[PostgreSQL] 디스크 사용량 최적화
PostgreSQL에서 디스크 사용량을 분석하고 최적화하는 방법들을 정리해본다.
PostgreSQL이 꽤 뛰어나고 다재다능하긴 하지만, 디스크 사용량이 아주 효율적인 편은 아니다. 한계가 어느 정도 있는 점도 감안해야 한다.
사용량 분석
일단 위에서부터 탑다운으로 사용 구간을 분석해보는 것이 좋다.
다음 쿼리는 전체 디스크 용량을 조회한다.
SELECT
pg_size_pretty(pg_database_size(current_database())) AS total_db_size;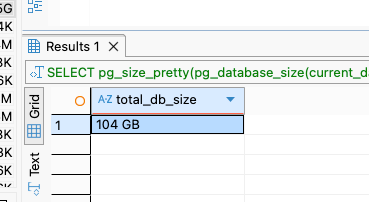
그리고 다음 쿼리는 테이블 단위로 구간별 디스크 사용량을 분석한다.
SELECT
schemaname,
relname,
pg_size_pretty(pg_total_relation_size(relid)) AS total,
pg_size_pretty(pg_relation_size(relid)) AS table_size,
pg_size_pretty(pg_indexes_size(relid)) AS index_size,
pg_size_pretty(pg_total_relation_size(relid)
- pg_relation_size(relid)
- pg_indexes_size(relid)) AS toast_size
FROM pg_catalog.pg_statio_user_tables
ORDER BY pg_total_relation_size(relid) DESC
LIMIT 30;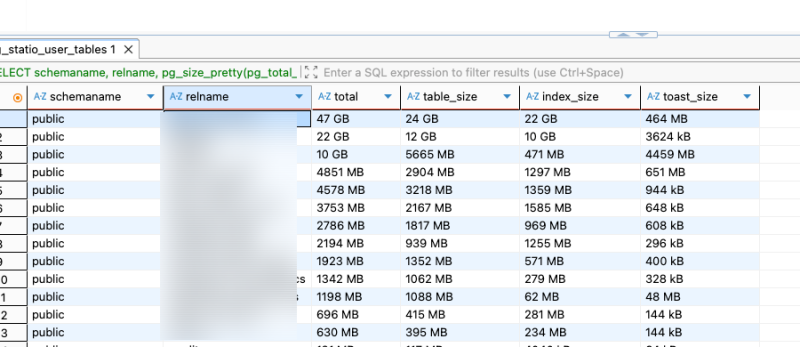 여기서 주목할만한 부분은 인덱스와 TOAST 크기다.
여기서 주목할만한 부분은 인덱스와 TOAST 크기다.
인덱스는 말 그대로 인덱스 데이터가 차지하는 공간을 말하고, TOAST는 text 같은 거대한 값이 별도로 저장되는 영역을 말한다. 둘 다 지나치게 크다면 사용패턴이 문제가 좀 있다고 판단하고 조사해보는 것이 좋다.
데이터 줄이기
당연히 가장 명확한 것은, 불필요한 컬럼이나 데이터를 정리하는 것이다.
쓸데없이 저장하고 있는게 없는지, TTL 기준을 두고 날려도 되는 데이터가 없는지 한번쯤은 검토해보는 것이 좋다.
인덱스 사이즈 최적화
인덱스도 무작정 이리저리 건다고 좋은게 아니라, 필요한 만큼만 잘 거는 것이 중요하다.
**미사용 인덱스 날리기 **
가장 먼저 할 것은 미사용 인덱스를 식별하고 제거하는 것이다.
다음 쿼리를 사용하면 특정 테이블의 인덱스들이 얼마나 쓰였는지를 확인할 수 있다.
SELECT
schemaname,
relname AS table_name,
indexrelname AS index_name,
idx_scan AS scan_count,
idx_tup_read AS tuples_read,
idx_tup_fetch AS tuples_fetched,
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size
FROM
pg_stat_user_indexes
where 1=1
and relname = '테이블명'
ORDER BY
idx_scan ASC, pg_relation_size(indexrelid) DESC;참조
https://blog.naver.com/sssang97/223822189632
**의미가 중복되는 인덱스 날리기 **
인덱스를 무지성으로 추가하다보면 선두 컬럼이 중복되는 인덱스가 공존할 수 있다.
