[k8s] 디스크와 볼륨
컨테이너 스택을 쓰다보면 가장 골치아픈 부분 중 하나가 볼륨, 즉 디스크에 대한 관리다.
디스크는 GPU 다음으로 고장률이 높고 안정성과 성능이 떨어지는 장비다.
뿐만 아니라 디스크는 "상태"를 관리하는 수단이기에 더욱 까다롭다.
쿠버네티스의 주요 강점들은 본질적으로 무상태성(Stateless)이라는 디자인 특성에서 나오기 때문이다.
쿠버네티스의 Pod들은 적어도 논리적으로는, 상태를 가지지 않고 어느 장비에서 실행하든 똑같은 동작을 하는 것을 목표로 한다.
그래야만 장애가 나서 다른 장비로 failover를 하든, 리소스 상황 때문에 서버를 여러 장비에 분산하든 간에 동등한 결과를 기대할 수 있기 때문이다.
디스크를 사용하는 시점에서 이런 부분과 상충되는 지점이 생기기 시작한다.
여기서는 디스크 관리 방식에는 어떤 것이 있는지, 각자 어떤 장단점을 가지는지를 대략 다뤄본다.
emptyDir 볼륨: 완전한 무상태성
Pod 볼륨 설정의 가장 가벼운 형태다.
Pod가 생성되는 즉시 해당 노드의 임시 디스크 저장소를 부여받고, 거기에 파일을 읽고 쓴다.
그리고 Pod가 삭제되는 즉시 디스크가 반환-삭제된다.
그러면 그냥 볼륨을 쓰지 않은 것과 뭐가 다를까?
가장 큰 차이점은, emptyDir 볼륨으로 만든 공간은 같은 Pod 내의 다른 컨테이너들이 공유를 할 수 있다는 것이다. 볼륨을 사용하지 않으면 디스크 계층은 격리되기 때문에 이러한 행위 구현이 불가능하다.
아무튼 볼륨 중에서는 가장 이상적이고 관리 리스크가 적은 방식이다.
상태를 관리하지 않아도 되는 일반적인 서버 등에 적합하다.
사용 방식은 간단하다. 볼륨 목록에 emptyDir 필드를 열고 sizeLimit 정도만 넣어주면 된다.
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi그럼 지정한 만큼만 임시 디스크가 할당된다.
hostPath 볼륨: 낮은 가용성, 노드 종속
그러면 Pod가 재시작되는 것과 관계없이 디스크 저장을 보존하고 싶다면 어떻게 해야할까?
가장 단순한 방법은 hostPath로 해당 노드의 호스트 파일 경로를 볼륨으로 추가하는 것이다. Docker에서 볼륨을 붙이는 것과 거의 같다.
apiVersion: v1
kind: Pod
metadata:
name: myapp
spec:
containers:
- name: app
image: nginx:stable
volumeMounts:
- name: host-data
mountPath: /var/myapp-data
volumes:
- name: host-data
hostPath:
path: /var/myapp-data
type: DirectoryOrCreate이러면 이제 호스트의 /var/myapp-data 경로를 컨테이너 내의 /var/myapp-data에서도 접근할 수 있다는 뜻이 된다.
가장 세팅도 간단하고 빠른 방법이지만, 무상태성을 그대로 갖다버리는 방식이기도 하다.
이러면 저 Pod는 특정 노드에만 실행되어야 하기 때문이다. 그러면 node selector를 지정해서 고정을 해줘야 하고, 자연히 해당 노드에 문제가 생겼을때 자연스런 failover가 불가능하다는 말이기도 하다.
hostPath의 보안상 추천되는 대안으로는 local volume(pv)이 있으나, 이것도 노드가 죽으면 날라간다는 단점은 동일하다. 고가용성을 달성할 수 없다.
그러면 고가용성을 어떻게 달성할 수 있을까?
디스크 수준 고가용성
일반적으로, 디스크는 고장으로 인한 손실 가능성이 높고, 장비의 수명 자체도 짧은 편에 속한다.
그래서 가용성이 필요한 사례에서는 단순히 단일 디스크의 볼륨을 마운트하는 것으로는 충분하지 않다.
디스크 수준 고가용성을 달성하는 가장 일반적이고 교과서적인 방법은 디스크 여러곳에 분산해서 쓰는 것이다.
파일 하나를 쓰더라도 3개 디스크에 나눠서 써둔다면, 손실될 가능성이 3배 이상으로 줄어드는 것이기 때문이다.
 그럼 한 곳에서 손실이 생기더라도 2곳에서 가져오면 된다.
그럼 한 곳에서 손실이 생기더라도 2곳에서 가져오면 된다.
대신 그만큼의 장비 비용이 더 들고, 쓰기 레이턴시가 증가하는 단점은 있다.
아무튼 3개 디스크에 쓰기가 전부 완료될때까지 대기해야하는 것이기 때문이다.
이건 쿠버네티스에 국한되는 것이 아니라, 대부분의 클라우드 서비스나 오픈소스 시스템들이 추구하는 방법론이다.
AWS EC2의 EBS만 하더라도 사실 단일 디스크에 쓰는 것이 아니라 여러 디스크에 쓰는 것이다. AWS RDS도 마찬가지로 여러 디스크에 분산 쓰기를 수행하는 것으로 높은 가용성을 보장한다.
이외에도 HDFS 같은 분산 파일시스템이나 Minio, ceph, rustFS 같은 오브젝트 스토리지 또한 이러한 방법론으로 고가용성을 달성한다.
Persistance Volume: 고가용성, 무상태성(optional)
Persistance Volume은 볼륨 관리를 위한 고급 기능이다.
다양한 환경/구성에서의 유연한 디스크 관리를 위해서 존재하는 인터페이스라고 보면 된다.
