분산 트랜잭션: Spanner
Spanner는 Google에서 만든 데이터베이스 분산시스템이다.
논문은 2012년에 공개했고, 서비스로서는 2017년에 공개되었다.
Google Cloud에서만 지원되는 폐쇄형 서비스이긴 하지만, 기술 구조는 논문으로 공개해서 분산시스템 환경에 큰 영향을 줬다. 이후에 나온 분산 DB들은 모두 Spanner의 영향을 상당히 받았다.
2PC의 문제
https://blog.naver.com/sssang97/223465481384
2PC는 구현이 간단하고 엄격한 트랜잭션으로 많은 보장을 얻지만, 큰 단점이 몇가지 있었다.
그래서 Spanner는 2PC를 기반으로 하되, 문제점을 일부 개선하고 보강하는 형태로 발전했다.
Read Lock
쓰기를 행할때 전체 노드에 Lock을 걸고 순서를 강제로 보정하는건 어쩔 수 없다고 치겠다. 일관성을 확실하게 가져가려면 이 이상의 접근법은 없다.
근데 부조리한 것 중 하나는, 전통적인 2PC에서는 Read를 할 때도 Shared Lock을 걸어야 했었다. 그래서 읽기 처리량이 매우 낮다는 단점이 있었다.
다만, MVCC를 기본 수정 매커니즘으로 사용할 경우에는 이러한 문제가 적거나 없다.
단일 Coordinator만 가능
게다가 쓰기를 받고 복제하는 "Coodinator" 단위를 관리하는 것이 쉽지 않았다. 2PC는 기본적으로 Coordinator가 단일로 하나만 존재할 때만 트랜잭션의 순서와 무결성을 보장할 수 있다. Coordinator가 여럿이라면 서로서로가 옛날 값을 보고 잘못된 수정을 할 수 있기 때문이다.
예를 들어, 클라이언트에서 쓰기 트랜잭션 (T1, T2)를 순서대로 보냈고, T1과 T2가 다른 Coordinator에 배정된다고 가정해보자. 둘이 다른 노드에서 쓰기를 시작한다면 이 복제에 따른 순서를 보장할 수가 없다.
T2가 T1의 값을 읽어서 쓰기를 처리하는 쿼리라고 하면, T1의 복제가 완료되기 전에 T2가 옛날 데이터를 볼 수가 있는 것이다.
이런 이유에서 Coordinator를 단일로만 유지해야 하고, 단일 장애 지점이 생긴다는 단점이 있다.
장애 복구의 어려움
단일 Coordinator가 쓰기 복제를 Slave 노드들에 던진 상태(Prepare)에서 단일 Coordinator가 뻗었다고 가정해보자. 당연히 단일 master가 죽었으니까 이 자체로도 단일 장애 지점에 의한 심각한 문제다.
그런데 더 까다로운건 그 이후다. master가 죽더라도 master를 새로 뽑아서 올리거나 기존의 master를 살리면 된다. 하지만 Prepare가 날라가서 Lock이 잡혀있는 값들은 뭔가 정리를 해줘야 한다. 정리를 해주지 않으면 Slave들에 이미 Lock flag가 켜져있기 때문에 해당 값에 대한 접근이 불가능해진다.
이것도 구현이 복잡하고 까다로운 부분이다.
Spanner의 기본 구조
Spanner는 특별한 하드웨어 계층과 분산 합의 구조까지 포함된 거대한 구현체라서, 쉽게 설명하긴 어렵다.
대략적인 구조만 정리해본다.
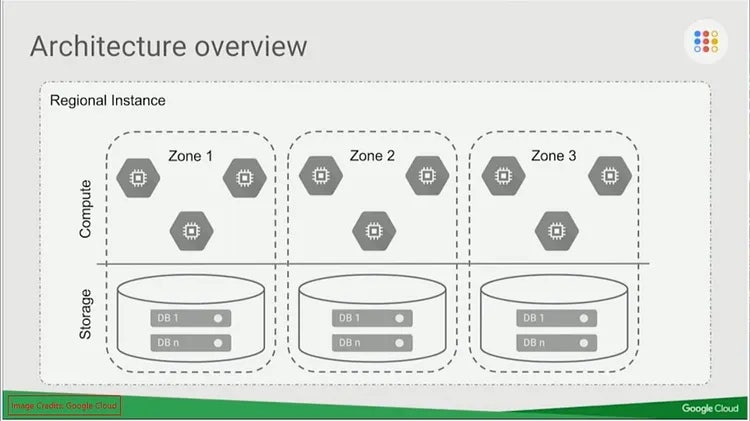 분산 합의 프로토콜은 Paxos를 사용한다. raft를 쓰지 않은건 paxos가 진짜 좋아서보다는, raft가 아직 뜨기 전이었기 때문이다.