그러니까, (A), (A, B), (A, B, C) 조합의 인덱스가 동시에 존재한다면, 이건 썩 좋진 못한 인덱싱 전략이다. 사실 (A, B, C) 인덱스 하나만 있어도 (A), (A, B) 인덱스의 역할을 다 할 수 있기 때문이다.
**Partial Index 활용하기 **
partial index는 특정 조건에 맞는 값만 인덱스를 구성하게 해주는 강력한 기능이다.
인덱스 조건 중에 매우 결정적인 부분이 있다면, 인덱스 컬럼으로 두기보다는 where 절로 배제하는 것이 더 좋다.
Create Index 인덱스명 on 테이블명(컬럼...) where 조건식https://blog.naver.com/sssang97/223498028986
컬럼 빼기
혹은, 인덱스의 구성이 지나치게 비대한 경우에도 최적화를 고려해볼 수 있다.
인덱스는 설정된 컬럼이 너무 많거나, 포함된 컬럼 중에 값이 매우 큰 것이 있다면 그에 비례해서 디스크 사용량이 폭증할 수 있다.
인덱스 스캔 패턴을 고려해서 컬럼을 좀 빼는 것을 고려해봐야 한다. 실사용 쿼리에서 해당 컬럼으로 인해 걸러지는 값이 적다면, 사실 그 컬럼은 인덱스에 걸지 않아도 되는 것이다.
TOAST 사이즈 최적화?
TOAST는 text/json 같은 큰 타입값에 대해서 만들어지는 별도 디스크 영역을 말한다.
만약 TOAST가 차지하는 용량이 비대하다면, 압축 알고리즘을 바꿔서 절약을 시도해볼 수 있다.
버전마다 다른데, 최신 버전에서는 lz4를 사용한다.
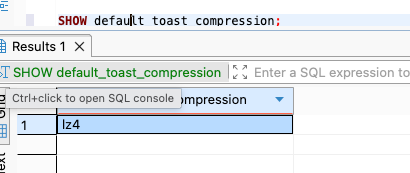
lz4는 균형잡힌 압축 알고리즘이다. CPU 사용량이 적으면서 압축률도 괜찮은 편이다.
레거시 알고리즘으로는 pglz라는 것이 있는데, CPU 사용량이 많은 대신 압축률은 근소하게 좋을 수도 있다. (확실하진 않음)
ALTER TABLE 테이블명 SET COMPRESSION 알고리즘;그래서 압축 알고리즘을 대체해보는 것도 하나의 시도가 될 수 있다.
근데 사실, 이 부분이 PostgreSQL의 큰 한계점이다. TOAST 자체가 딱히 높은 압축성으로 고려해서 만들어진 것도 아니고, 압축 알고리즘도 선택지를 그닥 주지 않는다. 어떻게 해도 최대 압축률은 25~50% 정도다.
저장 효율성을 높이면서 PostgreSQL도 쓰고 싶다면, TimescaleDB 같은 변종을 쓰는 것이 나을 수 있다. 이런건 컬럼 기반의 높은 압축 기능을 제공한다.
Dead tuple과 vacuum
알다시피, PostgreSQL은 MVCC에 기반한 버저닝 시스템을 사용하기 때문에, 수정이나 삭제를 하더라도 옛날 값이 한동안은 디스크에 잔존한다.
그렇게 만들어진 쓰레기를 dead tuple이라고 하고, 쓰레기를 정리하는 것을 vacuum이라고 부르는데, 이 vacuum 때문에도 디스크 낭비가 발생할 수 있다.
다음은 테이블별 dead tuple 비율을 보여주는 간단한 쿼리다.
SELECT
schemaname,
relname,
n_live_tup,
n_dead_tup,
round(
n_dead_tup::numeric
/ NULLIF(n_live_tup, 0),
2
) AS dead_ratio
FROM pg_stat_user_tables
ORDER BY n_dead_tup DESC
LIMIT 30;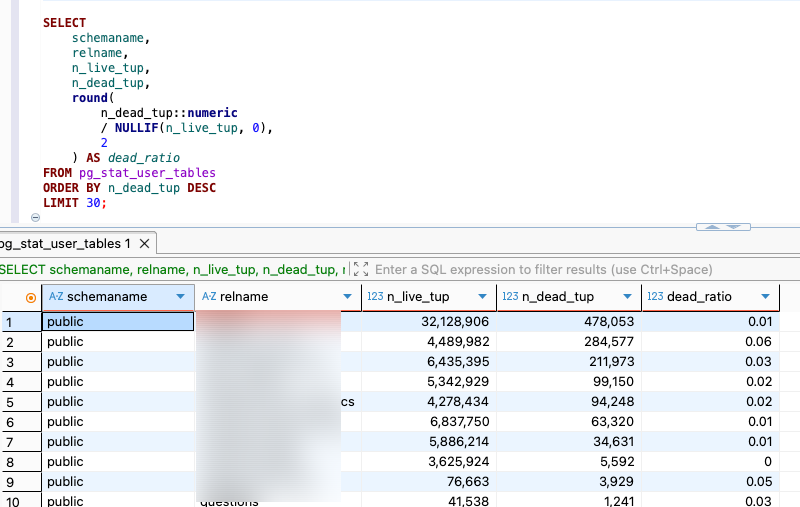 dead ratio가 이렇게 높지 않다면 괜찮은 것이다. 보통 0.05 미만으로 유지되면 건강한 것이다.
