[ML] 모델 성능 깎기
모델의 성능 - 특히 처리 속도와 크기를 최적화하는 방법을 정리해본다.
Cuda, Pytorch 환경을 중심으로 다룬다. 하지만 다른 플랫폼이라도 방향성 자체는 크게 다르진 않을 것이다.
샘플로 사용한 것은 텍스트 기반의 모델인 DeBERTa v3 ABSA (yangheng/deberta-v3-base-absa-v1.1)이고, 하드웨어는 국밥급 장비인 nvidia T4다.
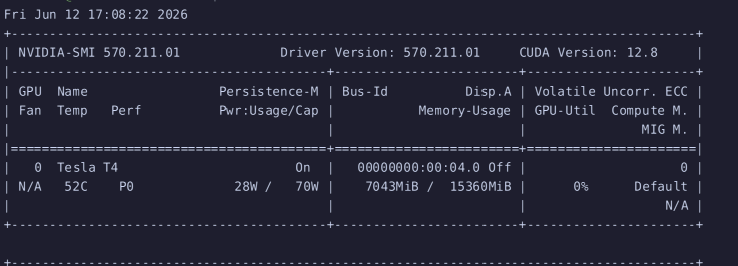 그냥 pytorch로 무지성으로 올리면 VRAM은 7GB쯤 먹고
그냥 pytorch로 무지성으로 올리면 VRAM은 7GB쯤 먹고
 그냥 메모리는 2GB쯤 먹는다.
그냥 메모리는 2GB쯤 먹는다.
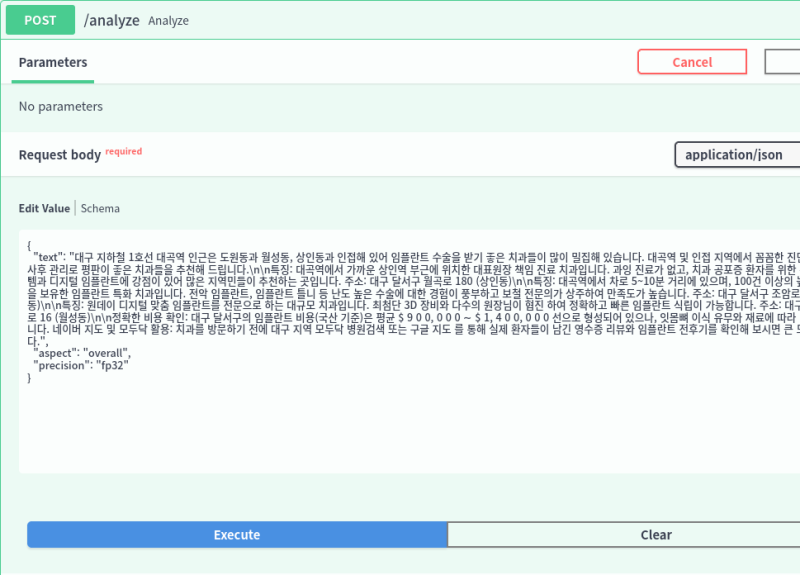
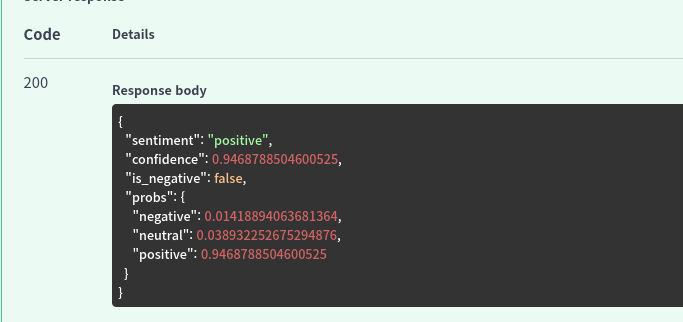 기본적으로 요청 날리면 긍정/부정 판별만 해주는 간단한 모델이다.
