[k8s] nvidia: time slicing을 통한 GPU 공유
nvidia 컨테이너 런타임을 통해 GPU 리소스를 쓴다면, 다음과 같이 resources.limit 절을 사용해서 gpu에 대한 사용량을 조절하는 것이 일반적이다.
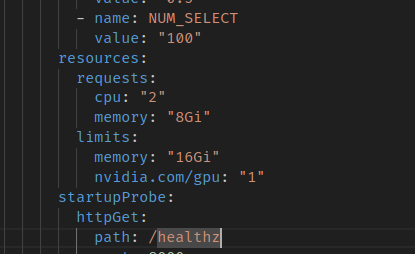 이러면 하나의 컨테이너마다 하나의 gpu를 할당해서 실행해준다. 매우 간단한 논리다.
이러면 하나의 컨테이너마다 하나의 gpu를 할당해서 실행해준다. 매우 간단한 논리다.
이 방식은 대체로는 잘 동작하지만, 변칙적인 리소스 관리에는 어려운 부분들이 있다.
GPU를 활용하다보면 비용상의 이유로 단일 GPU를 여러 컨테이너가 돌려쓰게 해야할 상황도 생기는데, 이게 좀 까다롭다. nvidia 컨테이너 관리자는 기본적으로 GPU 하나당 하나의 컨테이너를 배타적으로 띄우기 때문이다. 만약 잔여 GPU가 없다면 할당이 실패한다.
GPU를 공유하게 하는 방법이 없는건 아니고, 2-3가지 정도의 선택지가 있다.
여기서는 가장 세팅이 간단하고 모든 환경에서 널리 사용할 수 있는 time-slicing 기법을 간단히 소개한다.
원리
Time Slice의 원리는 대단한 것이 아니다. 그냥 다른 컨테이너들이 단일 GPU를 적당히 공유하며 돌려쓰게 하는 방법론이다. 더 정확히 말하면 물리 GPU 1개를 여러개의 논리 GPU로 표현하는 방식이다.
만약 replica를 2로 설정하면, 런타임은 GPU 1개를 2개인것처럼 인식하고 최대 2개까지 컨테이너를 올린다.
단순한 만큼 단점도 많다. 아무런 격리 수준이 없어서 OOM 등으로 터질 수도 있고, 분배에 대한 제어도 없어서 공평한 분배도 전혀 존재하지 않는다.
세팅이 간편하고 하드웨어 호환성이 좋다는 것이 최대 장점이다. MIG 같은 다른 좋은 GPU 공유 방식은 특정 초-고사양 하드웨어에서만 지원된다.
Time Slice Config 정의
전용 Config를 먼저 정의한다.
apiVersion: v1
kind: ConfigMap
metadata:
name: device-plugin-config
namespace: gpu-operator
data:
# 기본 노드에는 GPU 1개에 대해 1개의 Pod가 할당되도록 설정
default: |
version: v1
# 특정 노드에는 GPU 1개에 대해 2개의 Pod가 할당되도록 설정
time-slicing-2: |
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 2 이러면 이제 GPU를 2배로 뻥튀기하는 time-slicing-2 구성이 만들어지는 것이다.
이러면 이제 GPU를 2배로 뻥튀기하는 time-slicing-2 구성이 만들어지는 것이다.
그러고 나서는 cluster policy가 저 config를 참조하도록 해야한다.
 spec에 다음 절을 추가하면 되는데
spec에 다음 절을 추가하면 되는데
devicePlugin:
config:
name: device-plugin-config # 위에서 만든 ConfigMap 이름
default: default # 라벨 없는 노드의 기본 프로필가장 간단한건 그냥 cluster-policy를 직접 편집하는 것이다.
kubectl describe clusterpolicy cluster-policy
kubectl edit clusterpolicy cluster-policy
helm을 쓴다면 다음 명령을 통해 reload할 수 있다.
helm upgrade gpu-operator nvidia/gpu-operator \
-n gpu-operator \
--set devicePlugin.config.name=device-plugin-config \
--set devicePlugin.config.default=default \
--version v24.9.2 \
--reuse-values그래서 cluster policy spec이 잘 변경되면 된 것이다.
Time Slicing 적용
자. 그럼 이제 사용할 준비는 얼추 된 것이다.
GPU가 3개 달린 장비에 2배 뻥튀기를 적용해보자. 이 설정은 기본적으로 노드 단위에만 적용된다.
kubectl get node 노드명 -o jsonpath='{.status.capacity.nvidia\.com/gpu}' 기존에는 3개로만 나올 것이다.
기존에는 3개로만 나올 것이다.
저 노드에 아까 만든 구성에 대한 레이블을 달면
kubectl label node 노드명 nvidia.com/device-plugin.config=time-slicing-2
 즉시 논리 GPU가 2배로 늘어나는 기적이 일어난다.
즉시 논리 GPU가 2배로 늘어나는 기적이 일어난다.
이러면 저만큼 추가로 할당이 가능해지게 된다.
이 시점에서의 또 다른 단점은 세밀한 제어가 잘 안된다는 것이다.
특정 GPU에만 time-slicing을 적용할 수는 없고, 특정 노드에 속한 전체 GPU 리소스에 적용된다.
그리고 같은 그룹의 다른 pod들이 서로 다른 물리 GPU에 분산되게 하거나 하는 일반적인 효율화도 적용하기 어렵다. 운이 나쁘면 같은 deployment의 다른 pod들이 같은 물리 GPU에 들어가버릴 수도 있는 것이다.
참조
https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/gpu-sharing.html
https://docs.redhat.com/ko/documentation/red_hat_openshift_ai_self-managed/3.3/html/working_with_accelerators/about-gpu-time-slicing_accelerators
https://montkim.com/gpu-timeslicing