분산 시스템과 분산 트랜잭션
 분산시스템에서 쓰기 트랜잭션을 복제하는 방법론들에 대해 정리해본다.
분산시스템에서 쓰기 트랜잭션을 복제하는 방법론들에 대해 정리해본다.
이것도 방법이 하나가 아니고, tradeoff에 따른 선택지들이 있다.
트랜잭션의 순서
분산 트랜잭션에서 중요하면서도 어려운 것이 순서다.
단일노드 시스템에서는 쓰기 트랜잭션이 아무렇게나 막 들어와도 아무튼 실제로 받은 순서대로 처리하면 되니 큰 문제가 없다.
근데 분산시스템으로 가면 말도 못하게 복잡해지기 시작한다.
쓰기 트랜잭션을 노드마다 분산하긴 해야하는데, 그냥 마구 쏴대면 어떤 노드는 A,B,C 순서로 트랜잭션을 처리하고, 어떤 노드는 B,C,A 순서로 처리하게 될 수도 있기 때문이다.
그러면 노드마다 데이터가 달라지는 끔찍한 현상이 발생한다.
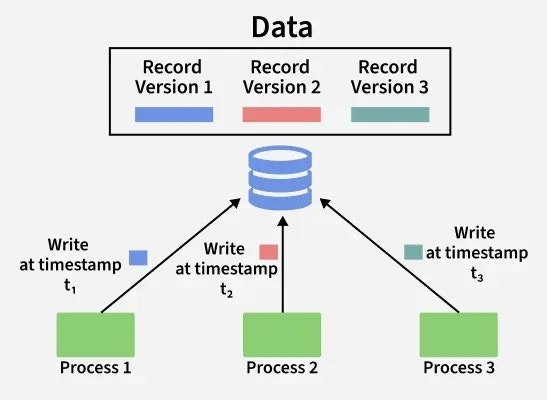
MVCC (Multi Version Concurrency Control)
MVCC는 DB에서 주요하게 사용되는 데이터 버전 관리 기법이다.
쉽게 말하면, 데이터의 수정과 삭제를 처리할때 실제로 데이터를 수정/삭제하는 것이 아니라, 데이터의 "새 버전"을 추가하고 새 버전을 최신 데이터로서 조회되게 한다는 것이다.
 https://www.geeksforgeeks.org/dbms/what-is-multi-version-concurrency-control-mvcc-in-dbms/
https://www.geeksforgeeks.org/dbms/what-is-multi-version-concurrency-control-mvcc-in-dbms/
이 시스템의 강점은, 트랜잭션의 롤백을 구현하는 것이 쉽고, 동시성 접근 제어나 높은 쓰기 부하 등을 효율적으로 처리할 수 있다는 것이다.
이건 분산시스템이 아닌 단일노드 시스템에서도 충분히 강력하지만, 분산시스템으로 가면 더 중요해진다.
대부분의 분산 DB들은 MVCC를 기반으로 데이터를 관리하고, 이를 통해 노드간의 트랜잭션 복제/롤백 등을 손상 없이 처리할 수 있게 구현한다.
특히나 빛을 발하는 부분은 읽기 처리량이다. 분산시스템에서 까다운게 개별 노드에 대한 읽기 처리인데, MVCC를 사용하면 Lock을 걸지 않고도 Read를 처리할 수 있다.
당장 RDB PostgreSQL, MySQL, OracleDB를 필두로 고전적인 RDB들도 MVCC를 기반 구조로 삼고 있으며, CockroachDB, CouchDB, YugabyteDB, Spanner 같은 분산시스템용 DB들도 대부분 MVCC를 토대로 쓰기 처리를 구현한다.
강력한 일관성: 2PC
가장 고전적이고 단순한 구현 방법은 2PC라는 것이다.
방법론 자체는 매우 단순하다.
쓰기 트랜잭션 A가 날라오면, 일단 모든 노드에 데이터 단위 Lock을 건다.
그리고 모든 노드에 A를 전파하고, 노드별로 쓰기 처리가 완료되면 COMMIT된 것으로 치고 Lock을 푸는 것이다.
https://blog.naver.com/sssang97/223465481384
단순하고 직관적인 구조 탓에 트랜잭션 순서가 꼬일 일도 없고, 트랜잭션의 롤백 구현도 간단한 편이다.