기본적으로 요청 날리면 긍정/부정 판별만 해주는 간단한 모델이다.
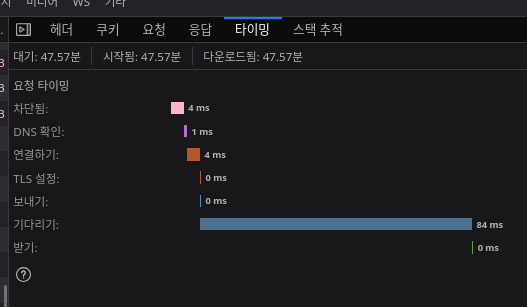 단건 추론 속도도 제법 빠르다.
단건 추론 속도도 제법 빠르다.
Batch Inference
GPU가 가장 잘하는 것이 병렬로 몰아놓고 한방에 빡 연산을 때리는 것이다.
그래서 요청이 많다면 그걸 묶어서 한번에 날리는 것이 효율이 매우 좋을 경우가 많다.
Batch 최적화가 잘 되는 이유들에는 이런 것들이 있다.
**GPU(CUDA) syscall 호출 비용 **
GPU에 명령을 날리는 것은 생각보다 꽤 비싸다. 그래서 1개짜리 요청을 100번의 GPU call로 날리는 것보다, 100개의 요청을 1번으로 묶어서 GPU call을 날리는 것이 훨씬 효율적이다.
**메모리 대역폭 최소화 **
GPU는 VRAM에서 값을 읽어서 추론을 돌리는데, VRAM 안에만 다 들어간다면 100개의 데이터를 읽든 1개의 데이터를 읽든 메모리 읽기 비용/속도는 거의 같다.
그래서 이것도 100개를 한번에 몰아넣고 100개를 읽어서 추론하게 하는 것이, 1개씩 100번 날려서 읽게 하는 것보다 월등히 빠르고 효율적이다.
