쿠버네티스 안내서
 2026.02.24 작성
2026.02.24 작성
2026.03.06 수정
쿠버네티스는 대표적인 컨테이너 오케스트레이션 프레임워크다.
여기서는 쿠버네티스가 어떤 것인지, 왜 쓰는지, 어떤 구조를 갖고 있고 어떻게 사용할 수 있는지를 대략적으로 살펴보는 시간을 가져보겠다.
깊게 파고드는 것을 목적으로 하진 않는다. 방향성만 잡아주는 정도로 끝내려고 한다.
이게 무엇인가
쿠버네티스는 근 몇년간 hype을 가장 크게 받은 기술 중 하나일 것이다.
과하게 부풀려진 감은 있지만, 그럼에도 강력하고 훌륭한 기술임에는 틀림이 없다.
쿠버네티스는 Docker와 그 역사성을 공유한다.
Docker는 컨테이너라는 약한 가상화 단위를 통해 개별 서버를 격리된 객체로서 다루고, 이를 편리하게 배포할 수 있게 하는 신세계를 열어줬다.
이런 개념이 마냥 새로운 것은 아니었다. 대중화되지 않았을 뿐이다. 다들 자기들끼리 알음알음 쓰던 것을 Docker가 오픈소스로 풀어버리고, Docker Image 규격 자체를 표준 컨테이너 이미지로 못박아버리면서 컨테이너 환경의 발전을 트리거한 것이다.
하지만 Docker 자체로는 한계가 명확했다.
단일 장비에서 적당히 실행하는 것에는 문제가 없지만, 장비가 여러대인 상황에서는 제대로 활용하기가 어렵고 불편했다. 서버를 리소스 상황에 맞춰서 요리조리 배치하고, 스케일아웃하고, 노드별로 분산해서 가용성과 유연성을 챙기거나 하는 것이 매우 어렵거나 불편했기 때문이다.
게다가 Docker는 그 자체로 개별 노드에 종속된 도구이기 때문에 매번 그 장비에 들어가서 실행을 해줘야 한다.
쿠버네티스는 이런 배경에서 등장했다고 볼 수 있다. 초기에는 Google에서 내부 인프라 관리를 위해 만들어졌다가, 그것이 오픈소스화되어서 CNCF라는 전용 재단이 생긴 것이다. 그렇게 발전하고 발전해서 지금에 이른 셈이다.
언제 쓰는가?
그럼 쿠버네티스는 언제 써야할까? 이건 제반사항에 따라서 크게 달라질 수 있다.
만약 온프레미스 환경이고, 고성능 장비가 3대 이상이고, 서버 장비 하나당 여러개의 작은 서버를 띄워야 한다면 쿠버네티스는 매우 적합한 선택이 될 수 있다.
이런 경우에는 쿠버네티스를 선택할 당위성이 충분하다.
하지만 Cloud를 쓰는 경우에는 좀 애매할 수 있다. 손익을 잘 따져봐야 한다.
Public Cloud와 쿠버네티스 (AWS)
대부분의 클라우드들은 EKS(AWS), GKE(GCP), AKS(Azure) 같은 관리형 쿠버네티스 클러스터를 제공한다. 하지만 이건 기술 선택에 미묘한 딜레마가 있다.
쿠버네티스의 가장 근본적인 동기는, 멀티노드 환경에서의 failover와 유연한 배치 등을 통한 리소스 활용에 있다.
문제는 클라우드 서비스들에서 컨테이너 기반 서비스들이 이미 완성형으로 제공된다는 것이다.
대표적으로 ECS 같은 것이 있다. 이건 장애가 나면 그냥 AWS에서 알아서 재실행해서 띄워주고, 내부통신도 ECS Connect로 잘 엮을 수 있다. 그냥 있는거 쓰면 알아서 잘 해주고 손도 덜 가고, 가용성 보장도 잘 되는데, 저런걸 써야할까?
