분산 트랜잭션: calvin
calvin은 분산 트랜잭션 이론 중 하나다. 2012년에 Yale 대학에서 발표했다.
이론적으로 주목받긴 했는데, 주요 구현체 중에서 이걸 메인으로 사용한 것은 딱히 없다.
Spanner와 비슷하면서도 대비되는 특징을 가진다.
기존 분산 트랜잭션의 문제: 2PC
일반적으로 많이 사용되는 핵심 구현 패턴은 2PC라는 것이다.
https://blog.naver.com/sssang97/223465481384
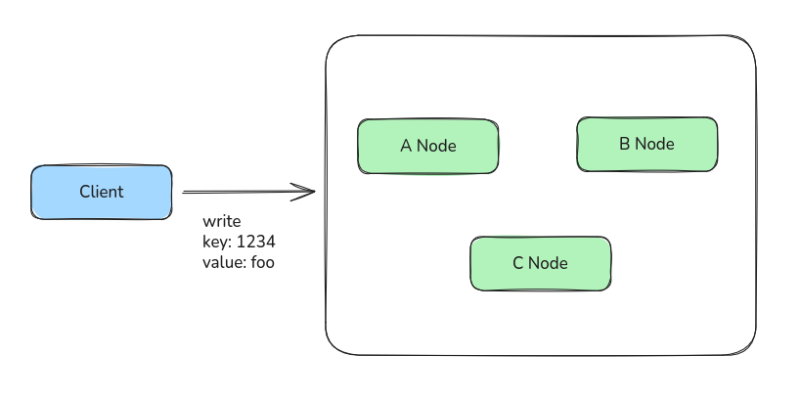
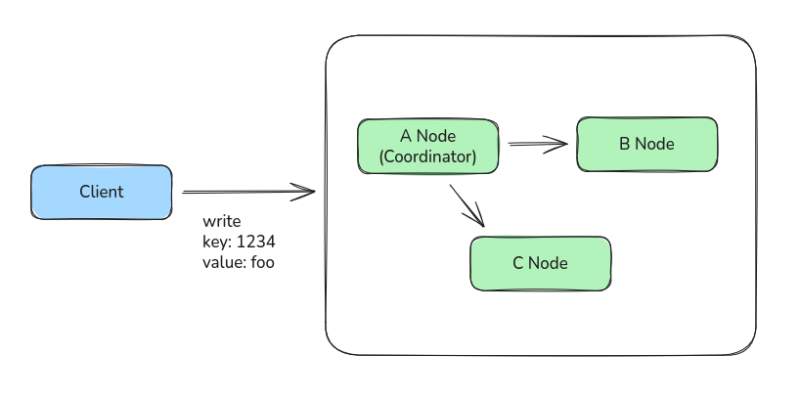
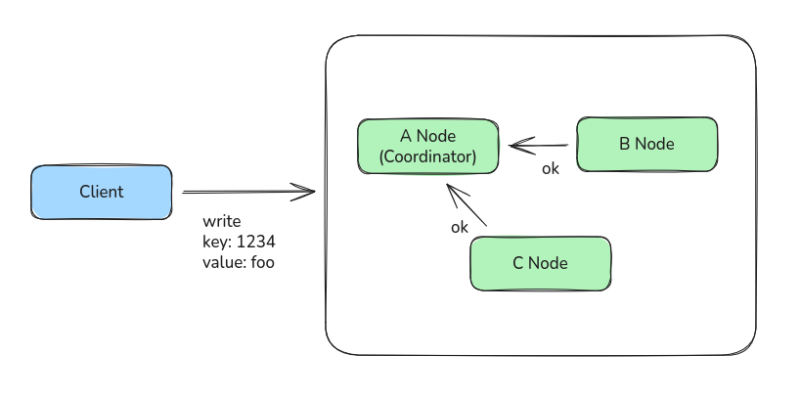
이건 매우 직관적인 방법으로 전체 노드에 대한 글로벌 트랜잭션을 구현한다.
