[k8s] Nvidia GPU 리소스 사용하기
쿠버네티스는 RuntimeClass 같은 리소스와 플러그인을 활용해서 특정 런타임 의존적인 프로비저닝을 구현할 수 있는데, 그 중 대표적인 사용사례가 GPU 장비에 대한 관리다.
기실 GPU 같은 하드웨어 관리는 쿠버네티스 팀의 관리 소관은 아니다. 약간 서드파티 같은 느낌으로 제공될 뿐이며, 컨테이너 구현체마다도 다르다.
여기서는 nvidia GPU 리소스를 서버로 띄우고 관리하는 방법을 다뤄본다.
RuntimeClass
RuntimeClass는 노드에 붙이는 일종의 태그값이다.
특정 노드가 이런 런타임 특성을 갖고 있음을 지정하고, 이를 통해 특정 Pod들이 해당 런타임에 속하는 노드에만 실행될 수 있도록 구성하는 것이다.
RuntimeClass의 기본 값 목록은 쿠버 클러스터 구성에 따라 다를 수 있다.
k3s의 경우에는 이렇게 들어있다.
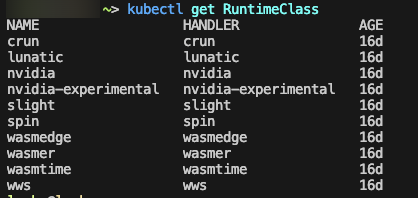
만약 저 목록에 필요로 하는 클래스가 없다면 직접 추가해주면 된다.
만드는게 딱히 어렵지도 않다.
vim nvidia.yaml
kubectl apply -f nvidia.yamlapiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: nvidia
handler: nvidia어차피 단순 메타데이터에 속하는 리소스 단위이기 때문이다.
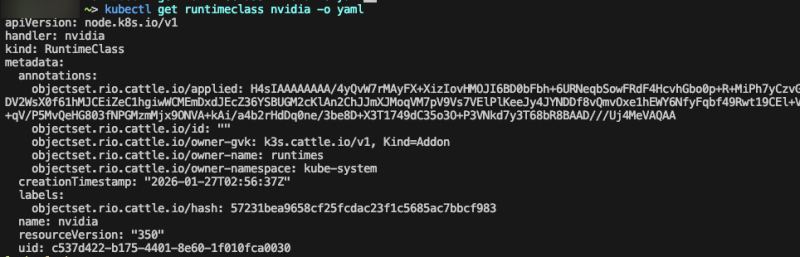 이게 k3s에서 사전 제공하는 엔비디아 클래스 구성이다.
이게 k3s에서 사전 제공하는 엔비디아 클래스 구성이다.
nvidia 네이티브 드라이버 설치 (Ubuntu)
먼저 호스트에서 nvidia 드라이버를 설치해야 한다.
일반 드라이버를 먼저 깔아서, nvidia-smi의 실행이 잘 되는지를 확인한다.
# 우분투 전용
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo ubuntu-drivers autoinstall
sudo reboot now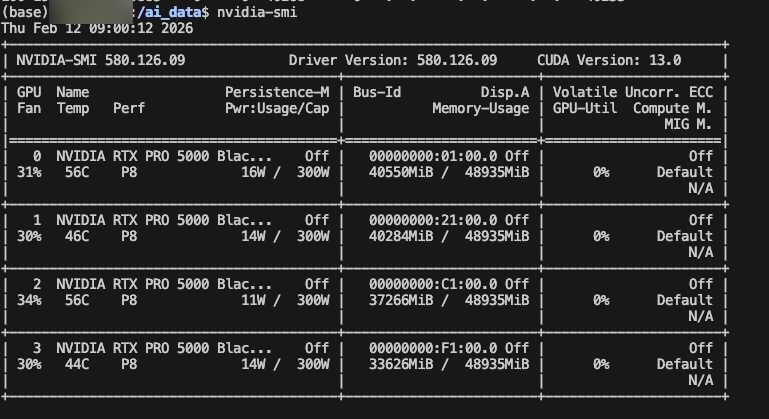
nvidia 컨테이너 드라이버 설치
뭐가 이것저것 많이 필요하다.
nvidia에서 제공하는 컨테이너용 플러그인이 있는데, 이걸 깔아야지 컨테이너 내에서도 nvidia 드라이버를 사용할 수 있다.
https://blog.naver.com/sssang97/223882298321
그래서 이게 잘 실행되면 된다.
nvidia-container-runtime --version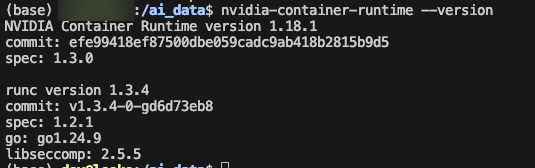
쿠버네티스 CNI에 nvidia container 드라이버 연결 (contanerd)
배포판에 따라서는 이게 자동으로 설정되어있을 수 있고, 컨테이너 런타임마다 구성법이 다르다. 여기서는 containerd를 기준으로 정리한다.