쿠버네티스의 단점은 입문비용과 관리비용이 높다는 것이다. 초기 세팅도 상당히 공임이 많이 들고, 지속적으로 운영하는데 드는 수고도 결코 적지 않은 편이다. 괜히 쿠버만을 다루는 Devops 직종이 부풀어오른 것이 아니다.
물론 Cloud의 관리형 클러스터에도 이점이 없는 것은 아니다.
(ECS 같은) 관리형 컨테이너 서비스를 쓰는 것보다는 프로비저닝 요금이 더 저렴할 수 있고, 서버들끼리 리소스를 적절히 공유해서 CPU 리소스 사용량을 효율화할 수 있다. 사용량이 커지는만큼 컴퓨팅/비용 효율성에서는 고점이 더 높다.
그리고 자유도가 높다. 쿠버 환경에 널려있는 플러그인들을 통해 다양한 세팅을 사용할 수 있다.
이런 비용/컴퓨팅 효율성으로 얻는 이득과 자율성에서 얻는 이점이 쿠버의 운영 비용을 상쇄하고 넘어선다면 Cloud의 관리형 클러스터도 고려해볼만한 선택지가 될 수 있다.
아, 그리고 쿠버네티스를 도입하는 이유로 "자체 클라우드 구축을 통해 벤더 종속성을 줄인다"는 표현을 자주 쓰던데, 클라우드의 관리형 클러스터를 쓰면 완벽하게 벤더 락인에 걸린다.
Service나 볼륨 관리 같은 부분들은 무조건 해당 클라우드 서비스를 쓰도록 강제되기 때문이다.
애초에 쿠버네티스는 Core 부분만 정해져있고 바깥부분은 붙이기 나름이라서, 완벽하게 종속성 없이 구성하는 것이 불가능한 기술이다. 환경에 따라 달라진다.
마이크로서비스 아키텍쳐 (MSA)
쿠버네티스와 항상 단짝처럼 붙어서 다니던 친구가 바로 MSA라는 친구다.
사실 쿠버와 MSA에 직접적인 인과관계가 있지는 않다.
쿠버네티스를 쓰면 작은 서버들을 좀 쉽게 띄우고 분산해서 사용할 수 있긴 하지만, 꼭 쿠버를 써야만 MSA가 되는 것도 아니고, MSA가 필요해서 쿠버를 쓰는건 아니다.
https://blog.naver.com/sssang97/223068044207
쿠버네티스와 배포판
쿠버네티스를 설치하기 위해서는, 대개 배포판을 하나 선택해서 해당 배포판의 세팅 그대로 설치를 한다.
그런데 쿠버네티스도 리눅스처럼 배포판이 여러개가 있다.
쿠버네티스가 그 자체로 모든 것을 구성하고 책임지는 것이 아니라, Core만을 구현해놓은 상태에서 원하는대로 레고처럼 조립하는 식으로 기능하기 때문이다.
컨테이너 런타임, 네트워크 구성(CNI), 볼륨 관리, runtimeclass, 상태 저장용 DB 같은 부분들은 구성하기에 따라 천차만별로 달라지고, 그 선택에 따라서도 성능이나 편의성 tradeoff가 극심하게 갈라진다.
유명한 쿠버 배포판에는 kubeadm, k3s, kubespray, minikube 등이 있다.
minikube는 학습자를 위한 초-경량 쿠버네티스 배포판이다. 한계가 많아 서비스용으로는 거의 사용할 수 없고, 단일노드에서 쿠버의 동작 원리를 이해하는 정도로만 사용할만하다.
https://blog.naver.com/sssang97/223099759455
k3s는 중소규모에 적합한 경량 쿠버네티스 배포판이다. 구성이 매우 쉽기도 하고, 최소 소모 사양도 적다.
튜닝을 위한 커스텀도 가능하나, 대규모를 고려해서 만들어진 것은 아니라서 고치기 어려운 병목지점이 몇개 있다.