분산 합의 프로토콜은 Paxos를 사용한다. raft를 쓰지 않은건 paxos가 진짜 좋아서보다는, raft가 아직 뜨기 전이었기 때문이다.
하나의 Spanner는 Zone이라는 가상 파티션 단위로 프로비저닝된다. 하나의 Zone에는 최소 3개의 Replica가 생성된다. 여기서 Zone은 서울, 버지니아 같은 지역 리전이 된다.
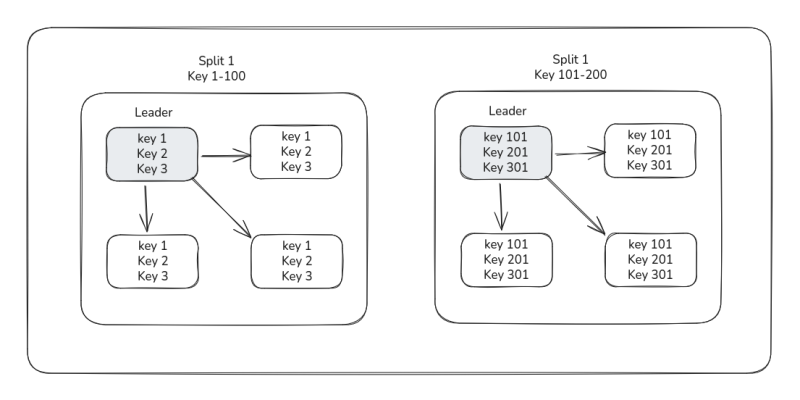 그리고 Spanner는 내부적으로 Split이라고 하는 파티션 단위를 관리한다. 키 값을 기준으로 Split을 나누며, Split 자체를 Paxos 그룹이라고도 부른다.
그리고 Spanner는 내부적으로 Split이라고 하는 파티션 단위를 관리한다. 키 값을 기준으로 Split을 나누며, Split 자체를 Paxos 그룹이라고도 부른다.
Paxos 그룹 내에서는 동일 데이터를 복제해서 공유하는 Replica들이 여러개 존재하며, Paxos 그룹에는 하나의 Paxos Leader가 복제를 책임진다.
 그리고 Cloud Spanner는 서버에 특수한 하드웨어 장비를 덕지덕지 발라놨다.
그리고 Cloud Spanner는 서버에 특수한 하드웨어 장비를 덕지덕지 발라놨다.
가장 압권인 부분이 TrueTime이란 것인데, 서버에 세슘 원자시계를 달아서 절대적인 시간을 즉시 구할 수 있게 한 것이다.
아무나 Spanner를 따라하지 못하고 어정쩡하게 하이브리드 시계로 땜빵한 아류작들만 있는 이유다.
타임스탬프 기반의 트랜잭션 제어
개략적인 컴포넌트는 소개를 한 것 같고, 본론으로 돌아와보자.
Spanner는 타임스탬프 기반으로 트랜잭션의 순서를 보장하는 기법을 사용한다.
Percolator가 타임스탬프를 트랜잭션에 저장해놓고 안맞으면 충돌을 발생시켜 실패하게 만드는 낙관적 쓰기였다면, Spanner는 타임스탬프에 기반하되 대기를 기반으로 트랜잭션 무결성을 보장하는 구조를 구현했다.
Spanner에서 트랜잭션은 다음과 같은 과정을 거친다.
기존 값을 가져와서 수정하는 쓰기 쿼리를 하나 날려본다고 가정해본다.
-
클라이언트가 트랜잭션을 시작하면, 관련된 Paxos Leader 중 하나가 Coordinator가 된다.
-
Paxos Leader는 쓰기 대상의 기존 값을 받아오고, 기존 값을 기반을 수정해서 메모리에만 일단 모아둔다. (쓰기 버퍼링)
-
Paxos Leader는 쓰기 버퍼를 읽고 모든 Paxos Group에 날리면서 2PC 복제를 시작한다. (Prepare)
-
각자의 노드가 트랜잭션을 받아 쓰기를 완료했다면, prepare 완료 시점 값 prepare_ts를 Coordinator에게 반환한다. (prepare_ts는 원자시계에서 받아온 값)
-
Paxos Leader는 모든 prepare_ts를 받아서, 가장 최신의 시간값을 commit_ts로 삼는다. (현재 Leader 노드의 now 값이 더 크다면 now를 commit_ts로 설정)
-
불확실성을 제거하기 위해 Commit Wait라는 프로세스를 시작한다. 방금 결정한 commit_ts가 모든 노드의 now보다 과거의 시간이 될때까지 기다리는 것이다. (한자릿수 ms 정도 대기)
-
Commit Wait가 끝나면 Commit이 최종적으로 완료되고 Lock을 해제 한다.
