[Rust] Rust로 cuda PTX 말아보기 (nvptx64-nvidia-cuda)
Rust가 얼마 전부터 nvptx64-nvidia-cuda 타겟을 공식적으로 지원하기 시작했다.
nvidia 환경에서 cuda 호출을 위한 PTX(중간 언어)를 생성하기 위한 용도의 타겟이다.
WASM 타겟이 wasm 바이너리를 빌드하고, 떠넘기는 것처럼, 이것도 PTX라는 nvidia 전용 중간 포맷만 빌드하는 것까지만 책임진다.
현재는 실험적 단계라서 2티어 지원이며, nightly에서만 사용 가능하다.
PTX 빌드용 툴체인 설치
먼저 PTX를 말기 위한 툴체인을 몇개 깔아준다.
rustup toolchain add nightly
rustup component add rust-src --toolchain nightly
rustup component add llvm-tools --toolchain nightly
rustup component add llvm-bitcode-linker --toolchain nightly 오류 없이 잘 깔리면 됐다.
오류 없이 잘 깔리면 됐다.
PTX 빌드하기
그럼 이벤에는 PTX를 하나 만들어보자.
cargo new --lib just_test
cd just_test프로젝트 따로 만들고
vim Cargo.toml
[lib]
crate-type = ["cdylib"]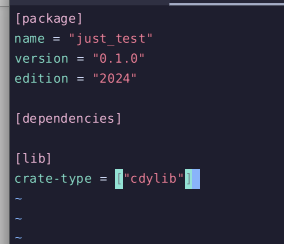 동적 라이브러리 설정을 활성화한다.
동적 라이브러리 설정을 활성화한다.
그리고 다음과 같이 cuda 제어 함수를 작성하면 된다.
#![no_std]
#![feature(abi_ptx)]
#![feature(stdarch_nvptx)]
use core::arch::nvptx::*;
#[unsafe(no_mangle)]
pub unsafe extern "ptx-kernel" fn add_kernel(
a: *const f32,
b: *const f32,
c: *mut f32,
n: usize,
) {
let idx = _block_idx_x() as usize * _block_dim_x() as usize
+ _thread_idx_x() as usize;
if idx < n {
unsafe {
*c.add(idx) = *a.add(idx) + *b.add(idx);
}
}
}
#[panic_handler]
fn panic(_: &core::panic::PanicInfo) -> ! {
loop {}
}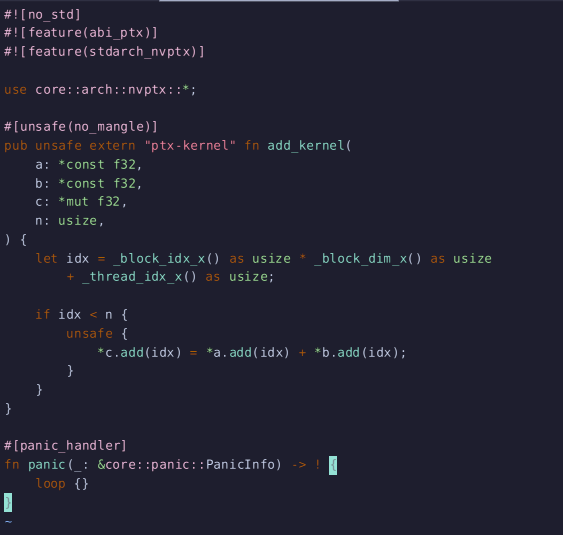 실수의 배열을 GPU를 써서 더하는 간단한 코드다.
실수의 배열을 GPU를 써서 더하는 간단한 코드다.
이렇게 짜면 실제로 GPU 코어를 사용해서 병렬 연산을 돌리게 된다.
그리고 cuda 타겟을 사용해서 빌드한다.