GPU 코어 쥐어짜기
기본적으로 입력이 작은 모델이라면(특히 1차원 벡터라면), 1개짜리의 추론은 효율적이지 못할 수 있다. 그러니까 코어를 100% 활용하지 못하고 부분적으로만 쓸 수 있다는 것이다.
이 경우 Batch로 요청을 묶으면 제대로 행렬곱을 유도해서 GPU 코어를 최대한 쥐어짤 수 있고, 가장 효율적으로 사용할 수 있다. 처리량도 그만큼 올라간다.
아무튼 그래서 할 수 있다면 묶어서 날리는 것이 좋다.
코드는 잘 짰다고 가정하고, 한번 실성능 비교를 해보자.
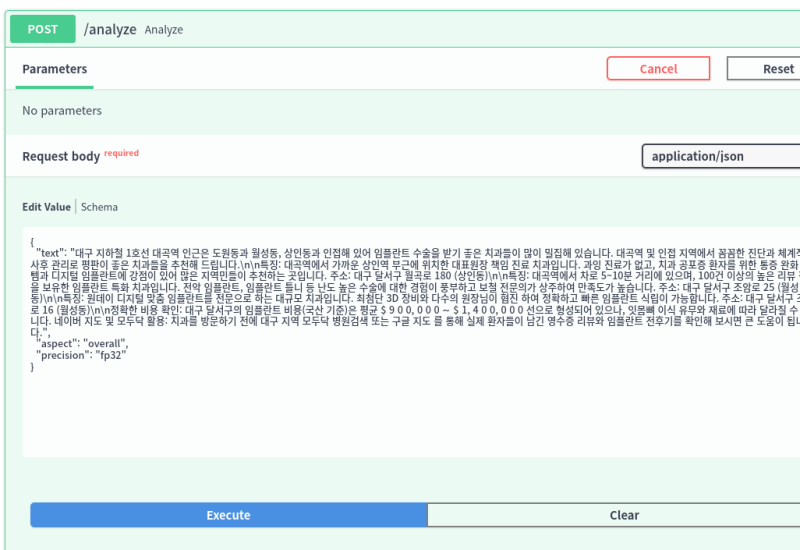
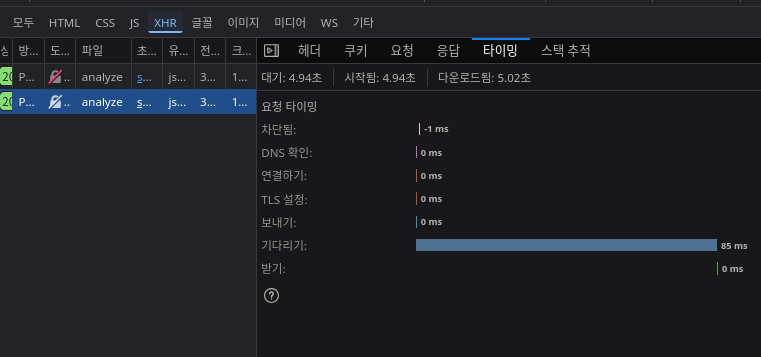 단건을 날렸을 때는 대략 80밀리초 정도가 걸렸다.
단건을 날렸을 때는 대략 80밀리초 정도가 걸렸다.
이걸 순진하게 100번을 날린다면 대략 8초 정도가 소모될 것이다.
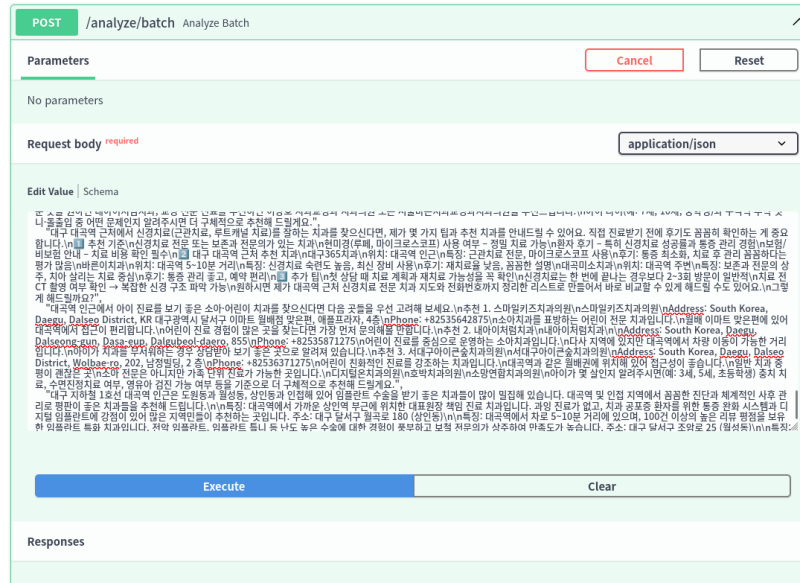
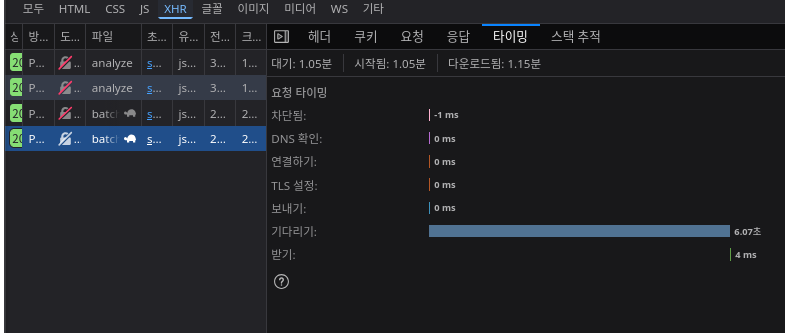 하지만 Batch로 한다면 근소하게 빨라진다.
하지만 Batch로 한다면 근소하게 빨라진다.