dead ratio가 이렇게 높지 않다면 괜찮은 것이다. 보통 0.05 미만으로 유지되면 건강한 것이다.
만약 저게 높게 잡힌다면 조사를 추가로 해볼 필요가 있다.
vacuum 관련 옵션은 다음 쿼리로 확인할 수 있다.
SELECT
name,
setting,
unit,
source
FROM pg_settings
WHERE name IN (
'autovacuum',
'autovacuum_vacuum_threshold',
'autovacuum_vacuum_scale_factor',
'autovacuum_vacuum_insert_threshold',
'autovacuum_vacuum_insert_scale_factor',
'autovacuum_analyze_threshold',
'autovacuum_analyze_scale_factor',
'autovacuum_max_workers',
'autovacuum_vacuum_cost_limit',
'autovacuum_vacuum_cost_delay',
'vacuum_cost_limit',
'vacuum_cost_delay'
)
ORDER BY name;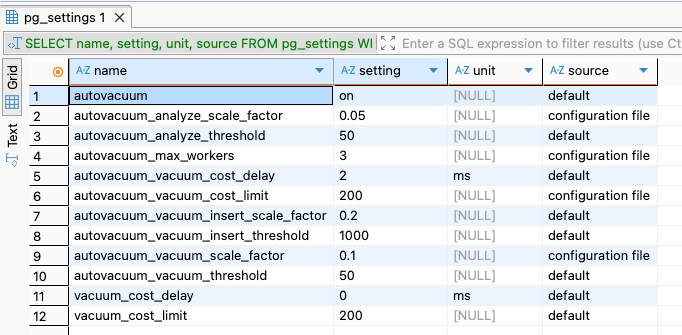 autovacuum_analyze_scale_factor라는 값이 0.05면 쓰레기의 비율이 5%가 넘으면 vacuum을 날린다는 의미가 된다.
autovacuum_analyze_scale_factor라는 값이 0.05면 쓰레기의 비율이 5%가 넘으면 vacuum을 날린다는 의미가 된다.
BLOAT
PostgreSQL은 dead tuple 외에도 공간의 낭비가 발생할 수 있는 구간이 존재한다.
pgstattuple라는 확장을 쓰면 관련 통계 데이터를 쉽게 분석할 수 있다.
먼저 활성화부터 한다.
CREATE EXTENSION IF NOT EXISTS pgstattuple;그리고 다음과 같이 쿼리를 날리면, 데이터를 보고 분석을 해준다. 참고로, 풀스캔하는거라서 좀 느리다.
SELECT *
FROM pgstattuple('테이블명'); 여기서 주요하게 볼만한 것은 dead_tuple_percent와 free_percent다.
여기서 주요하게 볼만한 것은 dead_tuple_percent와 free_percent다.
이 경우에는 free_percent가 2% 정도니까, 빈 공간이 거의 없다는 것이다. BLOAT 문제는 거의 없다.
만약 BLOAT이 있다면 BLOAT을 없애는 가장 확실하고 간단한 방법은, vacuum full을 날리는 것이다. 그러면 알아서 다 짜맞춰서 컴팩트하게 재배치를 해준다.
이 방법의 가장 큰 문제는 돌리는 동안 모든 것이 강제로 멈추고 중단된다는 것이다...
참조
https://www.postgresql.org/docs/current/storage-toast.html
https://blog.naver.com/sssang97/223822189632
https://blog.naver.com/sssang97/223498028986
https://www.tigerdata.com/blog/what-is-toast-and-why-it-isnt-enough-for-data-compression-in-postgres