분산 트랜잭션: Percolator
Percolator는 Google에서 만든 분산 트랜잭션 패턴 중 하나다.
2010년에 발표되었다. 구글이 크롤링 데이터 빠르게 분산해서 쓰려고 만든거라고 한다.
Spanner를 비롯해서 후에 나온 많은 분산시스템들이 직간접적인 영향을 받았다.
기본 논리
2PC 같은 기존의 분산 트랜잭션은 매우 비관적인 Lock을 사용하는 기법이라고 할 수 있다.
멈춰놓고 트랜잭션의 순서를 강제로 보정하는 것으로, 쓰기 순서가 꼬이는 것을 원천봉쇄한다.
Percolator은 반대로 매우 낙관적인 Lock을 사용하는 방법론이다.
전체 Lock을 걸지 않고, 일단 모든 노드에 트랜잭션을 복제해서 때려넣는다. 다만 순서의 꼬임으로 충돌이 일어났을때 "실패"하는 식으로 처리를 하는 것이다.
이 충돌의 기준은 타임스탬프다. 모든 쓰기 트랜잭션마다 타임스탬프를 부여하고, 가장 최신 타임스탬프의 값만 인정하는 것이다.
예를 들어, 동일 Key 행에 대해 타임스탬프가 (100, 200, 300)인 쓰기가 들어왔다면, 300의 쓰기가 최종적으로 적용되는 구조다. 만약 300이 먼저 쓰기가 된 상태에서 100, 200인 쓰기가 들어온다면, 해당 쓰기는 abort된다.
좀 더 상세하게 흐름을 정리하자면 이렇다.
-
쓰기를 날리게 되면, 일단 클라이언트가 Timestamp Oracle이라는 서버를 통해 쓰기 트랜잭션에 넣을 시간값(start_ts)을 받아온다.
-
클라이언트는 쓰기를 먼저 받을 Primary 노드를 고르고, 거기에 start_ts와 함께 트랜잭션을 날린다.
-
Primary 노드는 다른 모든 노드에 트랜잭션을 복제한다.
-
노드는 트랜잭션을 무작위 순서로 받는다.
-
만약 동일 행에 대해 타임스탬프가 더 옛날인 쓰기가 들어온다면 즉시 abort를 primary에 던진다. 예전의 값을 갖고서 잘못된 수정을 할 수 있기 때문이다.
-
노드의 복제가 하나라도 abort되면 트랜잭션 자체가 실패한 것이고, 롤백한다.
-
노드의 복제가 전부 완료되면 Primary는 그 신호를 받고 커밋으로 처리한다.
-
트랜잭션과 복제 진행중에는 노드마다 값이 다른 순간이 발생할 수 있다.
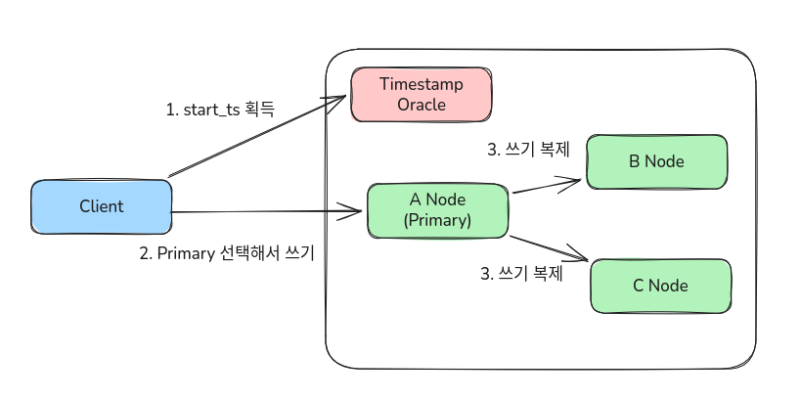
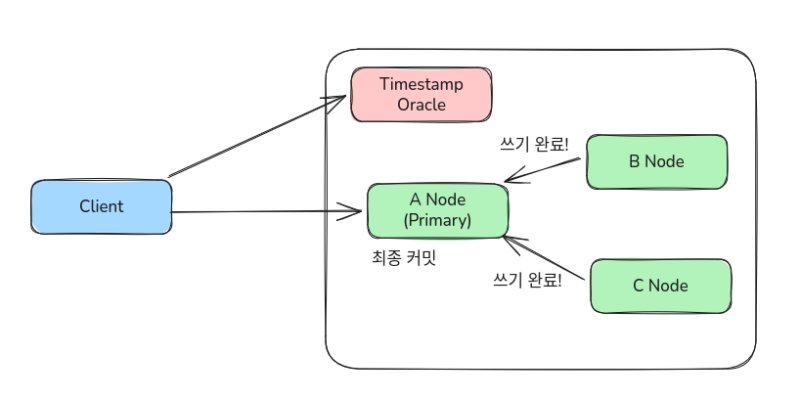 그래서 얼핏 보면 네트워크 핑퐁 관점에서는 2PC와 동일하다. 쓰기를 복제하고, 쓰기가 완료된 것을 확인받은 다음에 최종 커밋을 Primary에 기록하기 때문이다.
