[k8s] nvidia/gpu-operator로 메트릭 대시보드 구성 (dcgm-exporter)
gpu 서버를 가져다가 운영을 하게 되면, 당연히 안정적인 운영과 최적화를 위해서 메트릭을 쌓고 가시성을 확보할 필요가 생긴다.
nvidia gpu를 쓰는 경우에는 nvidia에서 제공하는 gpu operator라는 종합패키지가 있다.
여기 안에 dcgm-exporter라는 수집기가 있는데, 이게 노드마다 분산되어있는 gpu의 메트릭을 수집해서 prometheus에 통합하게 해주는 역할을 한다.
여기서는 dcgm-exporter, prometheus, grafana를 사용해서 gpu 관측성을 확보하는 방법을 정리해본다.
사전 조건
nvidia gpu가 있고, 노드마다 nvidia 드라이버가 깔려있어야 한다.
nvidia container runtime도 깔려있으면 좋다.
https://blog.naver.com/sssang97/224181717076
helm으로 설치
가장 편리한 설치 방법은 helm을 사용하는 것이다.
helm install gpu-operator nvidia/gpu-operator \
--namespace gpu-operator \
--create-namespace \
--set driver.enabled=false \
--set toolkit.enabled=false \
--set devicePlugin.enabled=false \
--set dcgm.enabled=true \
--set dcgmExporter.enabled=true \
--set dcgmExporter.serviceMonitor.enabled=true \
--set dcgmExporter.serviceMonitor.additionalLabels.release=prometheus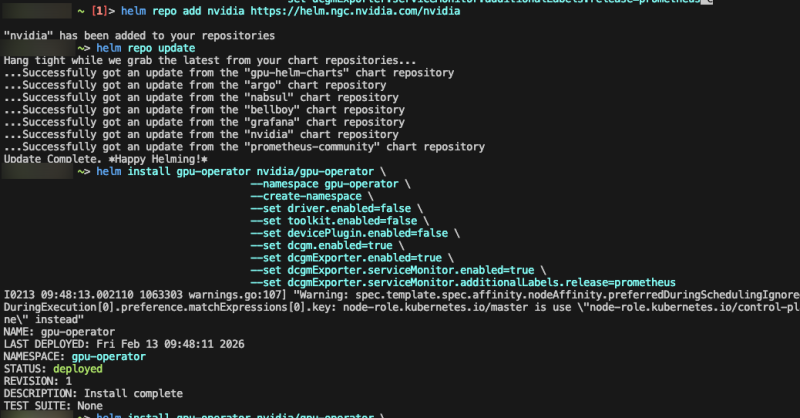 원하는 것만 골라서 설치할 수 있다.
원하는 것만 골라서 설치할 수 있다.
내 경우에는 driver가 이미 깔려있기 때문에 관련 플래그를 false로 넣고 설치했다.
