[k8s] HorizontalPodAutoscaler
HorizontalPodAutoscaler는 수평 자동 확장 - 오토스케일링을 위한 쿠버네티스의 기본 내장 도구다.
이걸 사용하면 실제 서버 부하에 맞춰서 Pod 개수를 동적으로 조정할 수 있다.
기본 원리
HorizontalPodAutoscaler는 Statefulset과 Deployment에 대해서만 사용할 수 있다.
HorizontalPodAutoscaler는 연결된 Deployment 서버들의 실제 메트릭 정보를 주기적으로 조절하면서 Deployment의 replica 개수를 조절한다.
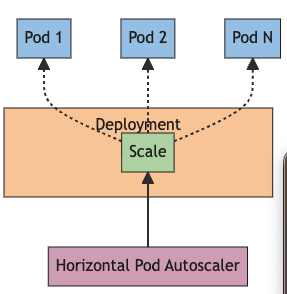
그리고 HorizontalPodAutoscaler는 쿠버네티스에 내장된 기본 메트릭 데이터를 참조한다.
kubectl get deployment metrics-server -n kube-system 바로 이 녀석이다.
바로 이 녀석이다.
이 친구가 제공하는 cpu/메모리 사용량 메트릭을 약 15초마다 조회하면서, 목표 사용량(Utilization)와 비교하고 비슷하게 될 수 있게끔 Pod를 더 늘리거나 줄이는 것이다.
여기서의 목표 사용량은 resources.requests.cpu, memory이 된다. 그래서 이걸 제대로 활용하려면 항상 requests을 붙여주는 것이 좋다.
기본적으로는 자체 메트릭만 사용하지만, 실패율, 요청 개수 같은 특수한 형태의 스케일 조건을 원한다면 prometheus로 커스텀 메트릭을 구성해서 붙이는 것도 가능하다.
사용해보기
적절한 Deployment 기반 서버를 하나 먼저 준비해보겠다.
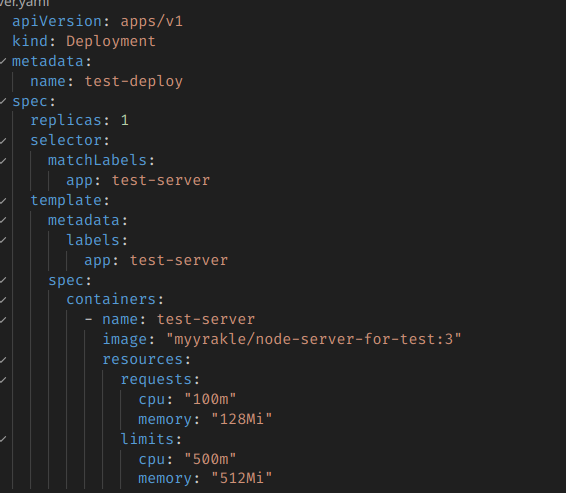 replica는 1이고, 단순한 API 서버다.
replica는 1이고, 단순한 API 서버다.
그럼 이제 HPA를 정의해보자.
사용법은 생각보다 간단하다. 다음 HPA는 CPU 사용량을 기준으로 스케일링을 트리거한다.
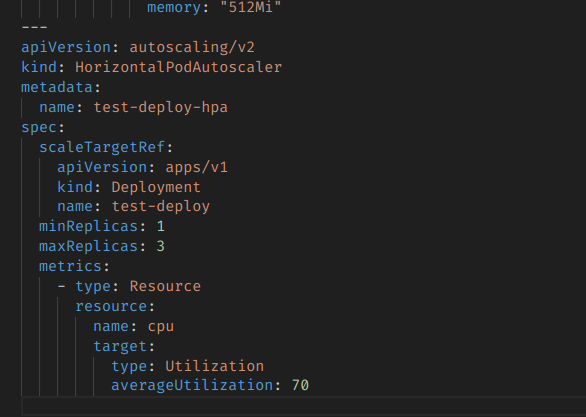 이건 CPU의 평균 사용량이 70% 미만이 될 수 있게 하는 스케일링 규칙이다.
