분산 트랜잭션: HLC (Hybrid Logical Clock)
HLC는 분산시스템, 분산 DB에서 트랜잭션의 순서 처리를 위해 사용되는 시간 처리 매커니즘이다.
모든 시계에는 오차가 존재하는데, 장비 간 오차가 존재하는 상황에서 개별 장비의 시간으로 트랜잭션을 생성하면, 트랜잭션의 순서가 실제 요청 순서와 크게 어긋날 수 있다. T1=>T2 순서래대로 쿼리를 날렸는데, 실제로는 T2=>T1 순서대로 적용되는 참사가 일어날 수 있는 것이다.
이럴때는 구글 Spanner의 TrueTime처럼 정확도가 매우 높은 원자시계를 쓰면 정말 좋지만, 그럴 수 없는 환경에서 사용되는 대안이라고 보면 된다.
Lamport Timestamp의 영향을 받았다.
기본 논리
Hybrid Logical Clock이라는 명칭이 붙은 이유는 논리 시계(Logical Clock)와 물리 시계를 결합했기 때문이다.
물리 시계의 시간값 외에도 논리적 시간 상한값을 통해서 이벤트의 발생 순서를 보장하는 것이다.
HLC에서는 시간 값을 3개의 필드를 가지는 튜플로 관리한다. (pt를 빼면 2가지)
PT(Physical Time)과 L(Logical Time), 그리고 C(Counter)다.
이 시간값들이 순서 처리를 위해 개별 트랜잭션에 포함된다고 보면 되는 것이다.
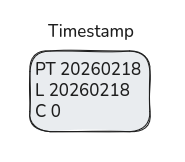 여기서 PT는 말 그대로 순수한 시간값이다. 개별 장치에 존재하는 시계로 뽑아낸 NOW 값이라고 보면 된다.
여기서 PT는 말 그대로 순수한 시간값이다. 개별 장치에 존재하는 시계로 뽑아낸 NOW 값이라고 보면 된다.
L과 C는 좀 다르다. 이 2가지는 트랜잭션을 전송할 때도 넣지만 노드 안에서 단일로 관리되는 전역변수다.
L은 시간값 중 최대값을 관리하는 변수다. L보다 큰 PT 값이 노드 안팎에서 생성된다면, 그걸로 항상 L 값을 갱신한다. 그러니까 다른 노드에서 더 큰 PT 값이 들어와도 그걸 채택한다는 것이다.
C는 증분형 카운터다. PT/L 값이 바뀌지 않는다면 0,1,2,3... 순서대로 단조롭게 증가한다. 이건 시간 값이 바뀌지 않았을때 순서를 나타내기 위한 보조적 값이다.
그림으로 다시 정리하면, 이런 구조가 되는 셈이다.
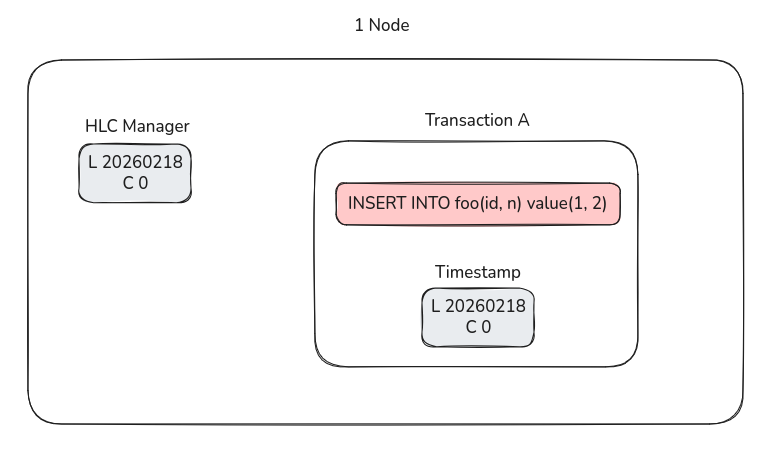 노드 단위에 HLC 타임스탬프 관리를 위한 중앙 저장소가 있고, 그걸 트랜잭션을 생성하고 전송할 때마다 증가시키며 트랜잭션 내에 주입해준다.