하지만 노드가 수십-백개 정도인 클러스터만 해도 충분히 견딜만하다.
https://blog.naver.com/sssang97/224161834484
kubeadm은 쿠버네티스 커뮤니티에서 가장 권장하는 도구다.
설치부터 매우 번거롭고 열받는데, 자유도도 높고 성능 한계도 가장 높다. 정말 모든 것을 다 만져보고 튜닝해보고 싶거나, 대규모 클러스터를 고려해야 한다면 우선 고려할만하다.
kubespray는 ansible 환경을 상정하고 만들어진 쿠버네티스 배포판이다. 정확히 말하면 배포판은 아니고 kubeadm을 기반으로 한단계 레이어를 올린 것이다.
이미 ansible이 구성되어있다는 전제 하에서만 그 위에 설치를 하게 도와준다. 애초에 ansible 자체가 엔터프라이즈용 솔루션이라서 대규모에 더 적합하다.
난 개인적으로는 k3s를 추천한다.
kubeadm으로 하나하나 조립하면서 얻어맞고 하는것도 괜찮긴 한데, 처음부터 그럴 필요는 없다.
k3s가 딱 편의성과 적당한 자율성, 실용성이 적절히 조화된 중간점이다.
클러스터 구조
쿠버네티스는 멀티노드를 상정한 분산시스템이고, 고전적인 master-slave 구조를 기본 구성으로 사용한다.
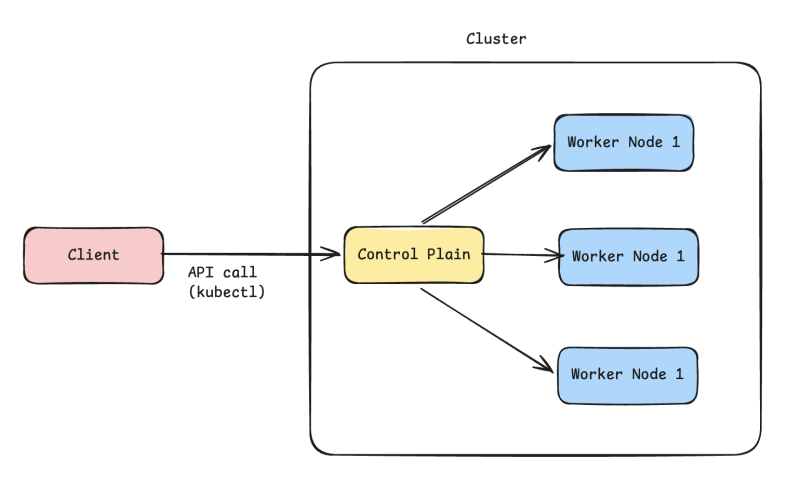 컨트롤 플레인 노드가 중앙제어 시스템 역할을 한다. 이게 모든걸 책임지고 실제로 서버를 노드에 띄우거나 관리하는 역할을 총괄하는 것이다. 클라이언트로부터 요청을 받는 것도 컨트롤 플레인의 책임이다.
컨트롤 플레인 노드가 중앙제어 시스템 역할을 한다. 이게 모든걸 책임지고 실제로 서버를 노드에 띄우거나 관리하는 역할을 총괄하는 것이다. 클라이언트로부터 요청을 받는 것도 컨트롤 플레인의 책임이다.
그리고 control plane은 단일 장애 지점이기 때문에 세심하게 관리해야 한다. 이래저래 구성하면 control plane도 고가용성을 구성하는 것이 가능하긴 한데, 일이 좀 커진다.
이런 이유에서 컨트롤 플레인 노드는 따로 서버를 띄우지 않게 하고 관리 책임만 부여하는게 일반적인 관행이기도 하다.
Pod와 리소스 단위들
k8s에서 가장 핵심이 되는 구성요소는 Pod와 Deployment, Service다.
