오픈모델 활용하기 (with ollama)
대 LLM의 시대. 이제는 LLM을 쓰지 않고 일을 하는 사람을 찾기가 어려워졌다.
이런저런 잡음이 많긴 하지만, OpenAI, Anthropic, Google 등의 대형 LLM 서비스 제공자들을 매우 훌륭한 모델을 합리적인 가격에 제공하고 있다.
그럼에도 불구하고, 이런 모델들을 쓰기 어려운 케이스들은 있을 수 있다.
대기업 모델을 쓸 때 걸림돌이 되는 부분은 이런 것들이다.
-
가격 (비용)
-
속도나 처리량
-
가용성
-
보안
-
전문화된 기능
1. 가격
가격은 상황에 따라 다를 수 있는데, 남는 GPU가 있거나 널널한 고성능 Mac 장비가 있다면 로컬에서 직접 띄우는게 효율적일 수 있다. 뭣보다 비용 압박에서 자유로워질 수 있다는게 장점이다.
2. 속도와 처리량
속도나 처리량은 경우에 따라 다를 수 있지만, 아무튼 로컬에서 병렬로 인프라를 구성할 수 있다면, 서비스를 쓰는 것보다 나은 처리량을 가질 수도 있다.
이건 벤치마크를 해보고, tradeoff를 보고 결정해야 하는 거라서 좀 예외적인 경우일 것이다.
3. 가용성
저놈들은 맨날 터진다. 업타임 99%을 지키지 못하는 경우도 있기 때문에, 서비스에 통합하기에 애로사항이 꽤 존재한다. 직접 인프라를 관리하고 유지할 역량이 있다면 셀프호스트로 구성해서 연결하는 것도 괜찮은 대안이 될 수 있다.
4. 보안
뭐가 되었든간에, LLM 서비스들은 모든 입력 프롬프트를 네트워크를 통해 전송한다.
자기들이 그걸 수집하지 않는다고 해도 그걸 다 믿을 수도 없는 일이고, 수집하지 않는다고 하더라도 네트워크를 통해 나가는 것 자체가 절대 보안에 좋은 것이 아니다.
그래서 뭔가 패스워드를 포함해서 민감한 값이나 코드를 건드릴 일이 있다면, 로컬 모델을 통해 작업을 처리하는게 보안적으로는 더 좋다.
5. 전문화된 기능
LLM 서비스들은 매우 방대한 영역에 대한 역량을 훌륭하게 제공하지만, 분야에 따라서는 능력이 미비한 부분이 있을 수 있다. 프롬프트나 웹서치 등을 통해서 결점을 보완할 수도 있지만, 아무래도 LLM 내부에서 처리하는 것에 비해서는 성능이나 속도, 비용 면에서 손해가 많이 생긴다.
이런 점에서는 LLM을 커스텀해서 쓰거나 특정 분야에 커스텀된 오픈 모델을 쓰는 것이 나을 수 있다.
요즘 이런 측면에 집중하는 개발사가 미스트랄인 것 같더라
오픈모델과 셀프호스트의 단점
여러개 개발사들이 오픈모델을 속속들이 공개를 하고는 있고, 오픈모델들의 평균 수준도 빠르게 발전하고 있지만, 당연히 대기업들의 메인 유료 모델들에 비하면 성능이 쳐지는 경우가 많다.
이건 본인이 실험을 해보고 사용사례에 맞는지를 검증해봐야 한다.
그리고 인프라 관리 역량이 충분치 않고, 가용성을 확보할 자신이 없다면 시스템에 통합하는 것은 당연히 재고할 필요가 있다.
LLM의 동작 원리: 그리고 애플의 부상
관련 포스트
https://blog.naver.com/sssang97/224155291489
LLM을 비롯한 AI 모델들은 GPU를 기반으로 무거운 병렬연산을 효율적으로 처리한다.
사실 GPU를 쓰지 않고 실행하는 것도 가능은 한데, 그러면 비상식적일 정도로 느려져서 사실상 쓰지 못한다.
그리고 여기서 중요한 것 중에 하나가 GPU의 메모리(VRAM)이다. GPU 연산의 구조상, 데이터를 VRAM에 올려둬야만 효율적으로 병렬연산을 할 수 있기 때문이다. 그래서 실제로 모델서버를 배포할 때도 VRAM의 크기가 매우 중요하다.