그러고 나면 다음 명령어로 배포 상태를 확인할 수 있다.
kubectl get all -n gpu-operator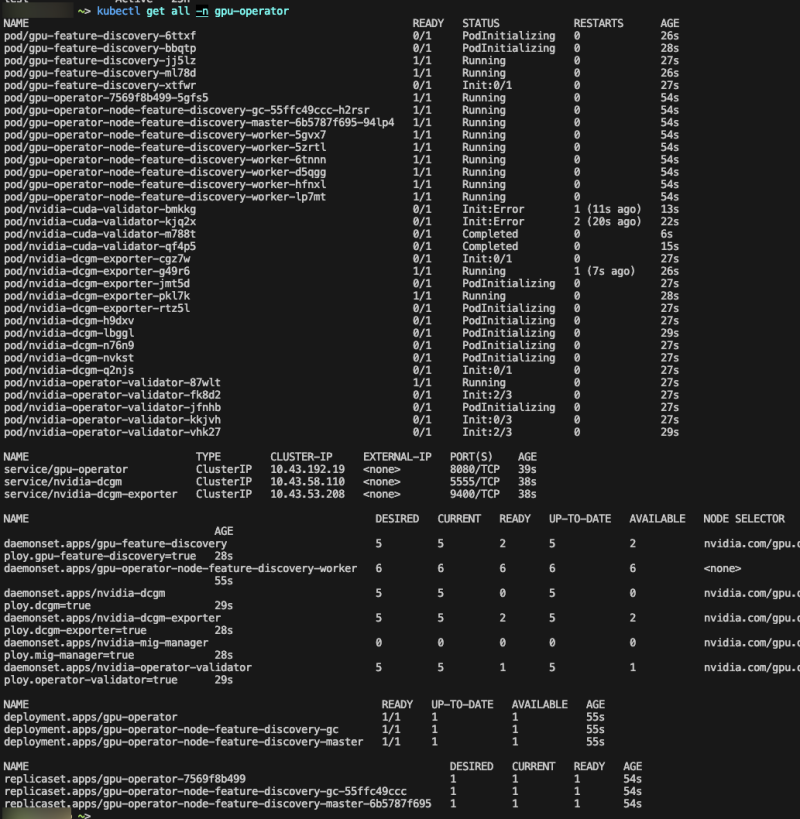 좀 에러가 날 수도 있는데
좀 에러가 날 수도 있는데
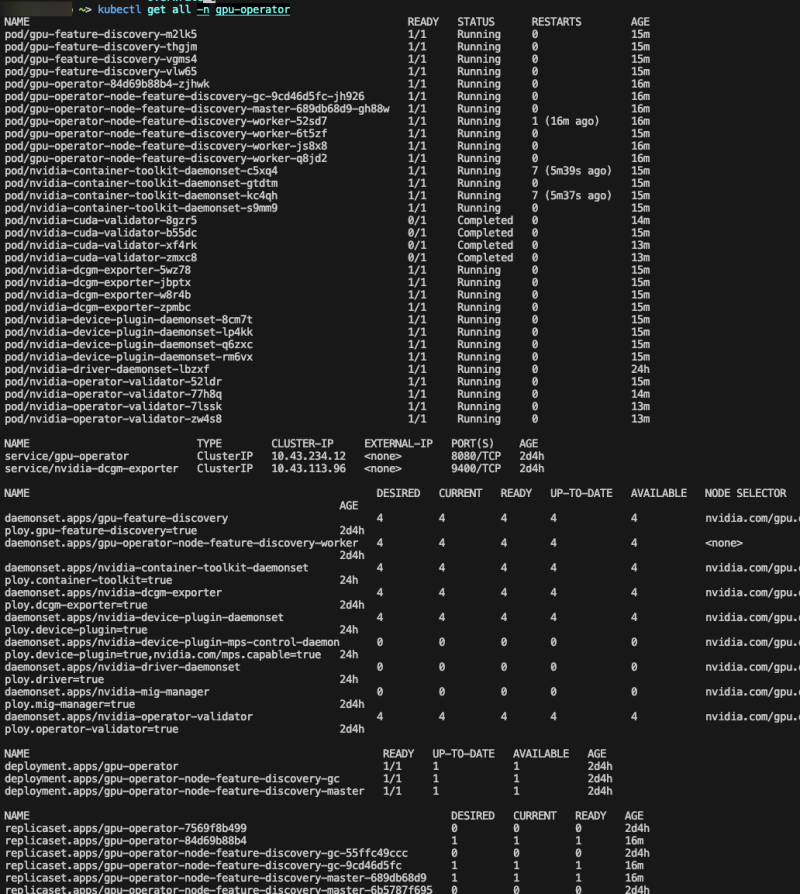 이렇게 오류가 하나도 없어야 잘 깔린 것이다.
이렇게 오류가 하나도 없어야 잘 깔린 것이다.
문제: non-GPU 노드에 프로비저닝되는 경우
gpu-operator 관련 pod가 gpu가 없는 노드에 스케줄링됐다가 ContainerCreating 모드에서 무한 대기 상태에 빠지는 경우가 있다.
원래는 이게 알아서 gpu가 있는 노드에서만 실행되는게 맞는데, 엔비디아가 문제인지 뭐가 문제인지 잘 못알아먹고 무작정 띄울 때가 있다.
가장 확실한 방법은 gpu가 없는 노드에 taint를 붙이는 것이다. 그럼 gpu 관련 리소스들이 해당 노드에 스케줄링되지 않을 것이다.
kubectl taint node processor-1 nvidia.com/gpu.present:NoSchedule
문제: 엔비디아 드라이버 버전 충돌
엔비디아 아니랄까봐 이것도 버전 호환성 문제가 극심하다.

 버전 때문에 노드마다 설치가 되는 노드가 있고 안되는 노드가 있을 수 있다.
버전 때문에 노드마다 설치가 되는 노드가 있고 안되는 노드가 있을 수 있다.
내 경우에는 일부 노드에 이런 오류가 떴는데, nvidia 드라이버의 버전이 다르기 때문이었다.
현재 기준으로 설치되는 gpu-operator의 버전은 v25.10.1인데, 이건 cuda-validator가 CUDA 13.x 기반으로 빌드돼 있어서 그 아랫버전에서는 실패할 수 있는 것이다. 기본적인 하위호환성도 못맞춘다.
잘 해줬으면 좋겠지만 엔비디아가 언제는 그런 적이 있었나?
아무튼 이건 알아서 돌아갈만한 버전을 잘 골라서 --version 플래그로 다시 설치를 해줘야 한다.
내 경우에는 24 버전으로 하니까 됐지만, 상황에 나쁜 경우에는 그 어떤 버전을 써도 안될 수도 있다.
