vLLM
 vLLM은 LLM 서빙을 위한 대표적인 최적화 엔진 중 하나다.
vLLM은 LLM 서빙을 위한 대표적인 최적화 엔진 중 하나다.
오픈모델들을 효율적으로 올려서 쓸 수 있게 해준다. 다만 가볍고 작게 올릴 수 있게 해주는 것은 아니다.
vLLM이 어떤 접근법으로 모델을 효율적으로 서빙하는지, 어떻게 쓸 수 있는지 정도를 대략 정리해본다.
기존 모델 서빙 방식의 문제
직접 모델을 받아서 서빙하게 되면 보통 허깅페이스 Transformer 모듈을 가져다가 적당히 파이썬으로 로드하는 경우가 많다.
이 방식은 잘 동작하긴 하지만, 여러모로 비효율적인 부분들이 많다.
-
동시 요청에 대한 GPU 활용률 낮음
-
메모리 낭비 심함
-
Batch 처리의 비효율성 존재
-
그냥 전반적으로 느림
vLLM은 이런 부분들을 좀 최적화해주는 계층이다.
vs Ollama
Ollama도 모델을 서빙할때 기초적인 최적화를 좀 해주긴 한다.
llama.cpp를 사용해서 KV Cache 처리, Batch 최적화를 해주는데, 전반적인 최적화 능력은 vLLM이 더 좋은 편이다.
그래서 성능이나 처리량이 필요하다면 vLLM이 선호된다.
바로 이어서 vLLM이 모델을 최적화하는 법을 정리해보겠다.
KV Cache: PagedAttention
LLM 모델들은 보통 KV 캐시를 통해서 추론 중의 최적화를 많이 가져가는 편이다.
토큰마다 벡터값을 여분의 GPU VRAM에 캐시로 저장하는 것이다.
근데 이게 일반적인 구현체들에서는 메모리 단편화 문제가 있다. 캐시를 넣었다가 빼다보면 중간중간 붕 떠서, 공간이 남아도 넣지 못할 수 있는 것이다.
GC 런타임이나 언어, OS 레벨에서 메모리 할당해제로 단편화가 생기는 것과 문제 원리가 같다.
vLLM은 역시 고전적인 접근법으로 VRAM 단편화 문제를 해소한다.
GPU VRAM을 운영체제의 가상 메모리처럼 페이지 단위로 쪼개놓고, 페이지에 분산해서 캐시값을 저장하는 것이다.
vLLM은 이걸 PagedAttention라고 부른다. 사실 그냥 페이징이라고 불러도 될 것 같긴 한데 아무튼.
이를 통해 저장 효율성을 높인다.
Prefix Caching
Prefix Caching은 말 그대로 프롬프트의 앞부분을 캐싱한다는 것이다.
이게 왜 의미가 있을까?
사실 상당수의 유저들은 프롬프트 지시어를 위에다가 고정해놓고 쓰는 경우가 많다.
이런 식으로 말이다.
[요청 1]
Translate:
Hello world
[요청 2]
Translate:
Good morning
[요청 3]
Translate:
Thank you이런 패턴의 경우에는 Translate:에 대한 벡터 캐시만 쌓아놓고 재사용해도, 쌓이면 꽤 많은 추론비용을 절감할 수 있는 것이다.
대신 vRAM 소비량이 좀 증가한다. 이건 추론이 끝나도 계속 유지하는 반영구 캐시이기 때문이다.
Continuous Batching
vLLM은 Batch 처리에 있어서도 꽤 공격적인 최적화를 해준다.
그냥 적당히 Batch 최적화를 할때는 이런 문제가 있을 수 있다.
보통 A, B, C에 대해 배치 추론을 날리면, 이 배치 추론은 가장 오래 걸리는 추론 단위가 끝날때까지 블럭된다.
다시 말해서, A, B 추론이 끝나더라도, C가 끝나지 않으면 A, B 공간은 놀고 있다는 것이다.
vLLM은 이 부분을 핀포인트로 최적화한다. C가 끝나지 않았더라도, 다 끝나고 놀고 있던 A, B 자리에도 D, E 연산을 바로 우겨넣어서 파이프라인처럼 빠르게 토큰 추론을 돌릴 수 있다.
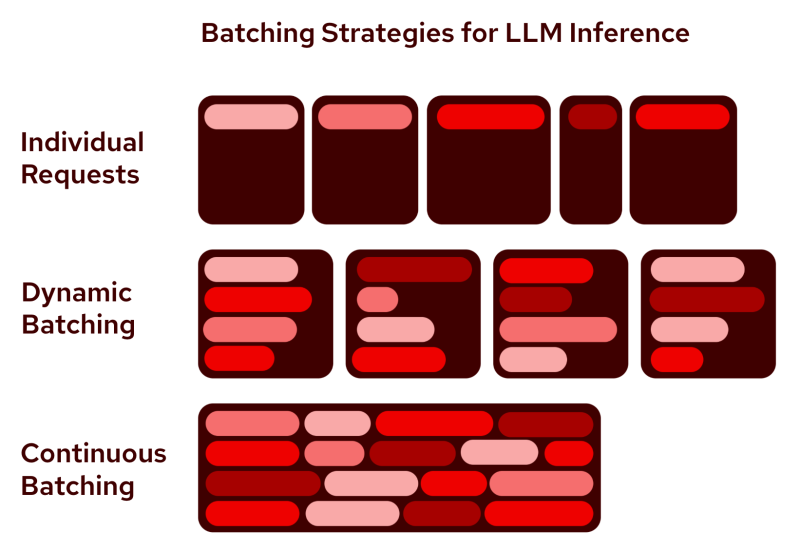 https://www.redhat.com/ko/blog/meet-vllm-faster-more-efficient-llm-inference-and-serving
https://www.redhat.com/ko/blog/meet-vllm-faster-more-efficient-llm-inference-and-serving
vLLM은 이를 통해서 통상적으로 2배, 극단적으로는 5~10배 정도의 처리량 향상을 제공한다.
vLLM이 주목받은 주요 지점 중 하나다.
vLLM의 단점
이게 성능은 좋은데, 세팅도 번거롭고 이슈 포인트도 좀 있다.