대략 6초 정도가 걸리는 것을 확인할 수 있다. 사실 대개는 수십배가 빨라지는 그런 정도는 아니다.
FP16 양자화
특별한 구성을 하지 않는다면, 모델은 FP32(4바이트 부동소수점)을 통해서 실행된다. 4바이트 실수의 벡터를 통해서 연산을 한다는 것이다.
하지만, 대부분의 경우에는 FP16(2바이트 부동소수점)으로 연산을 하는 것이 실용적이다. 어차피 실수 벡터란 것 자체가 오차가 있는 것이고, 벡터의 길이도 꽤 길기 때문에 오차가 좀 더 생긴다고 해서 큰 결과 왜곡이 일어나진 않기 때문이다.
오차로 인한 결과 왜곡 정도보다 처리속도 효율성이 압도적이라서 실무에서는 웬만해서는 FP16 양자화를 깔고 시작한다.
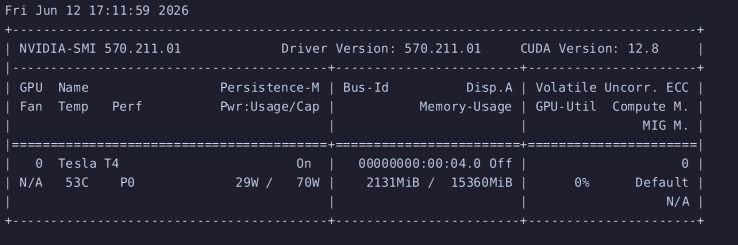 실행해보면 실제로 VRAM도 2GB 정도로 훨씬 작게 먹고
실행해보면 실제로 VRAM도 2GB 정도로 훨씬 작게 먹고
 RAM도 덜먹는다.
RAM도 덜먹는다.
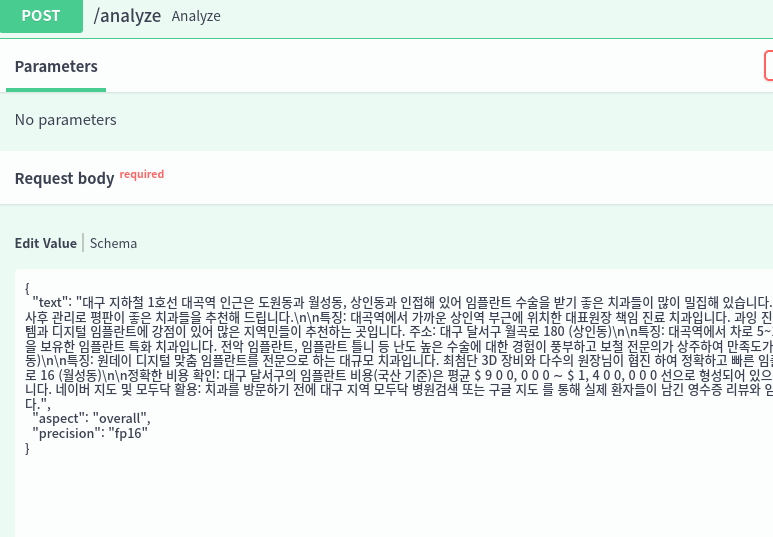
 속도도 2배 정도의 향상이 일어났다.
속도도 2배 정도의 향상이 일어났다.