노드 단위에 HLC 타임스탬프 관리를 위한 중앙 저장소가 있고, 그걸 트랜잭션을 생성하고 전송할 때마다 증가시키며 트랜잭션 내에 주입해준다.
노드 간 순서 정렬 시나리오
자, 그러면 HLC는 어떤 방법으로 노드 간 트랜잭션의 순서를 보정할까?
시나리오를 하나 펼쳐보겠다.
다음과 같이 노드의 HLC 상태가 구성되어있고
Node A 상태: (l=100, c=2)
Node B 상태: (l=90, c=5) (B의 시계가 느림)
이 상태에서 단일 DB 클라이언트 세션이 T1, T2 순서대로 트랜잭션을 날리되, T1은 Node A에서, T2는 Node B에서 실행되게 한다.
그럼 일단 Node A가 T1을 먼저 받을 것이다.
pt가 101로 증가하고, HLC 값이 (l=101, c=0)이 될 것이다.
그러면 DB는 (l=101, c=0) 값을 포함해서 트랜잭션을 Node B에도 복제할 것이다. 이건 T2 처리 시점에 완료된다는 보장은 없다.
T1를 날리고 나면 Node B가 T2을 받는다.
근데 이 상황에서 Node B의 시계가 느려서 pt가 93이 나온다면, T2가 T1보다 앞 순서로 처리되는 문제가 생길 수 있다.
여기서 특기할 점은, T1을 처리할때 나온 타임스탬프를 T2 요청에도 메시지라는 이름으로 보내준다는 것이다.
이전 요청의 타임스탬프(l=101, c=0) 값을 함께 받았기 때문에 Node B는 순서를 판단할 수 있다. T2의 HLC 값은 (l=101, c=0)에서 증가한 l=101, c=1) 값이 된다.
이 HLC의 순서 보장 방식을 인과관계에 기반한 보정 방식을 인과 순서(Causal Ordering)라고 부른다.
vs Google TrueTime (Spanner)
관련 포스트
https://blog.naver.com/sssang97/224182101886
구글에서 사용하는 TrueTime-세슘 원자시계는 오차가 없진 않지만 매우 낮고 오차 수준이 명확하다.
대체로 7ms 미만이기 때문에 오차만큼을 기다려서(commit wait) 트랜잭션을 커밋하는 방식을 사용한다.
이런 구조 덕분에 Spanner는 거의 완벽한 트랜잭션의 외부 일관성(external consistency)을 보장할 수 있다.
다른 클라이언트끼리 트랜잭션을 마구 날려대더라도, 실제 발생 시간에 맞춰서 트랜잭션을 정렬할 수 있는 것이다.
하지만 HLC는 이러한 방식을 적용하기 어렵다. 물리 시계의 오차가 최대 얼마나 되는지 모르기 때문이다.
그래서 적당히 commit wait을 줄 수 있는 근거가 없고, 이론적으로 완벽한 일관성을 보장하기는 어렵다. 그래서 인과관계에 기반한 트랜잭션 일관성만을 보장한다.
단일 DB 클라이언트 내에서 전송한 트랜잭션들끼리만 순서를 보장할 수 있는 것이다.
구현체
오픈소스 기반의 분산 DB들은 대부분 이걸 사용해서 트랜잭션 순서 보장을 구현한다.
대표적으로 CockroachDB, YugabyteDB 등이 HLC를 사용한다.
참조
https://www.yugabyte.com/blog/implementing-distributed-transactions-the-google-way-percolator-vs-spanner/
https://martinfowler.com/articles/patterns-of-distributed-systems/hybrid-clock.html
https://medium.com/geekculture/all-things-clock-time-and-order-in-distributed-systems-hybrid-logical-clock-in-depth-7c645eb03682
https://arpitbhayani.me/blogs/clock-sync-nightmare/