GPU가 깔려있는 노드에서 containerd 설정파일을 수정하고 재시작한다.
nvidia 도구를 통해서 할 수도 있고
sudo nvidia-ctk runtime configure --runtime=containerd
sudo systemctl restart containerd직접 config 찾아서 수정할 수도 있다.
# 이 경로 아닐 수 있음
sudo vim /etc/containerd/config.toml
sudo systemctl restart containerd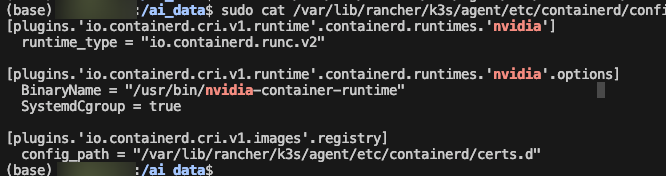 이렇게 nvidia 런타임을 참조하도록 구성하면 된다.
이렇게 nvidia 런타임을 참조하도록 구성하면 된다.
Device Plugin 설치
마스터 노드에서 nvidia용 컨테이너 플러그인을 설치한다.
이게 노드마다 GPU가 몇개 있고, 몇개를 쓰고 있는지 등을 추적하고 관리해주는 플러그인이다.
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.5/nvidia-device-plugin.yml
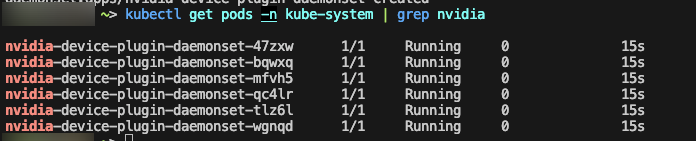 그럼 노드마다 한대씩 뜬다.
그럼 노드마다 한대씩 뜬다.
구성 확인
이것저것 다 잘 세팅했고 문제가 없다면, 노드 정보에 nvidia 관련된 속성값들이 추가될 것이다.
노드를 describe해보면
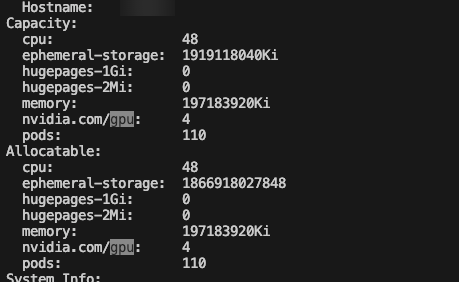 gpu가 4개 있는게 나오고
gpu가 4개 있는게 나오고
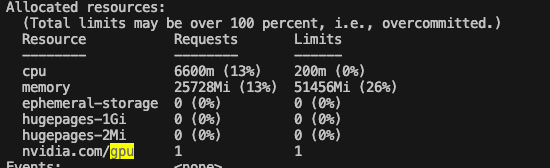 현재 몇개나 쓰이고 있는지도 나온다.
현재 몇개나 쓰이고 있는지도 나온다.
이렇게 되면 세팅은 잘 된 것이다.
다음 명령을 사용하면 각 노드가 gpu를 몇개씩 가지고 있는지 확인 가능하다.
kubectl get nodes -o custom-columns=NAME:.metadata.name,GPU:.status.allocatable."nvidia\.com/gpu" 4개만 있는 것이 보일 것이다.
4개만 있는 것이 보일 것이다.
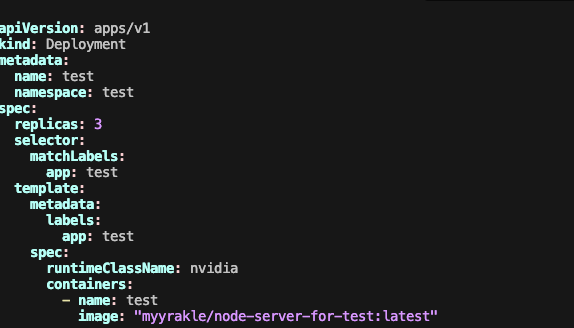
GPU 노드에 Pod 실행하기
이제는 준비가 끝났다.
pod spec에 runtimeClassName으로 nvidia 클래스를 넣으면, 해당 리소스가 있는 노드에만 Pod를 프로비저닝한다.
혹은, GPU 리소스에 대한 LIMIT을 설정할 수도 있다.
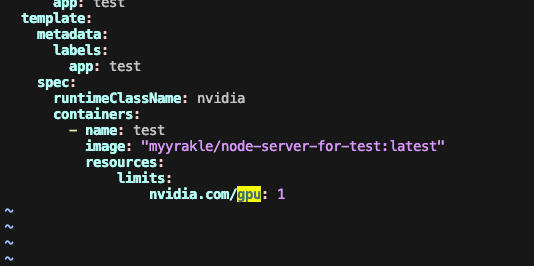
그러고 실행해보면
 실제로 nvidia GPU가 구성된 노드에만 뜨는 것을 볼 수 있을 것이다.