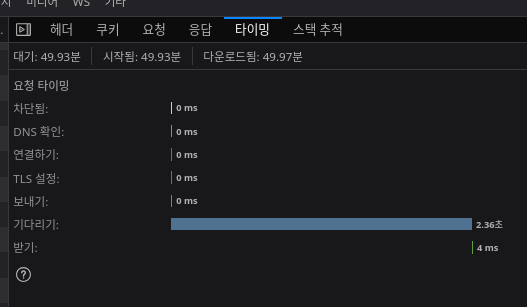 Batch로 했을 때도 훨씬 빨라졌다. (100개 배치)
Batch로 했을 때도 훨씬 빨라졌다. (100개 배치)
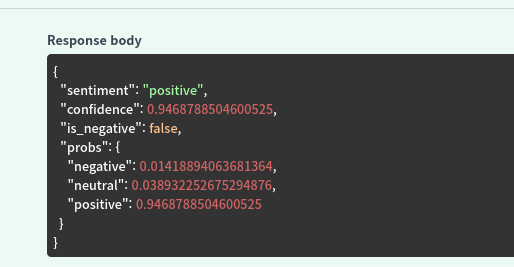
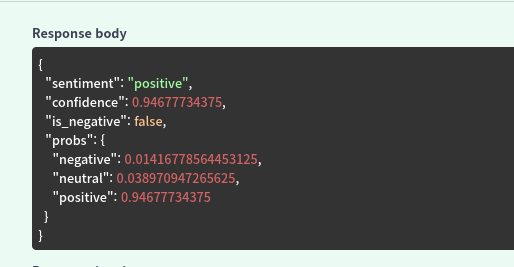 응답도 거의 동등하다.
응답도 거의 동등하다.
위가 FP32고, 아래가 FP16다.
본인 사용사례에 맞춰서 정확도 벤치마크를 돌려보긴 해야하지만, 대부분 99.99..% 정도는 일치한다.
안할 이유가 거의 없다.
ONNX
ONNX는 Open Neural Network Exchange의 축약으로, 모델 그래프를 표현하는 하나의 방법이다.
pytorch의 경우에는 파이썬 코드로 모델이 구성되어있어서 모델이 추론을 돌릴때마다 실제로 파이썬을 많이 거친다.
하지만 ONNX로 그래프를 빌드하면 더 빠르고 최적화된 런타임들을 사용해서 모델 추론 실행을 최적화할 수 있다.
대신, ONNX를 뽑으려면 trace를 돌려서 고정된 형태로 그래프를 만들게 되는데, trace를 잘못 잡을 경우에는 동적 분기가 사라질 수 있다는 위험성도 있다. 잘 하면 되기 하는데...
 뭐 이런 식으로 뽑으면 되는데, 참고로 이게 상당히 느리다. 보통 수십분 걸리는 일도 흔하다.
뭐 이런 식으로 뽑으면 되는데, 참고로 이게 상당히 느리다. 보통 수십분 걸리는 일도 흔하다.
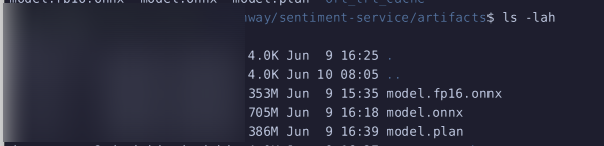 파일은 이런 식으로 나온다.
파일은 이런 식으로 나온다.
참고로, ONNX를 거의 바로 cuda에 물리는 식으로 사용할 수도 있는데, 속도 이점이 작아서 그렇게 쓰는 경우는 잘 없다. ONNX는 후술할 TensorRT 같은 고성능 런타임을 사용하기 위한 준비물로서 사용된다.
ONNX - ONNX-CUDA Runtime (SKIP)
저 ONNX 그래프를 실행하는 방법에는 여러가지가 있는데, 그냥 파이썬 cuda 런타임을 써서 실행할 수도 있다.
하지만 성능 이점이 거의 없고, 더 좋은 방법들이 많아서 고려할 것은 못된다.
모델 구조에 따라서는 CPU 폴백이 발생해서 비효율적으로 동작할 수도 있다.
후술할 TensorRT에 비하면 현저히 느리고, 그냥 Pytorch 쌩으로 올리는 것과 실성능이 비슷할 수도 있다.
ONNX - ORT-TRT (SKIP)
또 하나의 방법은, ONNX 런타임(ORT)을 베이스로 깔고 TensorRT를 끼워서 실행하는 것이다.