램 안에 다 안들어가는 모델은 사실상 올릴 수 없다고 보면 된다.
nvidia 고성능 GPU가 이미 있다면 괜찮은데, 사실 요즘 너무 비싸져서 비용적으로 좋다고 하긴 어렵다.
이런 상황에서 주목받는 것이 애플이다.
애플은 하드웨어 구조상 내장 GPU와 일반 메모리(RAM)이 연결되어있는데, 그래서 사실상 RAM을 VRAM처럼 활용할 수 있다! GPU 자체 성능도 괜찮고 메모리 크기도 옵션 넣으면 32G, 64G, 128G까지도 올릴 수 있으니, GPU를 따로 사는 것에 비해서 꽤 괜찮은 선택이 된다.
그래서 맥북 메모리가 널널하거나, 남는 고성능 맥미니가 있다면 16g, 32g 정도에 올라가는 경량 모델을 띄워서 써보는 것도 좋은 선택지다. 맥북 가격이 급상승한 요인이기도 하다.

모델 선택
일단 요즘 핫한 모델은 QWEN, Gemma, 미스트랄, Deepseek, kimi, glm 등이 있다.
범용성과 성능을 두루 잡은 것은 gemma가 가장 뛰어난 편이고, 개발용 에이전트로는 서로 투닥거리는 느낌이 있지만 QWEN, glm, kimi 등이 좀 치는 것 같다.
근데 시시각각 계속 바뀌니까 딱 뭐라고 말하기는 어렵겠다.
모델을 선택하는데 사용할 지표는 여러가지가 있다. 여기저기 파편화된 벤치마크도 보고 의견도 여기저기서 참조해보고 해야하지만... 여기서 그런것까지 다루진 않겠다.
모델들 정보를 훑어보기 좋은 것은 Ollama의 모델 라이브러리다.
https://ollama.com/search
gemma4의 경우로 예를 들어보겠다.
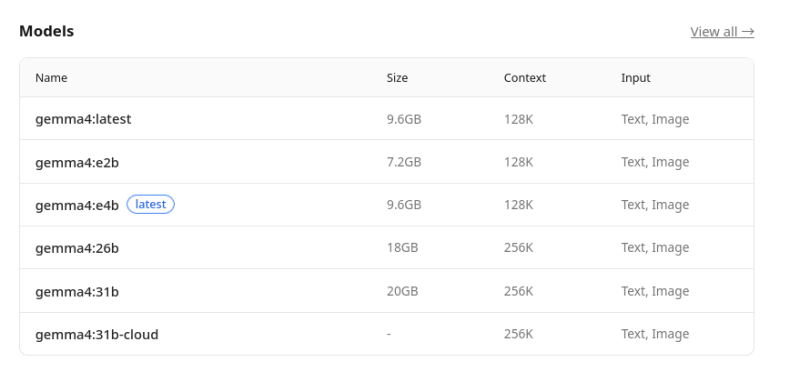 들어가보면 이런 식으로 모델 타입별로 간단한 리스트를 보여준다.
들어가보면 이런 식으로 모델 타입별로 간단한 리스트를 보여준다.
gemma4만 해도 파라미터 크기별로 다양한 타입이 존재한다. 당연히 파라미터가 클수록 메모리를 많이 먹고 느린 대신에 성능이 좋다.
Size가 VRAM을 얼마나 먹는지를 보여주는 것이고, Context는 실제로 컨텍스트를 어디까지 받는지다.
그리고 같은 파라미터의 모델이라도, 양자화 방식에 따라서 모델 크기와 성능에 차이가 생긴다.
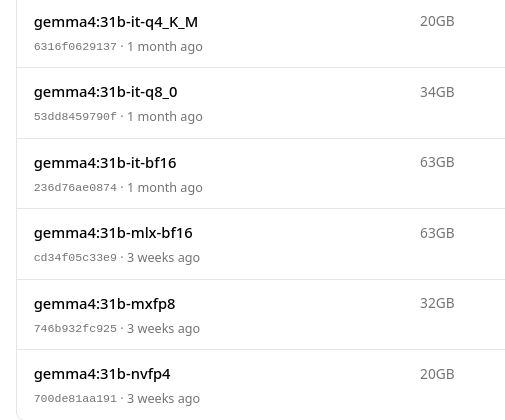 양자화를 더 빡세게 할수록 가볍고 빨라지긴 하는데, 그만큼의 정확도-성능 손실이 발생하므로 그 tradeoff를 인지하고는 있어야 한다.
