동시성 구현 패턴
 동시성 프로그램의 일반적인 구현 형식과 특징, 이점 등을 간단히 정리해본다.
동시성 프로그램의 일반적인 구현 형식과 특징, 이점 등을 간단히 정리해본다.
예시로 든 언어는 Rust고, 용어는 내 마음대로 대강 붙인거다. 공신력 그런건 없다.
multi worker 구조
가장 일반적인 동시성 패턴이다. 그냥 메인 스레드에서 여러개의 워커 스레드를 병렬로 처리하는 방법이다.
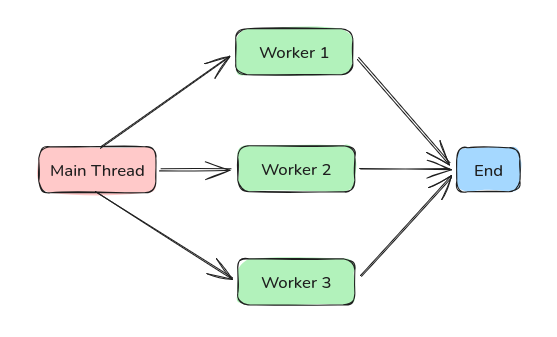 각 태스크 단위가 독립적이거나 동기화 지점이 작은 경우에 매우 효과적이다.
각 태스크 단위가 독립적이거나 동기화 지점이 작은 경우에 매우 효과적이다.
예를 들어, 하나의 작업을 10개의 스레드가 분할해서 작업한다면, 이런 식으로 워커 스레드를 잔뜩 띄우고 처리하도록 하는 것이다.
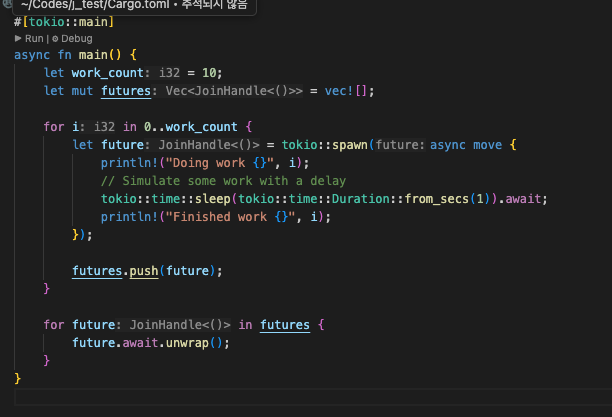
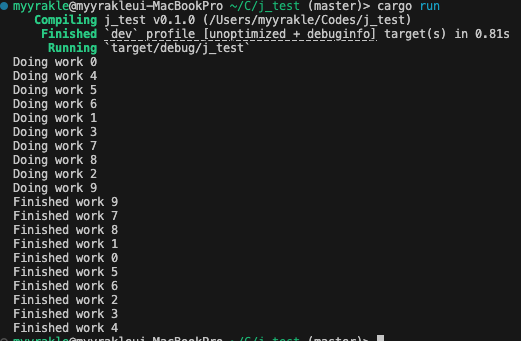 이러면 이론적으로는 워커 개수-10배에 근사하는 처리량을 얻을 수 있을 것이다.
이러면 이론적으로는 워커 개수-10배에 근사하는 처리량을 얻을 수 있을 것이다.
물론 CPU 집약적인 경우에는 실제 CPU 코어 개수에 제한을 받는다. 하지만 I/O 집약적인 경우라면 대체로 실제 워커 개수만큼 처리량 증폭 효과를 얻을 수 있다.
유의할 점은 역시 동기화 지점과 데드락 가능성이다.
보통은 동기화 지점이 아예 없는것보다는 있는 경우가 더 많을 텐데, 그럼 이런 식으로 각 스레드들이 중간중간 동기화 데이터에 접근하는 부분이 생기기 마련이다.