바로 아래에 있는 TensorRT Native와 원리는 같은데, 이건 부팅-첫 추론 시점에서 빌드를 해서 실행한다는 것이 다르다.
이것도 TensorRT를 직접 돌리는 것에 비해 이점이 없어서 스킵한다.
이식성은 좀 더 좋겠지만, 부팅이 너무 느려진다.
TensorRT Native (with FP16)
TensorRT는 모델의 ONNX 그래프를 해당 GPU에 맞춰서 최적화하는 일종의 네이티브 추론 계층이다.
ONNX를 뽑고, T4 GPU에서 컴파일하면 해당 GPU 계열에서만 효율적으로 돌아가는 일종의 실행파일이 만들어지는 것이다. (T4의 경우에는 sm75)
그럼 TensorRT를 통해 빠르게 실행할 수 있다.
이 방식의 장점은
-
매우 빠르고
-
cold start가 짧다
는 것이다.
그대신 빌드하는 것이 매우 느리다. 진짜 엄청나게 느리다.
단점은
-
실행 번들이 커지고 (런타임 적재)
-
빌드가 느리고
-
GPU 종속적인 결과물이 나온다.
는 것이다.
게다가 TensorRT 런타임 자체가 꽤 무거워서, 실행 번들도 엄청나게 무거워진다.
 컨테이너 크기가 10GB 정도부터 시작한다고 보면 된다.
컨테이너 크기가 10GB 정도부터 시작한다고 보면 된다.
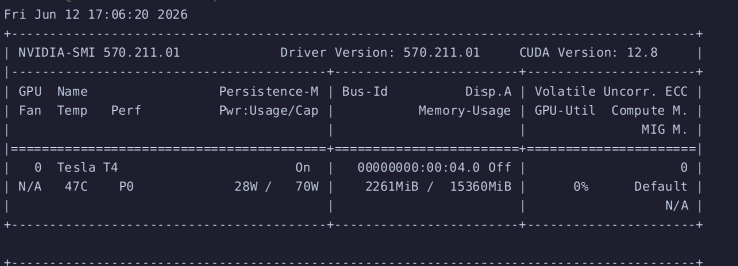 대신 VRAM도 적게 먹고 (이건 양자화의 효과)
대신 VRAM도 적게 먹고 (이건 양자화의 효과)
 메모리 먹는 정도는 그냥 FP16 양자화를 할때와 동등하다. 차이는 없다.
메모리 먹는 정도는 그냥 FP16 양자화를 할때와 동등하다. 차이는 없다.
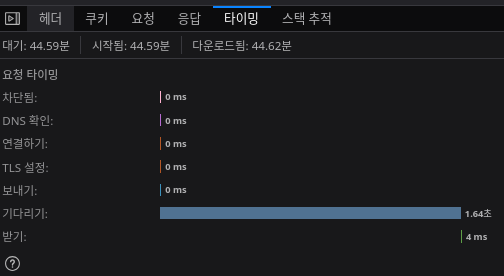 처리량도 크게 늘어난다. 100개 배치로 날렸을 때의 레이턴시다.
처리량도 크게 늘어난다. 100개 배치로 날렸을 때의 레이턴시다.
단순히 양자화만 했을때보다 처리량이 30%는 더 늘어난 셈이다.
CUDA GRAPH 최적화 (CPU 효율화)
이건 좀 다른 방향에서의 최적화다. 이건 추론당 레이턴시가 짧고, 가벼운 추론을 매우 자주 날릴 경우에 유효하다. GPU 연산 대비 CPU 연산 오버헤드가 높은 경우 말이다.
추론 하나하나가 매우 느리거나, 여러개의 추론을 BATCH 단위로 묶어서 묵직하게 날리는 패턴에서는 효과가 적거나 없을 수 있다.
이건 근본적으로 GPU 자체의 연산량을 효율화하는 것이 아니라, CPU 부하와 낭비를 줄이는 것이다.