양자화를 더 빡세게 할수록 가볍고 빨라지긴 하는데, 그만큼의 정확도-성능 손실이 발생하므로 그 tradeoff를 인지하고는 있어야 한다.
모델 서빙 도구
모델 파일을 직접 다운받아서 실행해도 되지만, 그러면 좀 번거롭고 불편한 지점이 많다.
그래서 보통 LLM을 띄운다고 하면 프레임워크들의 도움을 받는 편이다.
대표적인 서빙 도구로는 Ollama, vLLM, LM Studio, TGI 등이 있다.
가장 사용하기 편리한 도구는 Ollama다. 매우 간편하게 모델을 시작해서 굴려볼 수 있고, 모델을 여러가지 인터페이스에 맞춰서 실행할 수 있다. 개인 PC에 적당히 로컬모델 띄워서 쓰는 용도라면 이걸로도 충분하다.
LM Studio도 이와 비슷하지만 GUI로 괜찮은 사용성을 제공한다.
vLLM은 좀 더 최적화된 모델 배포를 도와주는 도구다. 세팅이 불편하지만, 튜닝이 좀 더 잘되는 편이다. 프로덕션급에서도 사용하기에 좋다.
여기서는 Ollama를 중점으로 다뤄본다.
Ollama로 시작해보기
여기선 Ollama를 사용해서 로컬 모델을 띄우고, 그걸 사용해보는 방법까지를 간략하게 다뤄본다.

 설치하고 실행만 해도 뭐 지가 알아서 자꾸 뭘 깔고 실행시켜주긴 한다.
설치하고 실행만 해도 뭐 지가 알아서 자꾸 뭘 깔고 실행시켜주긴 한다.
Claude Code 같은 기존 도구로도 통신할 수 있게 호환시켜주는데, 이런 혼잡스런건 일단 접어두고, CLI를 써서 직접 다뤄보자.
ollama pull을 사용하면 모델을 다운받을 수 있고, ollama run을 사용하면 모델을 즉시 실행할 수 있다. docker CLI와 거의 99% 비슷한 구조다.
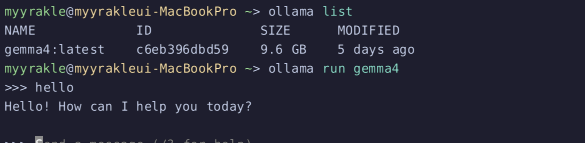 그러면 여기서 즉시 대화를 할 수도 있고, API를 통해 접근할 수도 있다.
그러면 여기서 즉시 대화를 할 수도 있고, API를 통해 접근할 수도 있다.
이 상태에서 대화를 나가도 서버는 계속 실행이 된다.
서버가 잘 떴다면 ps를 통해 상태를 모니터링할 수 있다.

 이건 현재 gemma 모델이 GPU 100% 모드로 아주 잘 떠있고, RAM을 12GB 먹고 있다는 말이다.
이건 현재 gemma 모델이 GPU 100% 모드로 아주 잘 떠있고, RAM을 12GB 먹고 있다는 말이다.
이 상태에서 API를 찔러보면 답이 나온다.
OLLAMA는 11434 포트로 열린다.
curl http://localhost:11434/api/generate -d '{
"model": "gemma4",
"prompt": "안 녕 . 한 문 장 으 로 자 기 소 개 해 줘 .",
"stream": false
}'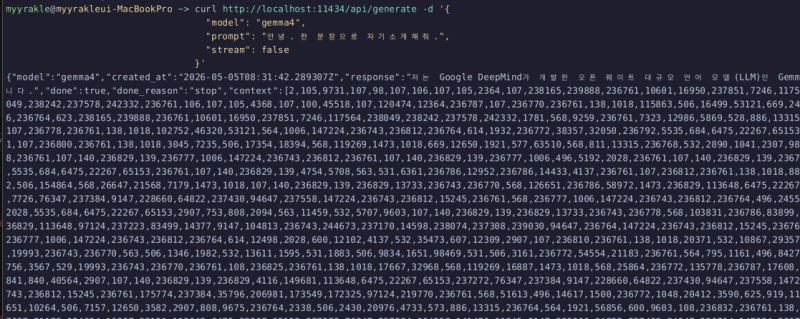 그럼 이렇게 던져준다.