노드마다 write를 날리고 Lock을 걸어둔 다음에, 모든 노드의 write가 완료된다면 Lock을 풀고 트랜잭션을 완료된 것으로 처리하는 것이다.
이 방법은 강력한 Lock을 보장할 수 있지만, 매우 느리고, 네트워크 딜레이가 길고, Lock으로 인한 전체 노드 정지 시간이 길어질 수 있다는 것이 치명적인 단점이었다.
 이렇게 번잡한 과정을 거치는데다, 하나 할때마다 전체 Lock을 걸어버리니 처리량이 썩 좋지 않게 나오는 것이다.
이렇게 번잡한 과정을 거치는데다, 하나 할때마다 전체 Lock을 걸어버리니 처리량이 썩 좋지 않게 나오는 것이다.
calvin의 방법론
생각해보자. 애초에 Lock을 대체 왜 거는가?
그 목적 중 하나는 데이터 무결성이다. A->B 순서로 쓰기가 발생한 것이 실제로 B->A로 기록된다면, 당연히 데이터가 다를 것이다. Lock은 이런 순서 꼬임 문제를 방지하는 가장 비관적인 방식이다.
calvin은 이 부분에 집중한다.
순서가 문제라면, 트랜잭션 순서를 관리하는 관리포인트를 추가하고, 전체 Lock 없이 개별 Lock으로만 처리하게 하자는 것이다.
트랜잭션을 미리 정리해버리기 때문에 결정론적 Lock(Deterministic Lock) 방식이라고도 부른다.
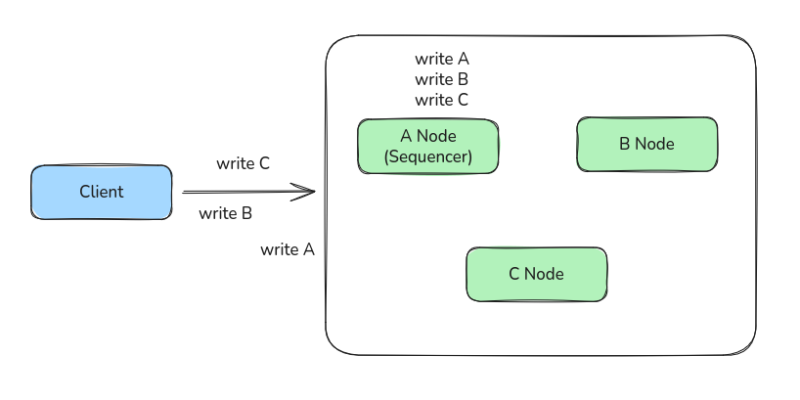 쓰기 트랜잭션이 여러개 날라오면, 일단 시퀀서라는 중심 노드가 그 쓰기를 먼저 받는다.
쓰기 트랜잭션이 여러개 날라오면, 일단 시퀀서라는 중심 노드가 그 쓰기를 먼저 받는다.
그리고 트랜잭션들을 즉시 복제하지 않고 일정량 모은 다음에, 그 트랜잭션 목록을 로그로서 저장한다.
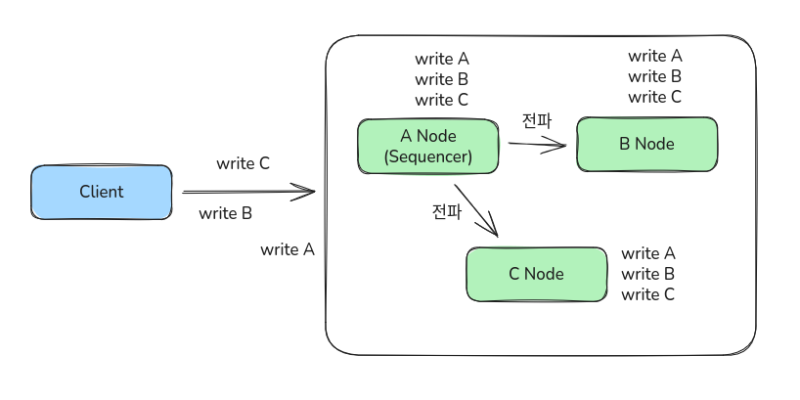 그리고 모아놓은 트랜잭션 리스트를 일정 주기로 떠넘겨버리고, 개별 노드에서 알아서 쓰기를 처리하도록 위임하는 것이다.