상당히 과정이 복잡한 편이다.
일단 시간에 대한 처리가 과민할 정도로 복잡하게 되어있는데, 그건 원자시계도 오차가 진짜 없는건 아니기 때문이다. 아주 미세한 오차가 있기도 하고, 그걸 실제로 서버로 가져오는 과정에서도 불가피한 딜레이가 생긴다.
대체로 아무리 느려도 1ms-7ms 정도의 오차가 발생한다. 일반 시계라면 수십-수백ms도 오차가 뜬다.
강한 읽기 (Strong Read)
Spanner는 꽤 독특한 읽기 방식을 가지고 있다.
A이라는 키값을 하나 write했지만, 노드 1,2에만 복제되고 노드 3에는 아직 복제되지 않았다고 치자.
그럴때 어떤 클라이언트가 A라는 키값을 노드 3로 접근하려고 하면 어떻게 될까?
일반적인 분산시스템에서는 없거나 옛날 값을 가리키도록 구현하지만, Spanner는 다르다.
Leader에게 해당 키값에 대한 최신 타임스탬프 값을 받아오고, 해당 타임스탬프와 동일한 값이 조회될때까지 무한대기를 탄다. 그래서 Read가 데이터를 확실히 불러오는 대신, 좀 오래 걸릴 수도 있다.
이 동작은 비활성화할 수 있다. 비활성화할 경우 옛날 값을 볼 수 있는 대신, 빠르게 Lock 없이 읽어온다.
Spanner의 장단점
장점
가장 큰 장점은, Paxos에 기반한 광범위한 분산 및 샤딩을 구현하기 때문에, 전세계에 분포되는 대륙간 클러스터를 훌륭하게 제공한다는 것이다.
가용성도 높다. Coordinator는 Paxos Leader 중에서 무작위로 선택되기 때문에, 단일 장애 지점이 없다.
장애시의 복구 능력도 좋다. Paxos Leader가 복제를 수행하다가 죽더라도, 다른 Paxos Leader가 로그를 읽어서 Commit/Abort를 결정한다.
그리고 타임스탬프를 활용하기 때문에 multi coordinator 환경에서도 트랜잭션 간의 순서를 보장할 수 있다. 단일 Coordinator라면 문제가 없지만, 가용성을 위해 multi coordinator를 사용하게 되면 트랜잭션이 반드시 꼬이게 되는데, 이걸 타임스탬프 기반으로 해결한 것이다.
단점
변형이긴 해도 2PC 기반의 접근법이기 때문에 쓰기 처리량이 높지 않고, Lock으로 인한 지연시간도 좀 있다. 그래서 동작 하나하나가 느린 편이다. 쓰기 부하가 높다면 우선적으로 고려할만한 대상은 아니다.
오픈소스가 아니며, GCP 서비스에만 종속되는데다 값도 상당히 비싸다.
기괴한 하드웨어 종속성 때문에 Spanner의 확실한 오픈소스 대체재도 없다. 오픈소스 DB에서 원자시계를 어떻게 붙이겠는가...
Spanner-like 구현체들
Spanner 외에도 Spanner의 영향을 받아 만들어진 오픈소스 카피캣이 꽤 있다.
CockroachDB, YugabyteDB가 대표적이다.
다만 이런 Spanner-like 오픈소스들은 당연하지만 원자시계같은걸 쓰진 못하고, HLC 같은 가상 시계 구현을 통해 정확도 높은 시간을 받으려고 노력한다.
참조
https://dbmsmusings.blogspot.com/2017/04/distributed-consistency-at-scale.html
https://www.yugabyte.com/blog/google-spanner-vs-calvin-global-consistency-at-scale/
https://docs.cloud.google.com/spanner/docs/transactions?hl=ko
https://www.yugabyte.com/blog/implementing-distributed-transactions-the-google-way-percolator-vs-spanner/
https://blog.searce.com/internals-of-google-cloud-spanner-5927e4b83b36
https://docs.cloud.google.com/spanner/docs/true-time-external-consistency?hl=ko#does_cloud_spanner_provide_serializability