그래서 얼핏 보면 네트워크 핑퐁 관점에서는 2PC와 동일하다. 쓰기를 복제하고, 쓰기가 완료된 것을 확인받은 다음에 최종 커밋을 Primary에 기록하기 때문이다.
2PC와 Percolator가 분기되는 부분은 하나, 동일 행 업데이트에 대해 Lock을 걸고 멈추는지, 일단 던진 다음에 충돌 오류를 던지는지다. 이게 처리량을 가르는 분기점이다.
그리고 전처리 프로세스가 하나 있다.
노드는 쓰기 트랜잭션을 받아서 처리하기 전에, TTL이 지나서 만료된 Lock이나 쓰기가 있다면 그걸 삭제해서 취소한다. 이를 통해 사실상 실패한 트랜잭션을 lazy하게 정리하는 것이다.
장단점
장점
주요 장점은 높은 처리량, 장애시의 안정적인 복구 능력이다.
Lock을 2PC처럼 Lock을 길게 걸어대진 않기 때문에, 쓰기에서의 행 단위 충돌이 빈번하지 않다면 2PC보다 높은 쓰기 처리량을 가질 수 있다.
그리고 장애시의 복구 처리도 꽤 수월하다. 2PC의 경우에는 누가 Lock 잡고 뻗으면 뭔가 해결하기 어렵지만, Percolator의 Lock은 항상 TTL으로 실행되기 때문에 만료로 인한 재진입이 가능하다.
이후에 들어온 쓰기 트랜잭션이 있다면 기존에 만료된 Lock에 대해서 트랜잭션 취소 처리를 하면서 정리하고 할일 한다.
단점
당연히 단점도 있다.
일단 시간을 받아오는 타임스탬프 Oracle이라는 서버가 단일 병목/장애 지점이 된다. 이건 어떻게 할 수가 없다.
높다는 처리량도 사용 패턴에 따라서 좀 달라진다. 행 단위 충돌이 적다면 처리량이 높고 효율적이지만, 충돌이 빈번하다면 2PC보다도 느려질 수도 있다.
그리고 본질적으로, 이건 실시간성을 가져가는 구조로 만들어져있지 않다. 처리량이 높을 뿐이다.
상기한 "이전 트랜잭션을 정리하는 작업"을 비롯해서 레이턴시를 늘릴 수 있는 내부 동작이 있고, 그게 길어진다면 최대 레이턴시가 몇초에서 몇십초 단위까지 걸릴 수도 있다.
그래서 처리량이 높을 뿐이지, 빠르고 안정적인 실시간 DB로서는 활용하기 어렵다.
구현체
대표적인 구현체로는 Google의 Bigtable, 오픈소스 NoSQL인 TiKV가 있다.
TiKV는 인지도가 애매하긴 한데, 마이너 중에서는 메이저한 편이다.
Spanner
Spanner도 여기에 개념을 덧대서 만들어진 것이라고 봐도 된다.
Percolator는 타임스탬프를 외부 시간서버에서 받아오는데, 이걸 원자시계를 붙여서 가져오면 그게 사실상 Spanner가 된다. 세부적인 구현에서는 차이가 있지만.
참조
https://www.yugabyte.com/blog/implementing-distributed-transactions-the-google-way-percolator-vs-spanner/
https://tikv.org/deep-dive/distributed-transaction/percolator/
https://www.usenix.org/legacy/event/osdi10/tech/full_papers/Peng.pdf
https://www.alibabacloud.com/blog/about-database-kernel-%7C-transaction-system-of-polardb-x-storage-engine-part2_600789