이건 CPU의 평균 사용량이 70% 미만이 될 수 있게 하는 스케일링 규칙이다.
다시 말해서, 모든 Pod의 CPU 사용량 평균이 70%를 초과하면 replica를 늘리고, 이하로 내려가면 replica를 줄인다. 그리고 그 개수의 최소값은 1, 최대값은 3이다.
전체 코드다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deploy
spec:
replicas: 1
selector:
matchLabels:
app: test-server
template:
metadata:
labels:
app: test-server
spec:
containers:
- name: test-server
image: "myyrakle/node-server-for-test:3"
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: test-deploy-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: test-deploy
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70그렇기 만들어서 보면

 이렇게 hpa가 추가된 것을 볼 수 있다. 이것도 독립적인 리소스 단위다.
이렇게 hpa가 추가된 것을 볼 수 있다. 이것도 독립적인 리소스 단위다.
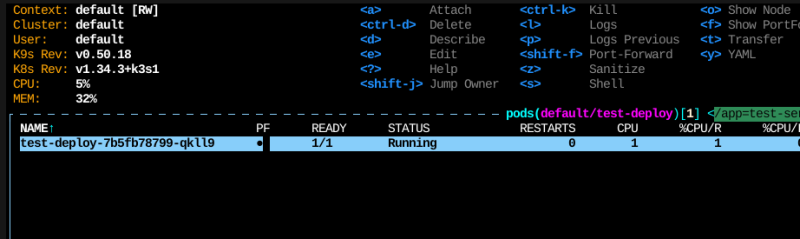 처음에는 pod가 하나일 것이다.
처음에는 pod가 하나일 것이다.
이제 pod에 들어가서 CPU 압력을 줘보자.
while :; do :; done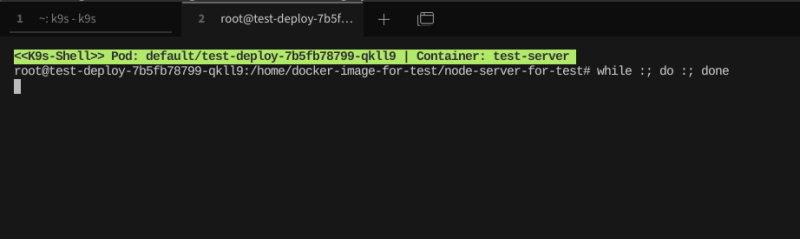
그러면 CPU 부하가 100% 이상으로 칠 것이고

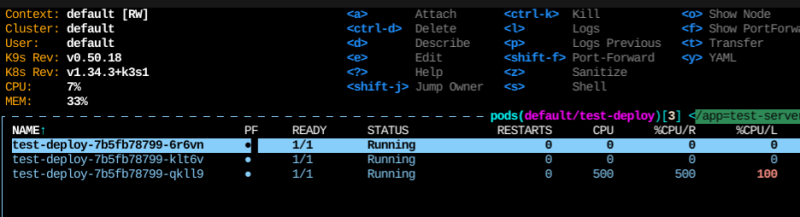 그에 맞춰서 스케일링을 트리거할 것이다.
그에 맞춰서 스케일링을 트리거할 것이다.
그리고 CPU 압박을 중단하면 다시 replica를 줄인다.

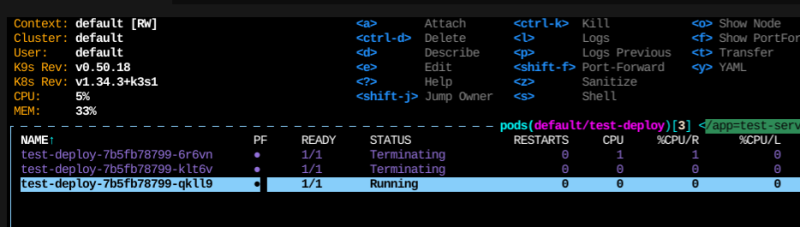 확장은 매우 빠르게 트리거하는 반면에, 축소는 훨씬 보수적으로 동작한다.