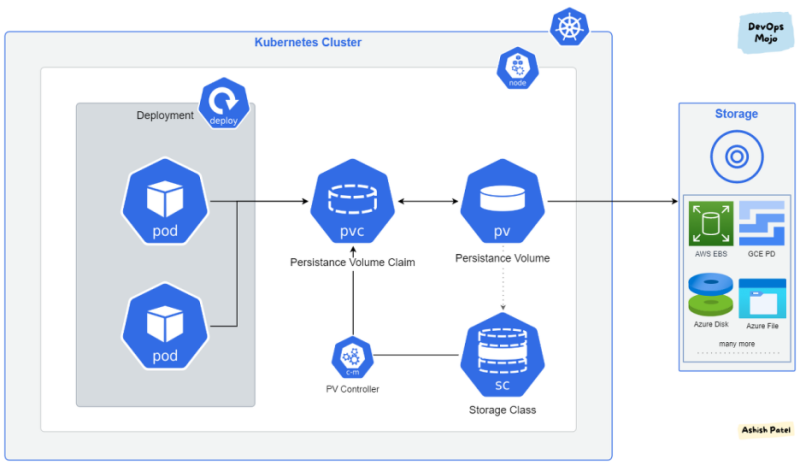 이건 Persistance Volume과 Persistance Volume Claim으로 구성된다.
이건 Persistance Volume과 Persistance Volume Claim으로 구성된다.
Persistance Volume으로 디스크 영역을 잡아놓고, Persistance Volume Claim으로 필요한 부분만 할당해서 컨테이너에 볼륨으로 붙이는 것이다.
Persistance Volume 자체는 디스크 관리 계층을 완전히 추상화해놓은 것이고 실제 선택지는 매우 다양하다.
PV를 쓴다고 해서 고가용성이 보장되는 것이 아니다. 그 뒷단에서 잘 쌓아두는 것이 더 중요하다.
AWS 같은 Public Cloud의 관리형 클러스터를 쓴다면, AWS EBS 같은 스토리지 서비스로 Persistance Volume을 사용할 수 있다. 더 정확히 말하면 Persistance Volume 계층은 클라우드에서 알아서 관리하고 있고, Persistance Volume Claim을 요청하면 알아서 리소스를 프로비저닝해서 붙여주는 것이다.
온프레미스라면 이야기가 조금 복잡해지기 시작한다. 보통 이러한 접근법이 된다.
-
파일 서버를 먼저 구성한다. (보통 고가용성이 가능한 선택지를 고름. ceph, minio 등)
-
k8s에서 파일서버를 Persistance Volume로서 사용할 수 있게 세팅한다.
-
Pod를 만들때 Persistance Volume Claim를 붙여서 사용한다.
-
그러면 Persistance Volume Claim이 PV(파일서버)로부터 디스크 영역을 할당해와서 컨테이너에 연결한다.
쿠버네티스에서 사용할 수 있는 파일 서버로는 NFS, Ceph, Minio(사망), RustFS 등이 있다.
이 중 NFS는 분산시스템이 아니라서 단일 장애 지점이 된다. 정말 가벼운 사용사례에만 적합하고, 일반적으로 권장되지 않는 선택지다.
Ceph, Minio, RustFS는 분산 오브젝트 스토리지이며, k8s와도 잘 결합되어서 흔히 잘 사용된다.
대규모 프로덕션에는 Ceph를 사용하고, 중소규모에는 minio를 쓰는 경향이 있었는데, minio가 최근에 심근경색으로 떠나버려서 약간 환경이 불투명해진 감은 있다.
PV와 PVC를 구성하고 사용하는 방법은 길어질 수 있으므로 별도 포스트에서 다룬다.
https://blog.naver.com/sssang97/223096927913
https://blog.naver.com/sssang97/223495801532
쿠버네티스와 데이터베이스
종종 들리는 말이 있다. "쿠버네티스에 데이터베이스를 올리는건 좋지 않다"는 이야기다.
정확히는 불가능하다는 뜻이 아니라, 운영 복잡도와 트러블슈팅 비용이 크다는 의미에 가깝다.
그래서 실무에서는 AWS RDS 같은 관리형 DB를 우선 검토하라는 식의 이야기로 이어지곤 한다.
"쿠버네티스에서는 DB를 제대로 운영할 수 없다"는 것은 아니다.
쿠버네티스에 DB를 배포하는 것 자체는 충분히 가능한 영역이며, 실제로 그렇게 굴리는 조직도 많다.
좀 과장하면 결국 DB도 디스크에 읽기/쓰기를 반복하는 단순한 파일서버에 불과하고, 쿠버에 올린다고 해서 막 엄청난 기술 장벽이 생기는 것은 아니기 때문이다.
여기서의 핵심 난점은 배포보다 운영에 있다.
DB는 단순 파일 저장을 넘어 트랜잭션 일관성, 백업/복구, 복제, 장애조치, 성능 튜닝까지 함께 관리해야 하기 때문이다. 기본적으로 관리포인트가 굉장히 많은 시스템이다.
반면 관리형 DB는 자동 백업, 패치/업데이트, 모니터링과 로그 통합, 장애 대응 기능을 제공해 운영 부담을 크게 줄여준다. 반대로 이를 직접 구축하면 높은 제어권을 얻는 대신 인력과 시간, 운영 리스크를 함께 감수해야 한다.
선택 기준은 명확하다. 충분한 운영 역량과 비용 대비 효과가 입증된다면 자체 운영도 좋은 선택이다. 그렇지 않다면 관리형 DB가 더 합리적이다.
기술의 우열보다는 비용 측면에서의 예비타당성 조사가 필요한 부분이다.