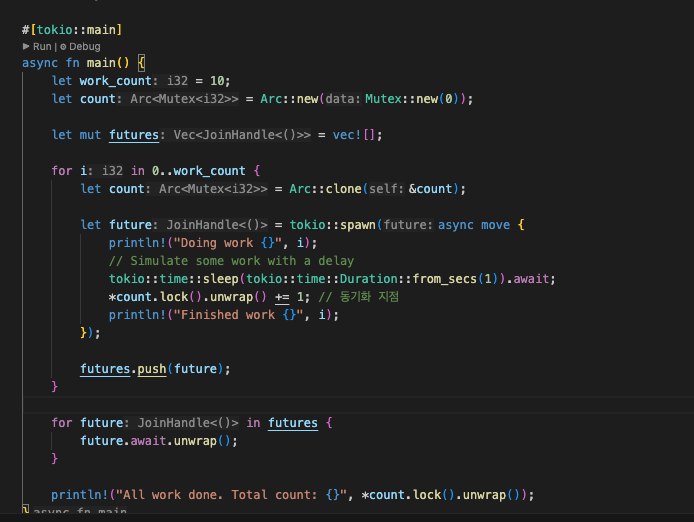 만약 Mutex를 걸고 오랫동안 크리티컬섹션을 점유한다면, 그만큼 유의미한 처리량이 반감될뿐더러 흐름 파악이 매우 복잡해진다.
만약 Mutex를 걸고 오랫동안 크리티컬섹션을 점유한다면, 그만큼 유의미한 처리량이 반감될뿐더러 흐름 파악이 매우 복잡해진다.
multi worker - 분할 정복
하지만, 까다로운 경우가 아니라면 동기화 지점을 완전히 제거하고 순진한 병렬화를 유도하는 방법도 있다.
예를 들어, 1000개짜리 배열 데이터가 있고 그걸 빠르게 가공해야 한다면, 각 워커 스레드가 100개씩 분배받아서 처리하는 식으로 할 수 있는 것이다. 그리고 모든 워커가 작업을 마치면, 그 워커별 작업 내역을 병합하면 된다.
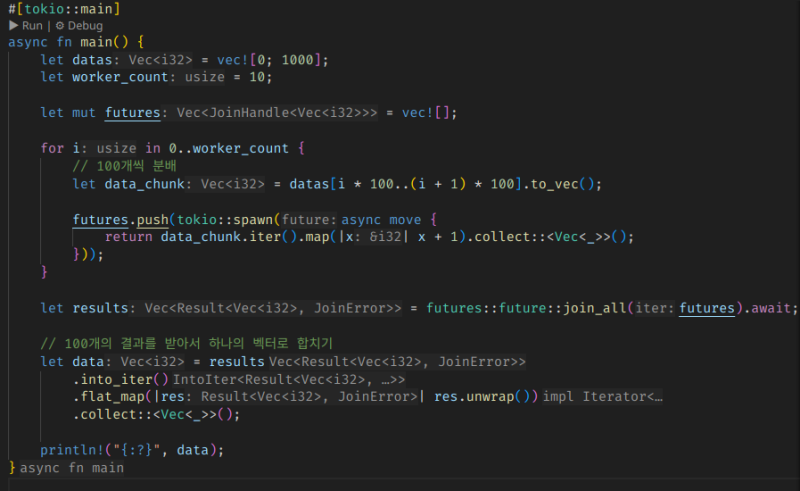 이런 식이 될 것이다.
이런 식이 될 것이다.
동기화 지점이 없으므로 데드락이나 Lock 점유 관련해서 신경쓸 부분도 없고, 실제로 최적화 수준에서도 괜찮은 결과를 낼 수 있다.
물론 이 방식을 항상 적용할 수 있는 것은 아니다. 조금이라도 워커들이 상호 의존성을 가지는 경우에는 적용할 수 없다. 그렇다면 단일 동기화 지점을 통해 공유를 해야할 것이다.
