[k8s] Pod: Probe를 통한 헬스체크 관리
Probe는 Pod의 정상 동작 여부를 확인하기 위한 검증 수단 중 하나다.
다른 말로는 헬스체크라고도 부르는 그것이다.
이게 없다면 서버의 실패를 완전하게 보증할 수 없고, failover도 할 수 없기 때문에 꽤나 중요하다.
웬만하면 달아주는 것이 좋다.
사용법
다음과 같이 container 스펙 단위로 설정이 된다.
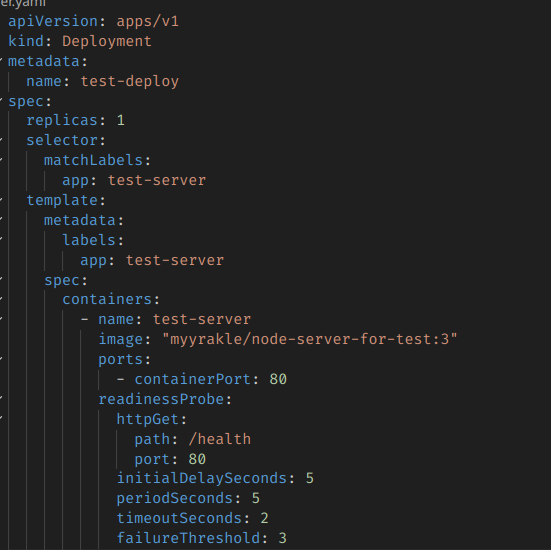 TCP와 HTTP CHECK가 둘 다 가능한데, 여기서는 HTTP 위주로 다룬다.
TCP와 HTTP CHECK가 둘 다 가능한데, 여기서는 HTTP 위주로 다룬다.
위 설정은 처음에는 5초동안 기다렸다가(initialDelaySeconds) 헬스체크를 시작하며, 5초마다 반복하고(periodSeconds), 2초 안에 응답이 없으면 실패로 치고(timeoutSeconds), 연속으로 3번 실패하면 NotReady로 처리한다는 것이다.(failureThreshold).
/health API를 헬스체크 API로 사용한다.
그리고 probe에는 3가지 종류가 있다.
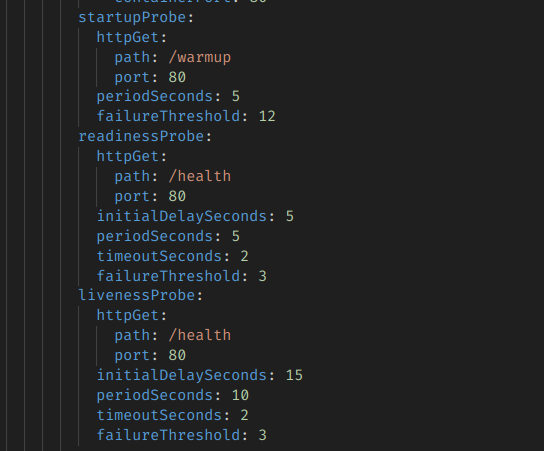 startupProbe는 서버를 본격적으로 시작해도 되는지를 검증하는 초기화 단계의 헬스체크다. 이게 통과하지 않으면 이후의 헬스체크를 시도하지 않고 재시도하다가 그것도 안되면 컨테이너를 재시작한다.
startupProbe는 서버를 본격적으로 시작해도 되는지를 검증하는 초기화 단계의 헬스체크다. 이게 통과하지 않으면 이후의 헬스체크를 시도하지 않고 재시도하다가 그것도 안되면 컨테이너를 재시작한다.
readinessProbe는 트래픽을 받아도 되는지를 검증하는 헬스체크다. 이게 실패하면 트래픽 라우팅이 중단된다. 재시작은 안한다.
livenessProbe는 초기화 이후 거의 상시로 돌아가는 헬스체크다. 이게 실패한다면 재시작을 시도한다.
기본 사용 패턴 (live & readiness)
그래서 보통 livenessProbe는 느슨하게 잡되, readinessProbe는 좀 빠듯하게 잡는게 일반적인 패턴이 된다.
상태가 좀 이상하면 트래픽 라우팅 대상에서 제외하고, 정말 이상하면 재시작하는 것이다.
warm-up 패턴
조금 변칙적인 사용 패턴이지만, 서버 시작에 시간이 소요되는 경우가 꽤 있다.
JVM 같은 이상한 언어를 쓰거나, AI 모델을 서빙하는 경우가 대표적이다.
JVM 같은 경우에는 Hotspot VM을 쓸때 데워주는 작업이 있어야 정상적인 성능을 내는 경우가 많다.
그럴 때는 warm-up용 API를 하나 뚫고 데워주는 작업을 해줘야 한다.
AI 모델 같은 경우에는 서버를 제대로 시작하는 것 자체가 상당히 큰 허들이다. 트리거한 뒤에 GPU에 다 올라가고 하는것까지 몇분을 넘게 걸리는 경우도 허다하다.
startupProbe를 쓰면 이러한 대기 패턴을 적절하게 구현할 수 있다.
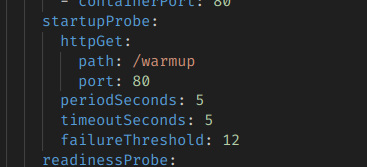 이 코드는 5초마다 warmup을 트리거하고, 그걸 최대 12번까지 시도한다.
이 코드는 5초마다 warmup을 트리거하고, 그걸 최대 12번까지 시도한다.
이 말인즉슨, 대략 60초 정도는 계속 재시도하며 warmup이 성공하기를 기다린다는 것이다.
그러면 warmup API에서는 warmup을 트리거하고, warmup이 완료되었을 때만 STATUS OK를 반환하도록 구현하면 된다.