우선 GPU마다 호환성 문제가 좀 있다. 특정 모델과 양자화, vLLM의 조합이 어떤 GPU 장비에서는 잘 동작하지 않거나 버그가 많을 수 있다. 이건 잘 체크해봐야 한다.
그리고 위에서 언급했듯이, vRAM은 좀 더 먹을 수 있다. Prefix Cache 같은 적극적 캐시 레이어를 쓰기 때문이다. (물론 끌 수도 있음)
vLLM의 부가기능
OpenAI 호환 프로토콜을 제공한다. 대부분의 도구에 추가적인 어댑터 없이 붙여쓸 수 있다.
Prometheus Metrics도 잘 지원한다. 이를 통해 메트릭을 쌓고 운영 문제를 추적할 수 있다.
Gemma4 굴려보기 (with Docker)
직접 vllm 써서 모델 다운받고 서빙해도 되는데, 대중적인 모델들은 프리셋으로 말아놓은 것들이 있다.
gemma4의 경우에는 허깅페이스 토큰만 있으면 즉시 사용 가능하다.
export HF_TOKEN=hf_*
sudo docker run -d --name gemma4-translate --restart unless-stopped --gpus all --ipc=host --network host --shm-size 16G -e HF_TOKEN=$HF_TOKEN -v ~/.cache/huggingface:/root/.cache/huggingface vllm/vllm-openai:latest --model google/gemma-4-12B-it-qat-w4a16-ct --host 0.0.0.0 --port 8001 --dtype bfloat16 --max-model-len 8192 --gpu-memory-utilization 0.90 --max-num-seqs 2 이건 GPU VRAM을 20GB 정도 먹는다. 내 경우에는 L4로 돌렸는데, 여력이 안된다면 더 작은 모델을 찾다.
이건 GPU VRAM을 20GB 정도 먹는다. 내 경우에는 L4로 돌렸는데, 여력이 안된다면 더 작은 모델을 찾다.
아무튼 실행하면, 약간의 로드타임과 함께 뜰 것이다.
그럼 메모리 잔뜩 먹고
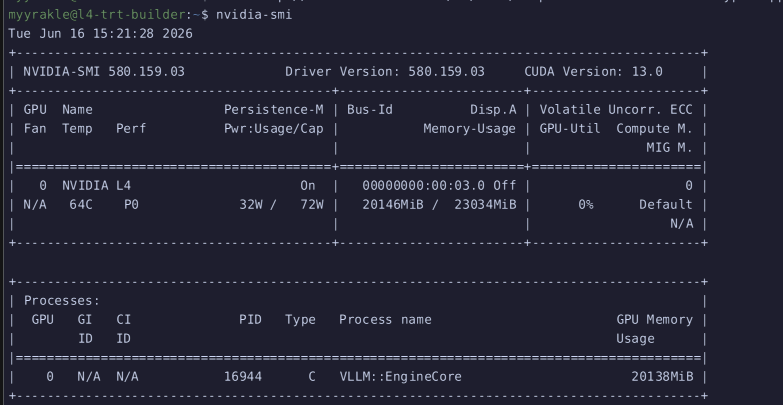
HTTP API를 통해 찔러볼 수 있을 것이다.
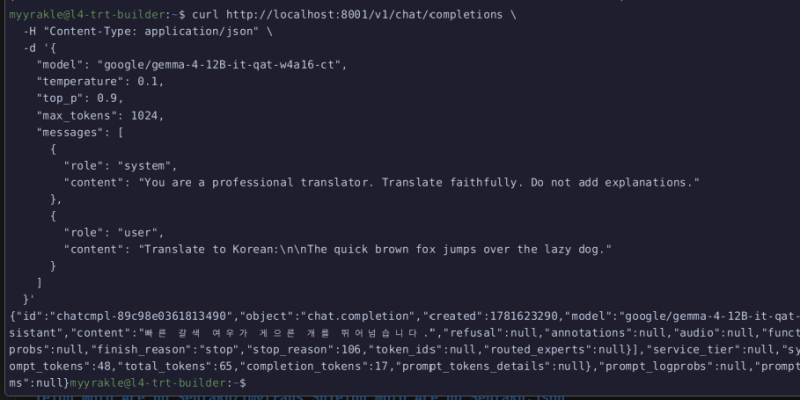 잘 동작한다.
잘 동작한다.
참조
https://github.com/vllm-project/vllm
https://arxiv.org/abs/2309.06180?utm_source=chatgpt.com
https://www.redhat.com/ko/blog/meet-vllm-faster-more-efficient-llm-inference-and-serving
https://docs.vllm.ai/en/stable/design/prefix_caching/
https://docs.vllm.ai/en/stable/design/metrics/