일단 이 3개만 알아도 그럴듯한 서버는 구성할 수 있기 때문이다.
https://blog.naver.com/sssang97/223013640738
https://blog.naver.com/sssang97/223027848144
https://blog.naver.com/sssang97/223084158042
그 외에는 좀 보조적인 느낌이다. 보통 한번씩 쓰게 되니, 알아는 두는 것이 좋다.
https://blog.naver.com/sssang97/223028585194
https://blog.naver.com/sssang97/223028688449
https://blog.naver.com/sssang97/223084166458
https://blog.naver.com/sssang97/223101036344
https://blog.naver.com/sssang97/224167915191
https://blog.naver.com/sssang97/223101386886
https://blog.naver.com/sssang97/223134069209
배포 전략과 확장
서버를 안정적으로 배포하고 운영하는데 필요한 조건들이 몇가지 있다.
헬스체크를 통한 서버의 생존 확인/재부팅
배포 전략 설정을 통한 무중단 배포 구성
그리고 부하에 기반한 서버의 수평확장-오토스케일링이다.
쿠버네티스는 Pod 수준에서 헬스체크를 정의하고 이를 통해 서버의 정상 동작 여부를 검증하는 기능을 제공한다.
이를 probe라 부른다.
https://blog.naver.com/sssang97/224200739335
재배포 전략은 기본적으로 deployment 레벨에서 지원된다.
이를 통해 서버를 중단 후 배포할지, 아니면 점진적으로 배포할지, 배포 속도나 down/up 타이밍을 어떻게 조절할지를 선택할 수 있다.
https://blog.naver.com/sssang97/223028645109
쿠버네티스는 수평 확장 기능을 기본적으로 제공한다. 쿠버네티스의 자체 내부 메트릭을 통해서 목표치가 될때까지 자동으로 서버를 늘리거나 줄이게 만들 수 있다.
https://blog.naver.com/sssang97/224200719515
쿠버네티스와 네트워크
네트워크에 대한 내용은 제대로 다루면 길어질 수 있으므로, 별도 포스트로 분리한다.
이것도 상당히 중요하다.
https://blog.naver.com/sssang97/224175733657
쿠버네티스와 디스크
디스크는 네트워크만큼이나 까다로운 관리 지점 중 하나다.
임시 디스크를 서버에 붙이는건 별거 아니지만, 지속적으로 유지하고 관리해야하는 영속성 디스크를 다루는 것은 고려해야할 지점이 많다.
다음은 쿠버네티스에서 디스크를 다루는 방법에 대한 글이다.
https://blog.naver.com/sssang97/224197484636
리소스의 제한
쿠버네티스를 쓰는 이유 중 하나는 단일 장비에 여러개의 서버를 유연하게 구겨넣는 것이다.
근데 무턱대로 마구잡이로 구겨넣었다가는 장비 전체가 뻗는 불상사가 일어날 수 있을 것이다. 웬 정신나간 서버가 메모리를 100GB씩 먹어댄다고 하면 어떻겠나?
그래서 k8s는 Pod 단위에 리소스 요청량과 최대 상한값을 지정할 수 있게 해주고, 사용을 적극 권장한다.
그래야 이 서버가 대충 얼마나 쓰는지 알고서 적절히 배치를 해줄 수 있으며, 실제로 한도를 넘었을 때도 스로틀링을 걸거나 서버를 터뜨려서 전체 장비에 문제를 주는 것을 방지할 수 있기 때문이다.
자세한 것은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/223659644778
https://blog.naver.com/sssang97/224203378203
Node의 분산과 배치(scheduling)
또 쿠버네티스를 쓰는 주된 동기 중 하나가 이것이다.
서버를 적절한 노드에 배치하는 것.
배치하지 말아야할 노드에 배치하지 않고, 배치하길 원하는/배치해도 되는 노드에 배치하는 것.
Taint는 노드 수준에서 일종의 블랙리스트를 걸어버리는 기능 단위다.
노드에 Taint가 붙었다면 이 노드에는 서버를 배치하지 않기를 원한다는 것이다.
https://blog.naver.com/sssang97/223645592718
보통 메모리나 디스크가 부족하다거나 할때 벽을 치고 추가적인 서버 할당을 막는 역할을 한다.