문제는 Lock이다. 뭐 하나 쓸때마다 전체 노드를 잠그니, 처리량이 매우 저조한 편이다.
하지만 고전적인 DB 분산 구성에서는 나름 여전히 현역이며, 대부분의 분산 DB들도 2PC의 변형을 사용한다. 후출할 Spanner-like 분산 구조도 2PC를 기반으로 덧댄 것이다.
MySQL, Oracle, PostgreSQL의 기본 분산 옵션은 일반적인 2PC를 사용하고, MongoDB의 WiredTiger도 2PC의 변형을 사용한다.
낙관적 일관성: Percolator
2PC가 전체 Lock을 걸고 느릿느릿하게 처리하는 비관적 처리방식이라면, percolator는 일단 다 때려넣은 다음에 충돌이 발생하면 적절히 후처리하는 lazy한 방식이다.
이건 여러가지 무결성이나 실시간 처리 능력을 포기하는 대신 높은 처리량과 장애 내구성을 가진다.
https://blog.naver.com/sssang97/224180833746
대표적으로 Google의 Bigtable이 이 방식을 통해 구현되었으며, TiKV라는 카피캣도 있다.
결정론적 트랜잭션: calvin
또 하나의 방법은, 트랜잭션의 순서를 관리하는 관리포인트를 추가하자는 것이다.
순서가 무작위로 복제돼서 노드로 이동하는게 문제면, 그냥 적당히 모아놨다가 원래의 최초 순서대로 동일하게 넘겨버리는 것이다.
https://blog.naver.com/sssang97/224179499697
이러면 묶어서 처리하므로 실시간 복제 딜레이는 다소 증가하지만, 지나친 Lock으로 인한 처리량 저하, 네트워크 레이턴시 등을 줄일 수 있다는 장점이 있다.
다만 트랜잭션의 롤백 구현이 어렵거나 비효율적이라는 단점이 있다.
그래서 실제로는 잘 안 쓰인다.
시간 기반의 비관적 트랜잭션: Spanner-like
엄밀한 일관성 수준이 필요하다면 사실 2PC를 쓰는 것이 가장 베스트다.
하지만 2PC를 쓰게 되면 생기는 문제가, 단일 master를 쓴다면 일관성이 보장되지만 multi master를 쓴다면 트랜잭션의 순서 꼬임이 발생할 수 있다는 것이다.
Spanner를 비롯한 Spanner-like DB들은 트랜잭션마다 타임스탬프를 박고, 시간을 기준으로 Commit Wait이라는 대기 과정을 거쳐서 꼬임을 방지한다.
이를 통해 이후의 트랜잭션이 항상 더 최신의 시간을 받도록 보장하는 것이다.
자세한 것은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/224182101886
메시지 기반의 순서 보정: HLC
spanner truetime의 대안으로서 사용되는 시간 관리 알고리즘이다.
주요 오픈소스 분산 DB들은 이 방식을 채용한다.
https://blog.naver.com/sssang97/224191423204
분산 트랜잭션이 없는 경우
분산 트랜잭션은 기본적으로 매우 무거울 수밖에 없는 구현 패턴이다.
그래서 분산 DB라도 쓰기 처리량을 극도로 중시하는 경우에는 분산 트랜잭션이 아예 없거나, 애매한 것만 있다.
CassandraDB
CassandraDB는 쓰기 처리량에 집중한 Key/Value DB고, LWT라는 경량 트랜잭션을 지원한다.
하지만 단일 파티션 내에서만 CAS 기반으로 동작하는데다, 네트워크 왕복이 많아 매우 느리다는 단점이 있다.
Saga와 Compensating Transaction
MSA 패턴에서 자주 등장하는 친구지만, 어떻게 보면 분산 트랜잭션과 비슷하다고 볼 수도 있다.
다만 기본적으로 동일 데이터의 단순 복제가 아니라서 좀 다르다.
그리고 Lock을 걸지 않고 롤백에 대해서만 보상 트랜잭션을 일일이 날려서 처리하는 방식이라 일관성을 거의 보장하지 않는다. 전체 commit이 완료되지 않아도 중간상태가 노출된다.
https://blog.naver.com/sssang97/223026977131
https://blog.naver.com/sssang97/223057488695