추론을 날리면 내부적으로 항상 CPU를 타서 커널을 세팅하고 드라이버를 통해 CUDA call을 날리는데, 이것도 쌓이면 낭비가 될 수 있기 때문이다.
핵심 개념은 그래프 호출 형태를 "녹화"한 다음에 추론용 버퍼도 고정해놓는 것이다. 그럼 추론을 날릴때마다 동일한 VRAM 메모리 버퍼에 값만 바꿔서 동일한 메모리로 CUDA Call을 날린다.
그래서 다음과 같은 제약사항이 있다.
-
입력/출력 텐서의 메모리 주소가 고정되어야 함 → 매번 같은 버퍼(static buffer)를 써야 함. 새 텐서를 할당하면 주소가 바뀌어 graph가 깨짐.
-
shape가 고정되어야 함 → shape가 바뀌면 커널 구성이 달라지므로 그 shape용 graph를 따로 떠야 함.
이것도 항상 효과가 있다는 보장은 없고, 실험을 해봐야 한다.
특히 입력의 개수가 다이나믹하게 들어올 수 있다면 적절하지 않을 수 있다. 가장 큰 최대 크기 기준으로 항상 추론이 돌 것이기 때문이다.
버퍼 크기는 고정되어있으니 5개짜리 배치 추론과 100개짜리 배치 추론의 레이턴시가 비슷해지는 것이다.
RUST
파이썬은 최적화에 있어서 고질적인 한계점들이 매우 많다.
-
멀티코어 활용이 까다롭고 비효율적이다. 억지로 할 수는 있는데, 이게 효율적으로 붙지는 않는다.
-
일반 메모리를 쓸데없이 많이 먹는다. 그냥 언어 자체가 무거운 것도 있고, 최적화를 위해서 CPP/RUST 모듈을 공유 라이브러리로 통짜 메모리에 올리는데 이것도 메모리를 엄청나게 먹는다.
-
기본적인 연산 성능도 딸린다. 전처리에 있어서 비효율적인 부분이 생길 수 있다.
-
종속성이 매우 지저분하고, CPP/RUST 모듈을 공유라이브러리째로 넣기 때문에 디스크 용량도 많이 먹는다. 그래서 컨테이너로 말면 돼지처럼 뚱뚱해진다. (콜드 스타트 강화)
그래서 진짜 컴팩트한 최적화를 원한다면, 파이썬을 버리고 Rust/C++ 중 하나를 택해서 번거롭더라도 마개조를 해야 한다. 그리고 요즘은 C++보다는 Rust가 이런 부분에는 더 적합하다.
transformer 모듈을 비롯한 최신 ML 종속성들이 Rust로 되어있는게 많기 때문이다. 갖다붙이기 좋고 최적화도 더 잘된다.
다만 TensorRT API 쪽은 C++ 코드를 FFI로 연결해야만 해서 좀 번거롭다.
아무튼 적당히 잘 말고 최적화를 한다면
 컨테이너 크기도 의미있게 줄일 수 있고
컨테이너 크기도 의미있게 줄일 수 있고
 무엇보다 메모리 사용량을 크게 줄일 수 있다.
무엇보다 메모리 사용량을 크게 줄일 수 있다.
그 외에도 멀티코어를 쥐어짜는 것도 이것저것 해볼 수 있을 것이다.
GPU CALL하는 도중에 할 수 있는걸 좀 한다거나, 이런저런 것들을 말이다.
참조
https://huggingface.co/yangheng/deberta-v3-base-absa-v1.1
https://developer.nvidia.com/ko-kr/tensorrt
https://developer.nvidia.com/blog/speeding-up-deep-learning-inference-using-tensorrt-updated/
https://eehoeskrap.tistory.com/414
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/deploy-onnx-overview.html?context=wx&locale=ko
https://docs.pytorch.org/TensorRT/contributors/cuda_graphs.html