실제로 nvidia GPU가 구성된 노드에만 뜨는 것을 볼 수 있을 것이다.
그러면 이제는 저기에 적당히 모델만 올려서 쓰거나 하면 된다.
GPU 기본 할당 매커니즘
만약 GPU Limit을 설정한다면, 드라이버는 GPU에 대한 격리를 보장한다.
해당 노드에 GPU가 3개 있더라도, 1개만 잡아서 접근 가능하게 비가시화하는 것이다.
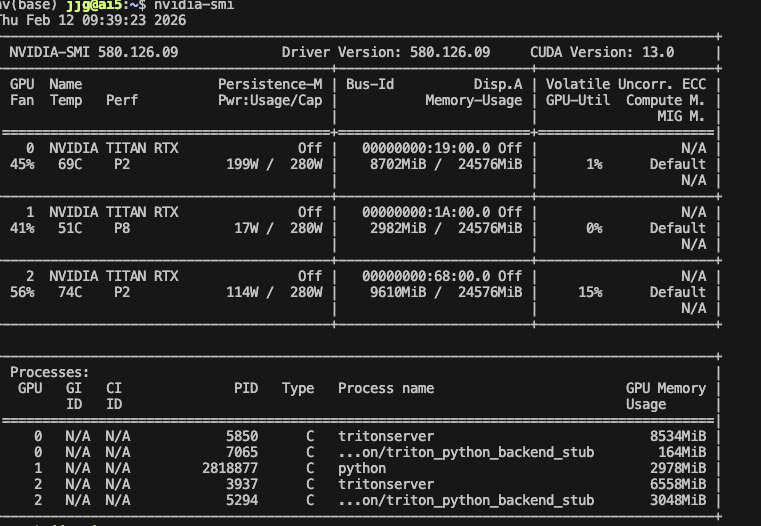 이게 호스트고
이게 호스트고
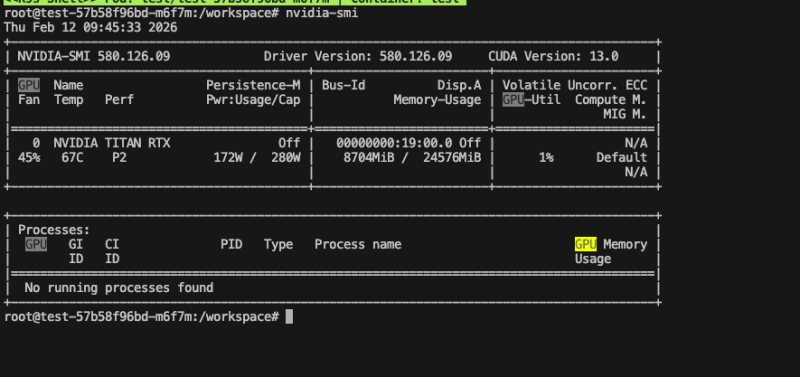 이게 컨테이너 내부에서의 조회 정보다. 0번이 할당되었다.
이게 컨테이너 내부에서의 조회 정보다. 0번이 할당되었다.
특정 GPU를 명시적으로 할당하고 싶을 수도 있다.
CUDA_VISIBLE_DEVICES를 0-start index로 넣으면, 그 GPU가 할당된다.
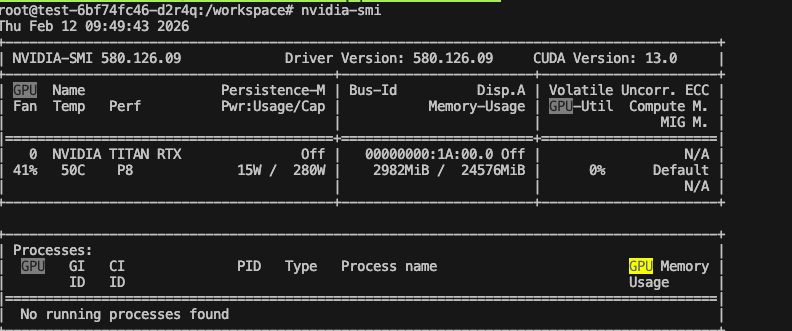 그럼 실제로 할당한 1번 GPU가 잡힌다.
그럼 실제로 할당한 1번 GPU가 잡힌다.
다만, 저 값이 절대적이진 않다.
가령 replica로 2개를 띄울 경우에는 1개만 저 번호로 할당되고, 나머지는 랜덤으로 할당된다.
참조
https://kubernetes.io/ko/docs/concepts/containers/runtime-class/