그 외에도 다양한 분산/배치 조건을 줄 수 있다.
Pod에 배치되길 원하는 노드명을 직접 명시할 수도 있고, nodeSelector를 통해 node의 label에 기반해서 Pod를 배치할 수도 있다.
affinity를 사용하면 이 서버와 저 서버가 같은 노드에 실행되어야 한다거나, 서로 다른 노드에 실행되어야 한다거나 하는 복잡한 배치 구성까지도 가능하다.
이에 대한 자세한 내용은 별도 포스트를 참조한다.
https://blog.naver.com/sssang97/223647137454
helm
k8s 스택 중에서는 서드파티인데도 거의 기본 도구처럼 사용되는 것이 몇가지 있다.
그 중 대표적인 것이 helm이다.
helm은 yaml 노가다를 좀 줄이고 볼만하게 꾸며주는 역할을 하는 템플릿 생성기-컴파일러로서의 역할도 하고, 쿠버네티스 구성을 패키지(Chart)로서 관리하고 배포-설치하게 해주는 라이브러리 공급자로서의 역할도 한다.
이거 없으면 많이 고통스럽다. 일단 깔고 보는 것이 좋다.
https://blog.naver.com/sssang97/223084225599
https://blog.naver.com/sssang97/224179368971
argocd
쿠버를 좀 만져보다보면 yaml 파일들이 정신없이 휘날리는 광경을 볼 수 있다.
이것도 대중없이 쓰다보면 관리가 개판나기 쉬운데, 쿠버네티스의 yaml도 일반적인 프로그램과 마찬가지로 엄중한 관리가 필요하다.
argocd는 gitops 기반의 쿠버네티스 리소스 관리를 위한 기본 도구다.
github에 쿠버네티스 yaml을 올려두면, 그걸 argocd가 알아서 읽고 반영해주는 역할을 하는 것이다.
편하기도 하고, 자연스럽게 git history 기반으로 내역을 관리하게 돼서 운영상의 이점도 꽤 생긴다.
https://blog.naver.com/sssang97/223112272539
https://blog.naver.com/sssang97/223112355237
kustomization
helm만큼은 아니지만 꽤 널리 사용되는 쿠버네티스용 템플릿 생성기다.
반복되는 코드를 좀 재사용하고 간결하게 꾸며주는 역할을 한다.
https://blog.naver.com/sssang97/223659611646
배포 전략과 gitops
쿠버네티스에서는 보통 gitops 기반의 배포 전략을 선호하는 트렌드가 있다.
그 말인즉슨, git으로 쿠버 리소스를 전부 관리하고, git을 변경하는 형태로 배포를 하자는 것이다.
그래서 gitops를 한다고 하면 ArgoCD가 거의 일체형으로 함께 붙어다니곤 한다.
https://blog.naver.com/sssang97/223122991133
여기에도 대략 2가지 선택지가 있다.
- 재배포할 컨테이너 이미지를 레지스트리에 push한 다음, 배포자가 직접 이미지를 git에서 갱신하는 방법이 하나 있고
- 재배포할 컨테이너 이미지를 레지스트리에 push한 다음, 백그라운드 태스크가 새로운 이미지 push를 감지해서 git을 갱신하거나 git 갱신 없이 바로 수정하는 방법이 하나 있다. (ArgoCD Image Updater)
2번의 경우에는 Image Updater라고 전용 라이브러리가 있는데, 1번은 딱히 없는거같다. 다들 직접 만들어쓰나?
https://blog.naver.com/sssang97/223134537766
편의성 CLI 도구
k8s는 그냥 생짜로 쓰면 불편한 것이 한두개가 아니다. 특히 기본 CLI인 kubectl이.