확장은 매우 빠르게 트리거하는 반면에, 축소는 훨씬 보수적으로 동작한다.
다시 순식간에 스파이크가 칠 수도 있으니, 최소 5분 정도의 유예기간을 더 두고 내린다.
스케일링 속도 조절
behavior를 정의하면 pod가 얼마나 늘어나고 줄어들게 할지 설정할 수 있다.
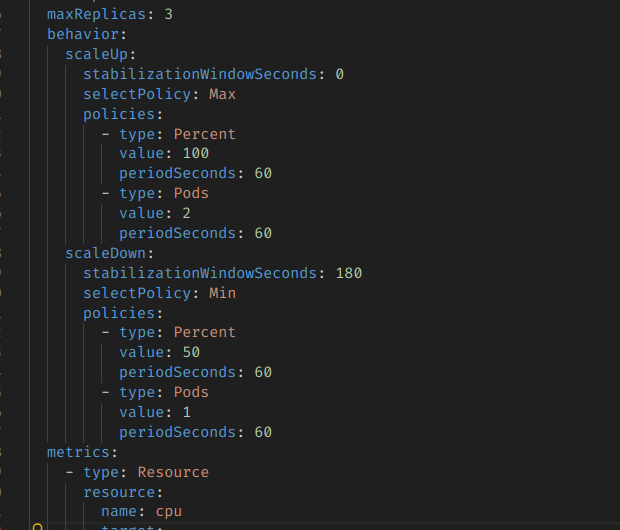 Percent와 Pod라는 policy가 있는데, 이건 각각 한번에 늘리거나 줄일 pod 개수를 정의한다.
Percent와 Pod라는 policy가 있는데, 이건 각각 한번에 늘리거나 줄일 pod 개수를 정의한다.
- percent의 value가 100라는 것은, 현재 pod 개수의 100% 만큼 증가시킨다는 뜻이다.
- pods의 value가 2이라는 것은 항상 2개씩 증가시킨다는 뜻이다.
그리고 selectPolicy:Max는, 2개 중에 더 큰 개수를 선택한다는 뜻이 된다.
scaleup의 기본값은 보통 15초 간격 / Percent:100, Pods:4 정도다.
stabilizationWindowSeconds는 확장/축소를 하기 전에 기다리는 유예시간이다.
0초면 지표에 맞춰서 즉시 대응하는 것이고, 좀 늘려놓으면 통계를 좀 쌓은 다음에 대응한다.
상기했듯이, 보통 확장은 빠르게 하고 축소에는 유예시간을 적절히 둔다. 필요에 따라 잘 넣으면 된다.
with ArgoCD (gitops)
만약 argocd 등의 형상관리 도구로 k8s 리소스를 관리한다면 HPA와 기능이 충돌할 위험이 매우 높다.
만약 HPA가 replica를 3개로 트리거했더라도, git 코드에 1개로 고정되어있다면 argocd가 다시 1개로 강제 동기화를 걸어버릴 것이기 때문이다.
이럴 때는 ArgoCD에서 replica 필드를 동기화 대상에서 제외하도록 특수한 예외처리를 해주는 것이 좋다.
ignoreDifferences를 다음과 같이 추가하면 모든 Deployment의 replica를 무시하도록 할 수 있다.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: myapp
namespace: argocd
spec:
project: default
...
ignoreDifferences:
- group: apps
kind: Deployment
jqPathExpressions:
- .spec.replicas # 무시참조
https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale/
https://oneuptime.com/blog/post/2026-02-26-argocd-deploy-horizontalpodautoscalers/view