Prometheus에 메트릭 통합하기
먼저 다음 리소스를 정의해서 생성한다.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nvidia-dcgm-exporter
namespace: gpu-operator
labels:
release: prometheus
spec:
namespaceSelector:
matchNames:
- gpu-operator
selector:
matchLabels:
app: nvidia-dcgm-exporter
endpoints:
- port: gpu-metrics
path: /metrics
interval: 30svim monitor.yaml
kubectl apply -f monitor.yaml
그리고 잠깐 기다렸다가, 프로메테우스에 쌓였는지 확인한다.
up{namespace="gpu-operator"}
up{service="nvidia-dcgm-exporter"}
DCGM_FI_DEV_SM_CLOCK
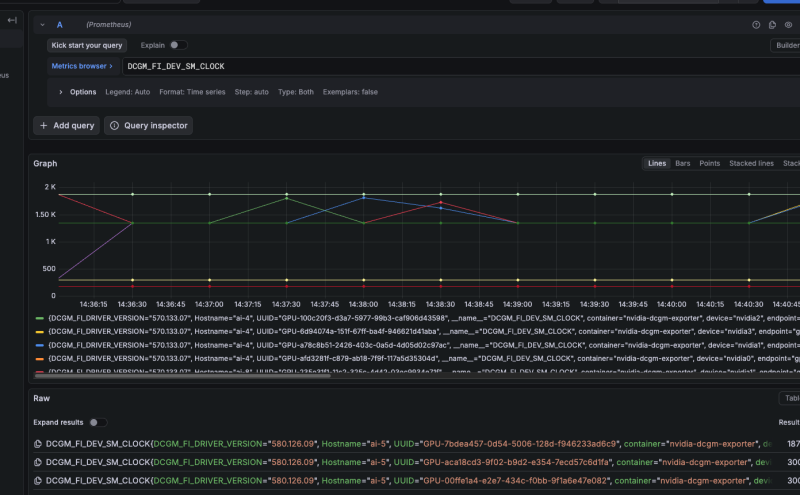 이렇게 다 잘 뜨면 메트릭 자체는 잘 쌓인 것이다.
이렇게 다 잘 뜨면 메트릭 자체는 잘 쌓인 것이다.
만들자마자 쌓이지는 않고, 몇분정도 딜레이가 있을 수 있다.
Grafana 대시보드 구성
그럼 이제 저걸 붙여서 대시보드를 구성하면 된다.
적당히 오픈 라이브러리에서 DCGM Exporter 기반으로 된 것을 가져다가 붙이면 된다.
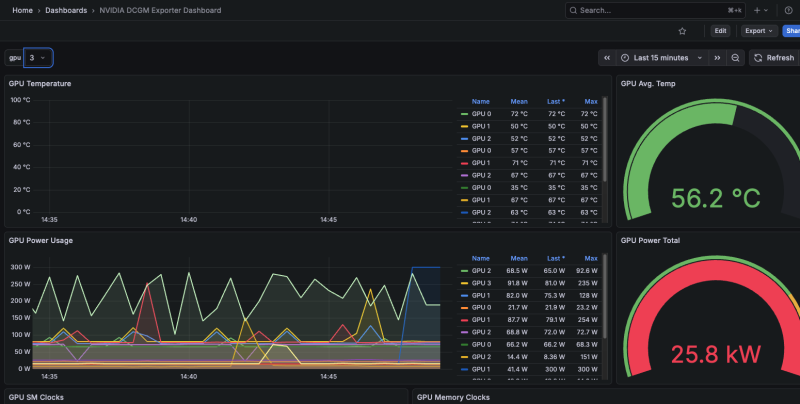 근데 이게 이것저것 있긴 한데, 딱 엄청 잘 만들었다싶은건 없어서 직접 커스텀을 해야할 확률이 높겠더라.
근데 이게 이것저것 있긴 한데, 딱 엄청 잘 만들었다싶은건 없어서 직접 커스텀을 해야할 확률이 높겠더라.
나도 뭔가 다 애매해서 직접 깎아서 쓰고 있다.
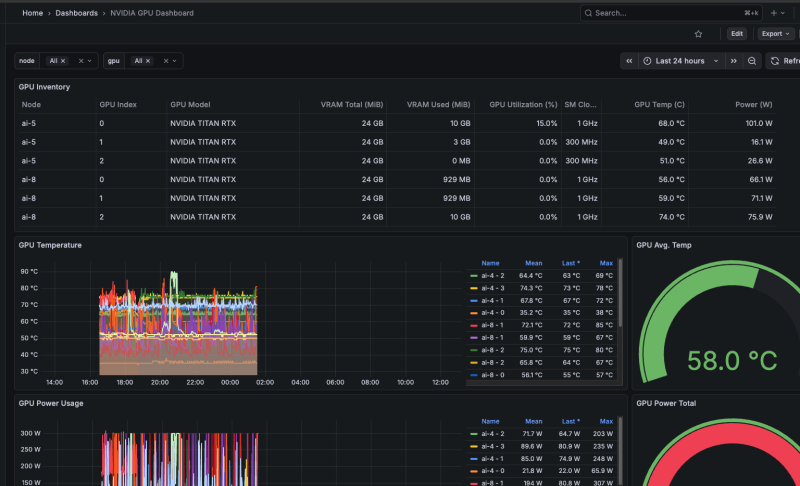
내가 오픈소스 베이스 가져다가 직접 깎은 것.
참조
https://docs.nvidia.com/datacenter/dcgm/latest/dcgm-api/dcgm-api-field-ids.html
https://github.com/NVIDIA/dcgm-exporter
https://nyyang.tistory.com/194
https://github.com/NVIDIA/gpu-operator/issues/1274