이런 식의 접근법을 fan-out/fan-in 패턴이라고도 부른다.
sender - receiver 패턴
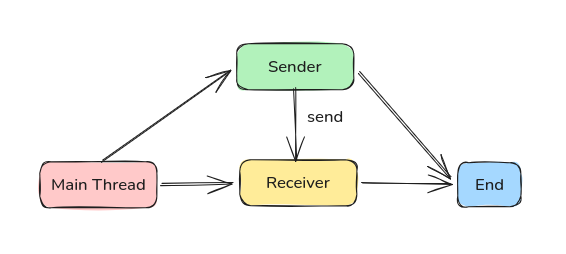
스레드 간에 단방향 의존성이 존재하는 경우에 적용하기 좋은 동시성 패턴이다.
선행 작업을 완료한 Sender Task가 그 결과를 Receiver Task에게 전달해주는 방식이다.
예를 들어, DB에서 어떤 값을 읽어온 뒤에 DB에 쓰는 마이그레이션 코드를 구현한다고 하면, 이런 식으로 작성할 수 있을 것이다.
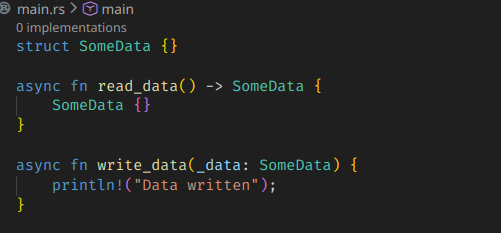
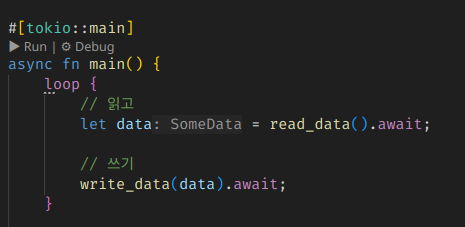 단순함으로 치면 사실 이런게 가장 좋다.
단순함으로 치면 사실 이런게 가장 좋다.
읽고, 다 읽으면 쓴다. 얼마나 간단한가?
하지만 처리량에는 분명히 한계가 있다.
쓰기를 완료하기 전에 읽기를 미리 시작할 수도 있을 것인데, 여기서는 고지식하게 다 기다린 다음에 그 다음 읽기를 시작한다. 유연한 대응이 어려운 것이다.
이런 경우에는 리시버 패턴을 사용하면 유연하게 처리량을 확장할 수 있다. 쉽게 말해서 코드 내에서 Client -> Server 구조를 만드는 것과 다름이 없다.
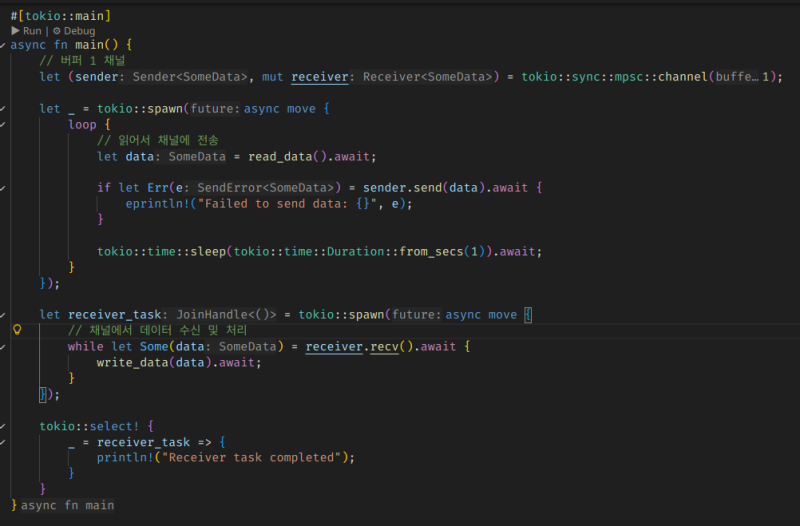 sender 스레드에서는 읽기를 처리해서 receiver에 보내고, receiver에서는 그걸 받아서 쓰기를 처리한다.
sender 스레드에서는 읽기를 처리해서 receiver에 보내고, receiver에서는 그걸 받아서 쓰기를 처리한다.
채널의 버퍼 크기를 통해서 처리량을 적절히 제약할 수 있다. 세마포어의 역할을 하는 것이다.