그냥 리소스가 뭐가 있는지 모니터링하고 로그 보거나 하는 것도 상당히 불편한 편이다. 명령들이 하나같이 장황하고 ux와는 거리가 멀다. 이건 그냥 쿠버네티스 팀이 이런 자잘한 편의성에 관심이 없는 탓이 크다.
k9s라는 CLI 기반 시각화 도구를 쓰면 리소스의 모니터링이나 제어를 꽤 간편하게 할 수 있다.
https://blog.naver.com/sssang97/223100877802
이거 말고 대체제가 몇가지 있긴 한데, k9s보다는 기능의 다양성이 부족한 편이다.
편의성 WEB UI 도구
headlamp는 쿠버네티스 리소스를 웹 UI로 보고 제어할 수 있게 해주는 편의성 도구다. 상기한 k9s의 WEB UI 버전이라고 보면 된다.
이 용도로 원래 kubernetes-dashboard라는 게 있었는데, 그거 deprecated되고 대체재로 지목된 녀석이다.
만듦새가 꽤 괜찮으니 추천한다.
https://blog.naver.com/sssang97/224196390405
권한 관리
쿠버네티스는 API를 기반으로 기능을 제어할 수 있게 다 뚫어놨다보니, 그걸 제어하기 이후나 권한 관리 기능도 빡빡하고 다양한 편이다.
일반적으로는 건드릴 일이 흔치는 않다만, 직접 operator를 만들거나 하면 건드릴 일이 종종 생긴다.
https://blog.naver.com/sssang97/223476409094
고급: operator 만들어보기
쿠버네티스 환경이 이렇게 크게 발전할 수 있었던 이유는 확장성이다.
Restful 기반으로 거의 모든 기능을 제어할 수 있게 해줬기 때문에, 쉽게 보조 프로그램들을 만들 수 있었다.
이런 쿠버네티스용 보조 플러그인들을 operator라고 부른다.
이 또한 k8s 위에서 pod로 실행되는 프로그램임은 동일하다. 쿠버와 직접 소통하는 것이 다를 뿐이다.
다음 포스트들은 operator를 직접 만드는 것과 관련된 내용들이다. 만드는 것이 어렵지는 않다.
https://blog.naver.com/sssang97/223114653465
https://blog.naver.com/sssang97/223460590757
https://blog.naver.com/sssang97/223461756266
https://blog.naver.com/sssang97/223464118742
고급: GPU 관리
요즘 하도 AI니 MLOps니 하면서 gpu 머신 다룰일이 많아지다보니, 쿠버로 gpu 리소스를 제어할 일도 꽤 흔해졌다.
gpu 관리는 쿠버네티스 자체의 기본적인 역할은 아니지만, 서드파티로서 제공이 되긴 되고, 훌륭하진 않지만 적당히 쓸만은 하다.
https://blog.naver.com/sssang97/224181717076
추가 툴체인을 사용하면 GPU에 대한 메트릭도 구성 가능하다.
https://blog.naver.com/sssang97/224196876242
고급: 메트릭 구성
대부분의 서버 시스템이 그렇지만, 중요한 것은 당장 찍어내고 만드는 것보다 운영이다.
소프트웨어 라이프타임에서 대부분의 시간은 운영과 유지보수를 통해 이뤄지며, 운영에 필요한 메트릭을 적절히 구성하는 것은 devops의 가장 기본적인 소양이라고 할 수 있다.
k8s에서는 보통 메트릭을 prometheus에 저장하고, grafana로 보는 것이 국룰이다.
kube-prometheus-stack이란 prometheus 오피셜 패키지를 설치하면 grafana, prometheus가 기본으로 깔리고 메트릭도 자동으로 쌓인다.
https://blog.naver.com/sssang97/224176325746
메트릭만 쌓이면 뭐하겠는가? 문제가 생겼을 때 메트릭 기반 빠르게 알림을 받는 것도 중요하다.
kube-prometheus-stack를 통해 prometheus를 설치했다면, alertmanager라는 서브 플러그인을 통해 문제가 생겼을때 Slack 등의 메신저로 알림이 오게 할 수 있다.
https://blog.naver.com/sssang97/224176666438