그리고 모아놓은 트랜잭션 리스트를 일정 주기로 떠넘겨버리고, 개별 노드에서 알아서 쓰기를 처리하도록 위임하는 것이다.
만약 노드에서 받은 트랜잭션을 모종의 이유로 처리하지 못한다면, 시퀀서에서 저장해놓은 트랜잭션 로그를 통해 replay를 한다. 이를 통해 장애 내구성을 높인다.
네트워크 전송 횟수 자체가 적고 쓰기를 몰아서 처리하기 때문이, 경쟁이 심한 환경에서의 쓰기 처리량은 가장 우수하다는 평가를 받는다.
하지만 후술할 문제들 때문에 널리 쓰이진 않는다.
calvin의 문제
모든게 완벽하고 훌륭했으면 당연히 모두가 calvin을 기반으로 트랜잭션을 구현했을 것이다.
하지만 현실은 그렇지 않고, 주요 분산 DB는 전부 Spanner의 직계다.
이게 좀 치명적인 단점이 많다.
복제의 완료 확인 불가
calvin의 시퀀서는 트랜잭션을 모아서 개별 노드에 던지기는 하지만, 2PC와 다르게 개별 노드의 완료를 확인하거나 기다리지 않는다. 그저 언젠가는 되겠거니 할 뿐이다.
그래서 read after write를 보장할 수 없다.
단일 장애 지점
calvin에서는 시퀀서라는 존재가 많은 책임을 진다.
복제 자체도 그렇지만, 글로벌 로그라는 중앙 상태가 추가되기 때문에, 시퀀서 노드에서 장애가 발생할 경우의 영향이 매우 치명적이다.
그래서 calvin은 가용성을 포기한 CP로 분류된다.
조건부 수정의 구현이 어려움
단순한 삽입인 INSERT는 문제가 없다.
하지만 UPDATE WHERE name = 'ALICE' 같은 조건 기반의 write는 calvin에서 좀 어려운 주제다.
name = 'ALICE'인 데이터를 수정하려면, name = 'ALICE'인 데이터를 찾아서 그 행에 대한 Lock을 걸어야 한다. 하지만 이걸 찾아서 행에 Lcok을 걸려면 인덱스 등을 통해서 어떤 행인지 탐색을 해야한다.
근데 값을 가져와서 행을 찾더라도, 그게 동시성 환경에서는 여전히 유효하다는 보장이 없다.
그래서 루프를 돌거나 Lock을 걸어서 무결성을 보장해야하는데, 필연적으로 성능 저하가 발생할 수 있다.
구현체
calvin을 적극 차용한 구현체로는 FaunaDB라고 있는데, 잘 쓰이는 DB는 아니다.
이거 말고는 딱히 없는거같다...
calvin의 기묘하고 제약적인 구조 때문에 Fauna는 독특한 설계를 갖고 있다.
참조
https://fauna.com/blog/distributed-consistency-at-scale-spanner-vs-calvin
https://queue.acm.org/detail.cfm?id=3025012
https://github.com/yaledb/calvin
https://www.vldb.org/pvldb/vol7/p821-ren.pdf
https://dbmsmusings.blogspot.com/2017/04/distributed-consistency-at-scale.html
https://www.yugabyte.com/blog/google-spanner-vs-calvin-global-consistency-at-scale/