위 코드에서는 채널 버퍼를 1로 잡았는데, 이 말인즉슨 대기열에 동시에 머물 수 있는 메세지 개수가 1이란 셈이다.
그러니까 write를 처리하는 도중에 read 명령이 1개까진 쌓일 수 있지만, 그 이상을 적재하려면 sender가 send 시점에 대기한다. 이를 통해 사용량이 폭발하는 것을 적절히 방지할 수 있다.
게다가 이 방식은 채널을 통해서만 느슨하게 연결되기 때문에, 코드를 완전히 격리해서 관심사를 분리하기도 좋다. 모듈화 측면에서 용이한 부분이 있다.
pipeline 패턴
이건 sender-receiver 패턴의 조금 더 계층화된 버전이다.
각 동시성 스텝이 단방향으로 의존성을 가지는 A->B->C 구조인 경우에, 각 스텝을 독립적암 함수 단위로 정의하고 파이프라이닝하듯이 계속 넘기는 것이다.

여기서 스텝들을 연결하는 것도 보통 채널을 사용하는 편이다.
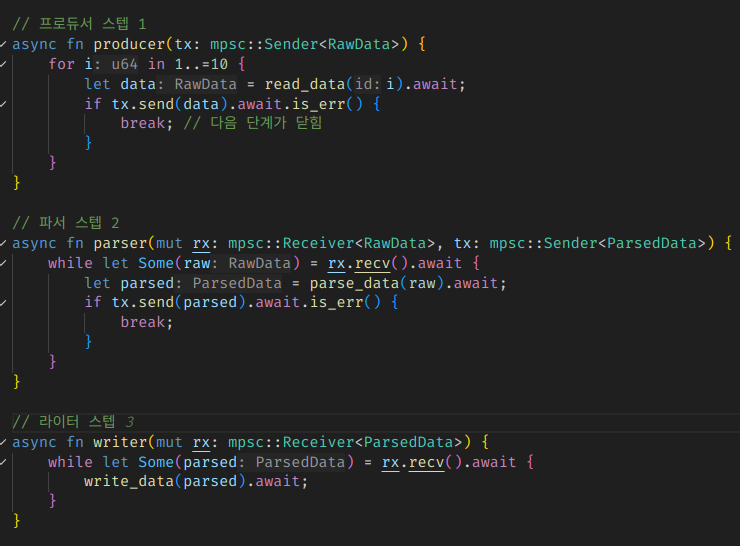 이런 식으로 채널을 통해 데이터를 주고받는 동시성 스텝 함수를 구현하고
이런 식으로 채널을 통해 데이터를 주고받는 동시성 스텝 함수를 구현하고
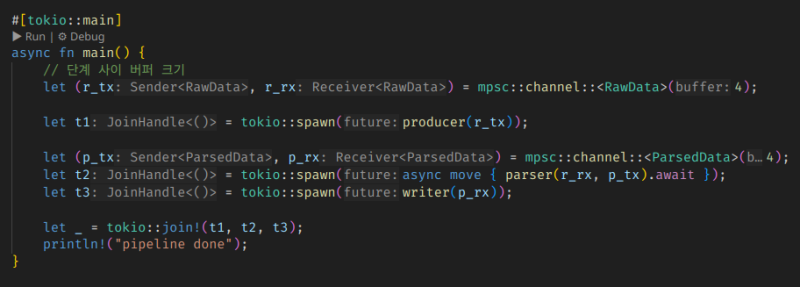 이런 식으로 채널을 정의해서 엮어주는 것이다.
이런 식으로 채널을 정의해서 엮어주는 것이다.
그러면 A를 처리한 값이 B로 넘어가고, B를 처리한 값이 C로 넘어가서 최종 처리가 완료되는 일련의 흐름이 돌아가게 된다.
그리고 이것도 채널의 버퍼를 통해서 스텝별 동시 허용량을 정의할 수 있다. 허용량을 넘어서면 그 이전 스텝에서 block이 걸릴 것이다.