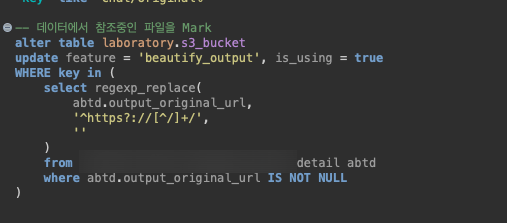 내 경우에는 운영 데이터 전체를 Clickhouse에 동기화해놓고 있는 상황이었기 때문에, 그걸 기반으로 이렇게 매칭을 시켰다.
내 경우에는 운영 데이터 전체를 Clickhouse에 동기화해놓고 있는 상황이었기 때문에, 그걸 기반으로 이렇게 매칭을 시켰다.
이 과정이 가장 중요하다. 참조중인 것이 있는데도 빼먹거나 잘못 mark를 한다면, 사용중인데도 삭제해버릴 수가 있기 때문이다. 가장 많은 공을 들이고 신경써야 한다.
아무튼 실제 사용 카테고리별로 적당히 찍고, 참조 중인 것들 중에서도 삭제 가능한게 있다면 삭제 가능한 것으로 마킹해주고 그러면 된다.
-- 참조대상이 없는 항목을 삭제 가능한 것으로 표시
alter table laboratory.s3_bucket
update is_deletable = true
where is_deleted = false and feature = '' and is_using = falseSTEP 3: 삭제 전 백업하기 (for safe)
사람은 항상 실수를 한다.
그렇기 때문에 운영 환경에서는 언제든 돌이킬 수 있는 방법을 마련해두는 것이 중요하다.
내 경우에는 백업 수단을 S3의 DEEP ARCHIVE 클래스로 선택했다.
직접 다운받아서 온프레미스 공간에 저장할 수도 있을 테지만, 이런 경우에 한해서는 딱히 그게 저렴하다는 보장까지는 없기 때문이다.
일단 S3 DEEP ARCHIVE로의 COPY-백업은 데이터 전송 비용이 없다.
물론 API 호출당 개수나 약간의 저장 비용이 발생하긴 하지만, 이런 대형 데이터에서는 데이터 전송 비용이 그보다 훨씬 더 크다.
게다가 완전히 안전하다는 보장이 생기면 종국에는 삭제할 수 있으므로, 잠시동안의 저장 비용은 감수할만하다. 표준 클래스보다는 15배 정도는 싸니까 말이다.
그래서 전용 백업 버킷을 만들고 삭제 전에 옮겨놓는 방식을 취했다.
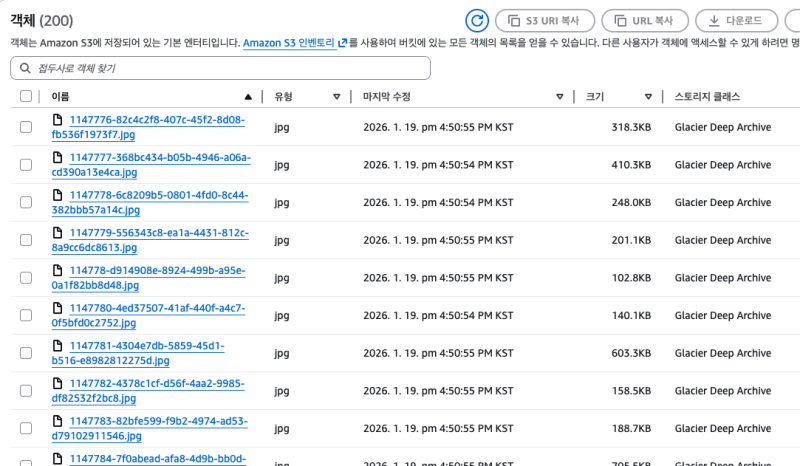
DEEP ARCHIVE의 비용이나 제약사항 등은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/224155291740
STEP 4: 미사용 파일 날리기 - SWEEP
준비가 다 됐다면, 날릴 일만 남았다.
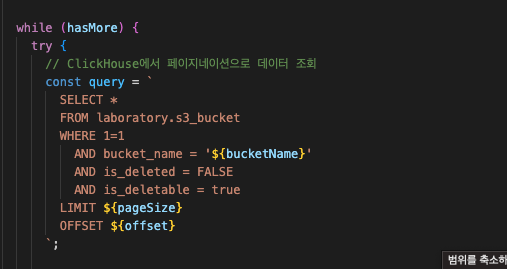
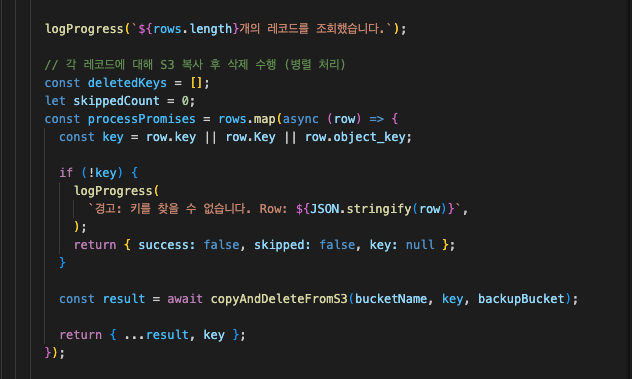
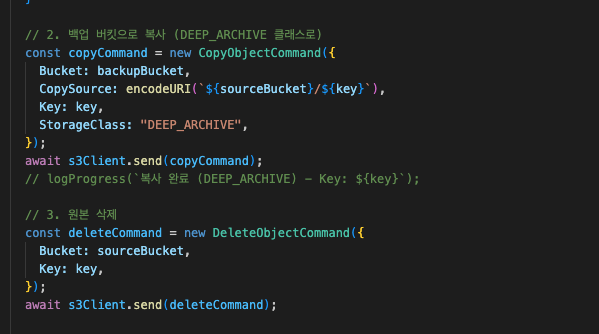
 적당히 짜서 백업->삭제를 수행토록 했다.
적당히 짜서 백업->삭제를 수행토록 했다.
전체 코드는 길기도 하고, 뻔해서 굳이 올리진 않는다.