(-Ctarget-cpu는 최적화용 선택 옵션)
RUSTFLAGS="-Ctarget-cpu=sm_75" \
cargo +nightly rustc \
--target nvptx64-nvidia-cuda \
-Zbuild-std=core \
--release \
--crate-type=cdylib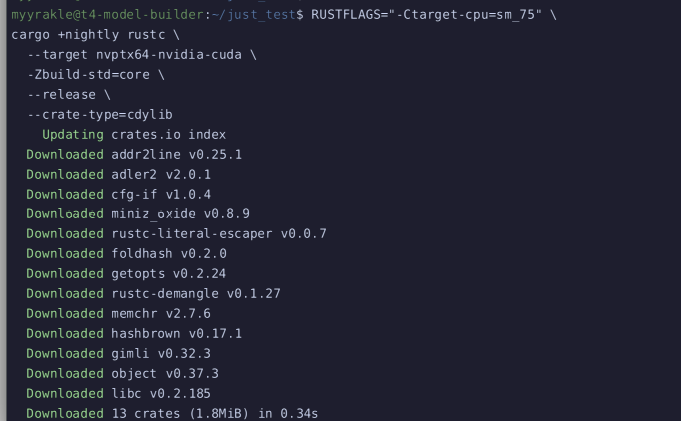
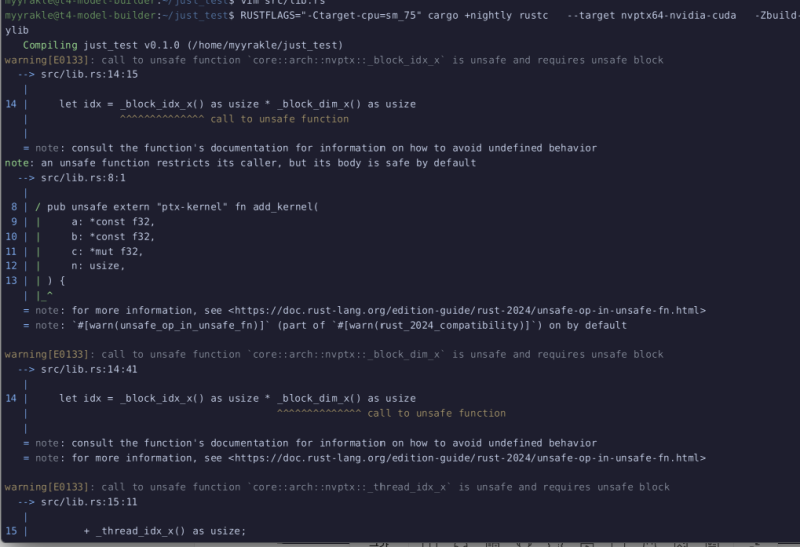
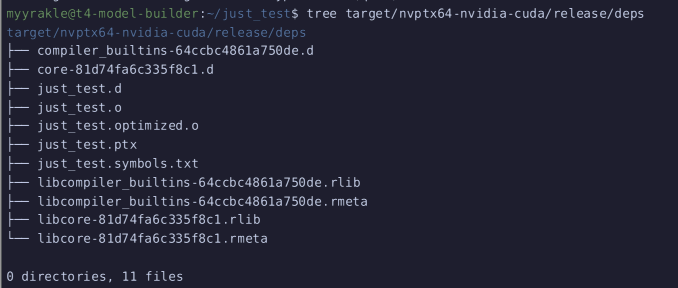 그럼 ptx라는 결과물이 떨어질 것이다.
그럼 ptx라는 결과물이 떨어질 것이다.
이건 언어나 GPU 모델 관계없이 실행할 수 있는 중립적인 중간 표현이다. Rust와 별개로 다 사용할 수 있는 엔비디아 표준 규격인 셈이다.
PTX 실행하기 (cust)
Rust에서 방금 만든 ptx를 실행해보자.
이건 cuda target과는 관련이 없고, cust라는 cuda용 crate을 통해서 돌려볼 수 있다.
cargo new cuda_host
cd cuda_host
cargo add cust 종속성 추가하고
종속성 추가하고
use cust::prelude::*;
use cust::error::CudaResult;
const PTX: &str = include_str!("../test.ptx");
fn main() -> CudaResult<()> {
let _ctx = cust::quick_init()?;
let module = Module::from_ptx(PTX, &[])?;
let stream = Stream::new(StreamFlags::NON_BLOCKING, None)?;
let a = vec![1.0f32, 2.0, 3.0, 4.0];
let b = vec![10.0f32, 20.0, 30.0, 40.0];
let mut c = vec![0.0f32; a.len()];
let d_a = DeviceBuffer::from_slice(&a)?;
let d_b = DeviceBuffer::from_slice(&b)?;
let d_c = DeviceBuffer::from_slice(&c)?;
let func = module.get_function("add_kernel")?;
let n = a.len();
let block_size = 256u32;
let grid_size = ((n as u32) + block_size - 1) / block_size;
unsafe {
launch!(
func<<<grid_size, block_size, 0, stream>>>(
d_a.as_device_ptr(),
d_b.as_device_ptr(),
d_c.as_device_ptr(),
n
)
)?;
}
stream.synchronize()?;
d_c.copy_to(&mut c)?;
println!("{:?}", c);
Ok(())
}방금 만든 PTX를 로드해서 실수 배열을 넘기는 간단한 코드다.
이걸 실행하는 시점에서는 당연히 nvidia GPU과 있어야한다.
그리고 돌려보면
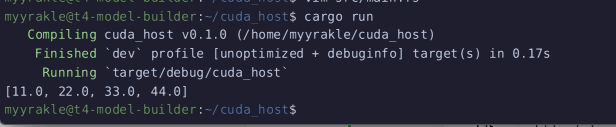 잘 돌아갈 것이다.
잘 돌아갈 것이다.
참조
https://rust-gpu.github.io/rust-cuda/
https://doc.rust-lang.org/beta/rustc/platform-support/nvptx64-nvidia-cuda.html
https://developer.nvidia.com/blog/understanding-ptx-the-assembly-language-of-cuda-gpu-computing/
https://docs.rs/cust/latest/cust/