그럼 이렇게 던져준다.
Codex 연결해보기
로컬 모델도 인터페이스만 잘 맞추면 Claude Code나 Codex 같은 에이전트 툴에 붙여서 쓸 수도 있다.
특히 codex는 외부 API 호환성이 좋은 편에 속한다.
사용법은 쉽다. 설정파일 수정해서
mkdir -p ~/.codex
vim ~/.codex/config.tomlmodel = "gemma4"
model_provider = "my_ollama"
[model_providers.my_ollama]
name = "Ollama"
base_url = "http://localhost:11434/v1"이런 식으로 정보를 적당히 넣어주면 된다.
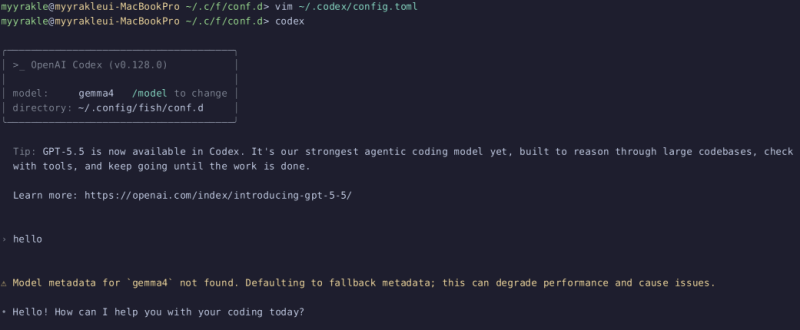 그러면 모르는 모델이라고 경고 뜰 수도 있긴 한데, 동작은 잘 한다.
그러면 모르는 모델이라고 경고 뜰 수도 있긴 한데, 동작은 잘 한다.
저 경고는 저 모델의 컨텍스트 크기 같은 제약사항을 모른다는 뜻이다.
Claude Code 연결해보기
Claude Code도 API 인터페이스만 맞추면 외부 API를 붙일 수 있는데, Ollama가 이걸 알아서 좀 잘 맞춰준다.
다음과 같이 환경변수를 설정하고
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_API_KEY=""
export ANTHROPIC_BASE_URL=http://localhost:11434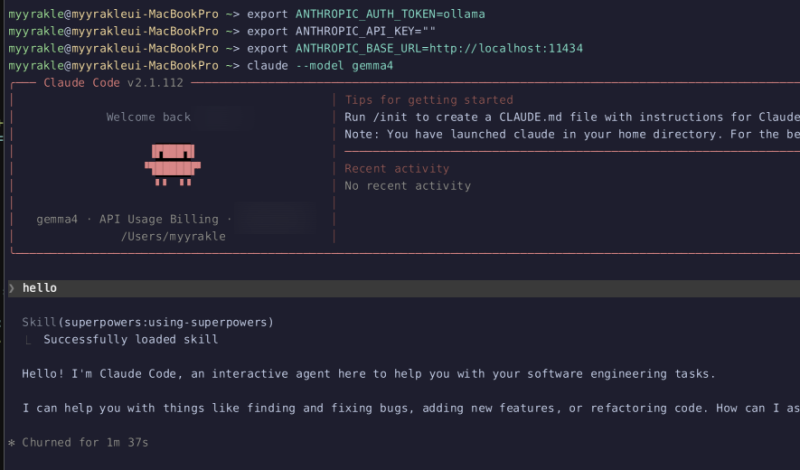 그냥 바로 실행하면 붙는다. 이런 느낌으로 쓰면 된다. 어렵진 않다.
그냥 바로 실행하면 붙는다. 이런 느낌으로 쓰면 된다. 어렵진 않다.
Ollama에 대한 고급 옵션이나 상세한 활용 등은 별도 포스트에서 다루겠다.